代码还没开源:
详细信息如下:

-
论文地址:https://arxiv.org/abs/2203.11684[1]
-
代码地址:https://github.com/zju-vipa/MEAT-TIL[2]
01
摘要
持续学习是一个长期的研究课题,因为它在处理不断到达的任务中起着至关重要的作用。到目前为止,计算机视觉中持续学习的研究主要局限于卷积神经网络(CNN)。然而,最近有一种趋势是新兴的视觉Transformer(ViTs)逐渐主导计算机视觉领域,这使得基于 CNN 的持续学习落后,因为如果直接应用于 ViTs,它们可能会遭受严重的性能下降。
在本文中,作者研究了 ViT 支持的持续学习,以利用 ViT 的最新进展争取更高的性能。受 CNN 中基于mask的持续学习方法的启发,作者提出了 MEta-ATtention (MEAT),即基于自注意力的注意力,以适应对新任务进行预训练的 ViT,而不会牺牲已学习任务的性能。与以前的基于mask的方法(如 Piggyback)不同,其中所有参数都与相应的mask相关联,而 MEAT 则利用了 ViT 的特性,并且只mask了它的一部分参数。它以更少的开销和更高的准确性使 MEAT 更加高效和有效。
大量实验表明,与最先进的CNN同类模型相比,MEAT 具有显着的优势,准确度绝对提高了 4.0 ∼ 6.0%。
02
Motivation
在开放世界场景中,能够处理不断变化的任务是一个有利的优点。人类擅长将不断出现的任务与先前学到的知识联系起来,从而解决不断出现的任务。然而,如果由于数据偏置任务之间的差异而简单地适应新任务,深度神经网络 (DNN) 通常会遭受灾难性遗忘。
在过去几年中,大量文献致力于解决灾难性遗忘问题,以使 DNN 能够按顺序掌握新到达的任务。现有的持续学习方法可以大致分为三类:重放方法(replay methods),正则化方法(regularization methods)和掩码方法(mask methods)。重放方法重放以前的任务样本,这些样本以原始格式存储或使用生成模型生成,以减轻学习新任务时的遗忘。为了避免存储原始输入、优先考虑隐私和减轻内存需求,正则化方法引入了一个正则化项,以在学习新任务的同时巩固先前的知识。掩码方法为每个任务学习一个掩码,以使预训练的模型适应新任务,以防止任何可能的遗忘。
尽管在计算机视觉方面取得了显着进展,但上述大多数方法都是为 CNN 量身定制的,因为它们在过去十年中在该领域的主导性能。然而,由于更通用的架构(即弥合自然语言处理和计算机视觉之间的架构差距)和 ViT 的卓越性能,CNN 在计算机视觉中的首要地位最近受到视觉Transformer (ViTs) 的挑战。与 ViT 的快速发展相比,先前基于 CNN 的持续学习方法似乎有点过时,因为直接将它们应用于 ViT 并没有充分利用Transformer的特性。
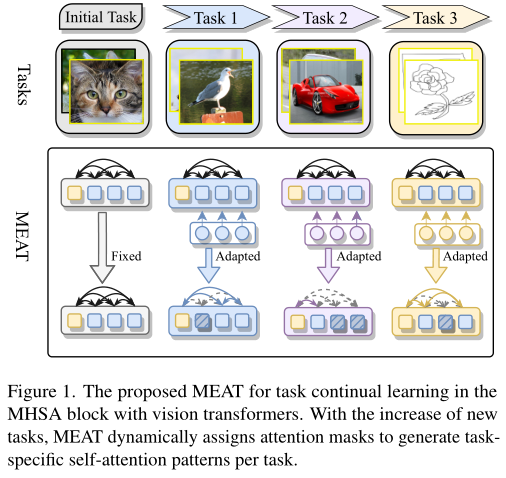
在这项工作中,作者致力于 ViT 支持的持续学习,以跟上 ViT 的进步。
具体来说,作者提出的方法基于掩模方法,主要有以下三个原因:
-
掩码方法实际上为每个任务分配了不同的参数,从而完美地绕过了灾难性的遗忘问题;
-
掩码方法对任务顺序不敏感,这在持续学习中是一个非常有利的优点;
-
掩码方法避免了昂贵的数据存储,并表现出更大的容量来处理更多的任务,这使它们比重放和正则化方法具有突出的优势。
受这些吸引人的优势的启发,作者提出了 ViT 支持的基于掩码的持续学习方法,称为MEta-ATtention (MEAT), 以进一步提高持续学习性能,如上图所示。
MEAT继承了上述所有优点,同时引入了以下与之前的掩码方法不同的创新:
-
MEAT充分利用了 ViT 的架构特性,并将注意力引入到 self-attention(元注意力的来源)机制,这是为基于Transformer的架构量身定制的,使 MEAT 更加有效。
-
先前的方法,如 Piggyback,需要手动设置阈值超参数以对掩码进行二值化。MEAT 采用 Gumbel-softmax 技巧来解决离散掩码值的优化困难,从而减轻了超参数搜索的负担。
-
与先前所有参数都分配给掩码的基于掩码的方法不同,MEAT 仅将掩码引入其部分参数,这使其比先前的方法更高效。
为了验证所提出方法的优越性,在一组不同的图像分类基准和具有各种 ViT 变体上进行了广泛的实验,包括基准比较和消融研究。实验结果表明,MEAT与最先进的 CNN 同类模型相比具有显着的优势,其准确度绝对提高了 4.0 ∼ 6.0%,同时为保存特定任务的掩码而消耗的存储成本要低得多。
本文的贡献如下:
-
作者提出了MEAT,这是第一个 ViT 支持的持续学习方法,以促进 ViT 持续学习的发展。
-
作者在 MEAT 中引入了三项创新,包括mask部分参数、避免手动超参数设置和元注意机制以提高 MEA T 的性能。
-
大量实验表明,MEAT 比其最先进的 CNN 同类模型具有显着优势,同时为保存任务掩码消耗的存储成本要低得多。
03
方法
3.1. Preliminaries
典型的视觉Transformer由三个关键组件组成,即用于嵌入patch特征的可训练线性投影、多头自注意力 (MHSA) 块和前馈网络 (FFN) 块。输入图像被分成 n 个小patch作为图像token,然后映射到一个 d 维向量序列。一个可训练的class token连接到图像token序列以进行最终分类。
输入序列被送到相同编码器层的堆栈中。每个编码器层由一个 MHSA 块和一个 FFN 块组成,并带有残差连接。具体来说,具有 H 头的 MHSA 块可以表示为:
![]()
其中 Q、K 和 V 是查询、键、值嵌入;是注意力头 h 满足 的输出,是输出投影矩阵。注意头 h 由下式计算:
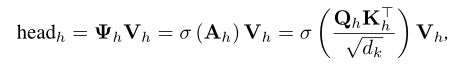
其中,σ(·) 是 softmax 激活函数。
FFN 块由两个线性层和一个激活函数 φ(·)组成,表示如下:
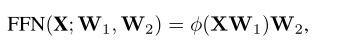
其中是投影矩阵。为简单起见,省略了 MHSA 和 FFN 的bias项。
3.2. Meta-Attention
在 MHSA 块中,每个图像token的输出取决于所有输入token。因此,自注意力机制通常可以被认为是所有图像token对内的密集关系。因此,无论分配的任务如何,最终分类都会涉及同一层中的所有图像token。
在本文中,作者将像这样的token交互模式称为标准token牌交互模式,它在所有图像token牌对之间均匀且密集地执行注意力计算。本文提出的 MEta-ATtention (MEAT) 旨在通过将注意力放在自注意力上来动态地使标准token交互模式适应新任务。
为简单起见并将重点放在图像token交互上,CLS token保持激活状态,仅测量图像token之间的关系。此外,作者还将 MEAT的机制扩展到 FFN 块的训练神经元,探索初始训练权重的合适子网络以提高持续学习性能。
3.2.1 Attention to Self-attention
对于一个初始化好的Transformer作为基础模型,每个图像token在初始旧任务的MHSA块中以标准信息交互形式相互交互。MEAT 动态分配具有连续值的注意力掩码以修改所有图像token之间的标准信息交互,从而在顺序学习新任务时学习自适应交互模式。
具体来说,对于第 i 个输入图像token,掩码 m 的第 i 个条目用于修改该层中与token i 相关的注意力值。因此,MEAT 掩码 m 基于标准信息交互以token方式生成自适应token交互模式。在前向传播中,softmax 函数可以修改为自适应 softmax 函数 用于计算特定任务的注意力,即。然后第 i 行相似度可以写为:
![]()
因此,表示token i 通过注意力掩码 m 对token j 的修改注意力。任务特定关系在修改token交互时提供了任务顺序不变的解决方案:在推理时,每个新任务只使用相应的掩码集和分类器,而不会受到其他任务的干扰。
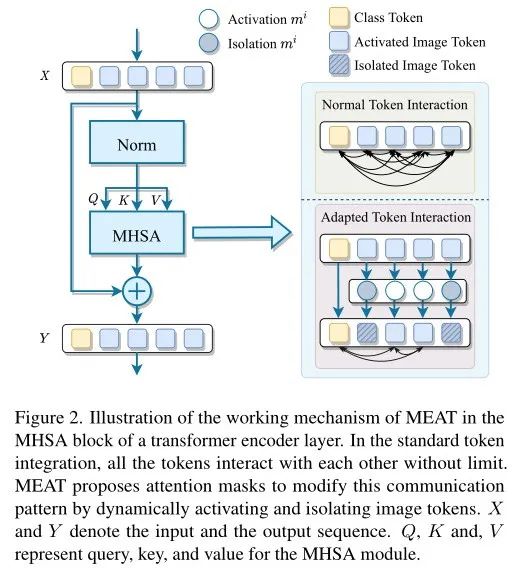
随着传入任务数量的增加,所提出的具有连续值的 MEAT 掩码需要大量的内存空间。如上图所示,采用二进制值 MEAT 掩码代替之前的连续值掩码。具体来说,对于token i,注意力条目修改其适应的注意力状态,其中 1 和 0 表示token i 在适应的token交互模式中是否被激活。使用二值化 MEAT 掩码,可以计算为:
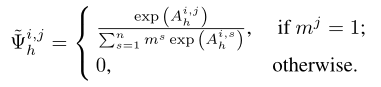
配备注意力掩码,可以根据新任务动态激活图像token。然而,二值化掩码在反向传播时不能直接与新的任务分类器一起优化,因为它属于非微分分类分布,导致 NP-hard 问题。为了获得二元 ,作者因此引入了一个由可训练的参数化的可微变量,然后利用一种新的 Gumbel-Softmax 估计器来近似离散二项式分布,同时启用梯度下降优化为:
![]()
其中 τ > 0 是温度,和从 Gumbel 分布中采样,其中 。的初始权重从分布中独立采样,其中 γ > 0 是超参数。通过采用 Gumbel-Softmax 技巧,所提出的二元掩码可以通过梯度下降与新任务的分类器一起平滑优化。
对于推理,不需要更新权重。松弛过程被替换为:
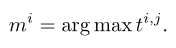
总之,MEAT 通过在增量学习新任务时动态激活和隔离相应的图像token,将特殊设计的注意掩码分配给自注意块,以特定于任务的方式创建适应的token交互模式。二进制值掩码大大减少了额外的开销。初始旧任务的标准token交互是一种特殊适应的token交互模式,每个值始终设置为 1。
3.2.2 Attention To Feed-Forward Network
为了进一步提高任务增量学习的性能,作者通过关注每个神经元来探索初始训练权重的合适子网络,将 MEAT 的机制扩展到 FFN 块的训练神经元。还提出了一种为 FFN 块设计的注意掩码,用于动态激活和隔离 FFN 块中每个线性层中的神经元。训练好的 FFN 块的子网络将根据传入任务的数据偏差自动生成。
令表示在 FFN 块中任意内层的初始旧任务上训练的权重矩阵,其中和分别是输入和输出特征维度。注意,已在初始任务上进行了优化。作者没有为新任务重新训练 ,而是自定义 的激活图以防止灾难性遗忘。与 TI 适配器类似,对于权重矩阵 中的每个神经元,二进制 MEAT 掩码的条目代表其激活状态。在引入新任务时,采用二进制值适配器与相乘为:

在二元适配器的帮助下,可以根据新任务保留或丢弃权重。与 TI 适配器的优化过程类似,Gumbel-Softmax 技巧也被用来解决注意力掩码 m 的非微分问题。
3.3. Optimization Objective
最终的优化目标由两个损失函数组成。第一个是传统的交叉熵损失,其中和是预测的类别分布和真实标签。当孤立的token数量超出正常限制时,孤立的图像token可能会导致准确性下降。因此引入了一个新的 drop-control loss 来防止过多的 patch drop:
![]()
其中 λ 是调整预期激活token数的系数。通过λ调节掩码,避免在早期训练阶段隔离太多图像token,这往往会降低性能。设 α 表示一个权重因子,最终优化目标求和为:
![]()
04
实验
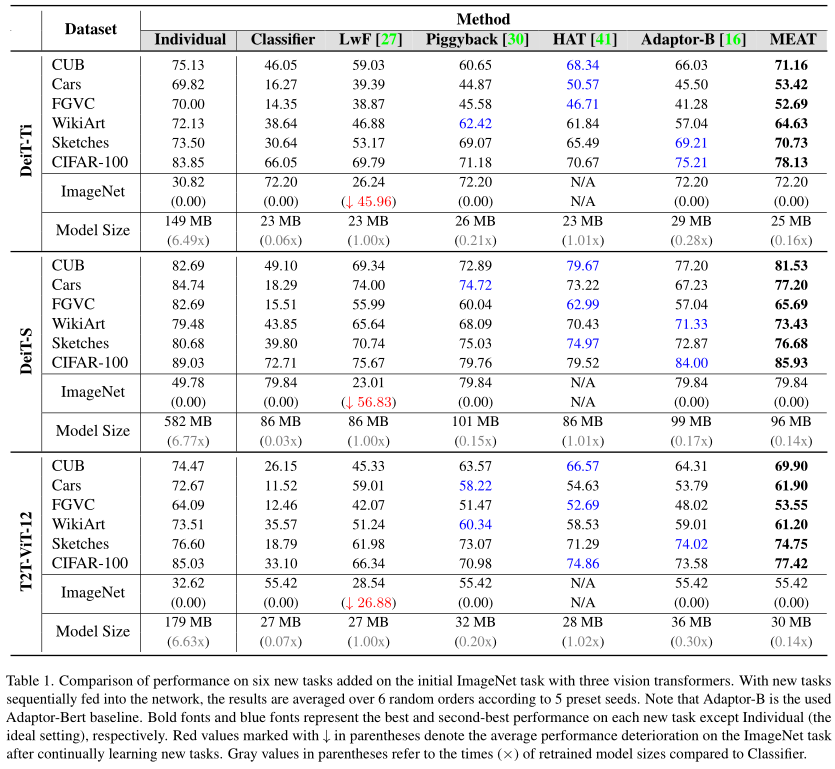
表 1 总结了主要的实验结果。从广义上讲,与除individual之外的所有竞争对手相比,本文的 MEAT 在所有任务上的三个 ViT 都具有卓越的性能。虽然从准确性的角度来看,Individual 是理想的,但它增加了大约 6 倍的模型参数,因为新任务训练了 6 个独立的模型,这实际上违反了持续学习的设置。与持续学习的其他竞争对手相比,MEAT 仅添加和重新训练少量参数(即二进制掩码)。
具体来说,Classifier没有引入很多额外的参数,但结果很差,尤其是在与旧任务有大量域转移的数据上。LwF 和 HAT 需要对模型参数进行整体重新训练,并且存在遗忘问题。与本文提出的方法类似,Piggyback 和 Adaptor-Bert 引入了一些额外的参数(即掩码或层)用于持续学习。
但是,Piggyback 对所有参数应用掩码。Adaptor-Bert 在每个编码器层中应用两个线性层导致过多的额外参数。最后,本文的方法在从初始任务迁移知识、避免灾难性遗忘和节省参数方面取得了很好的平衡。
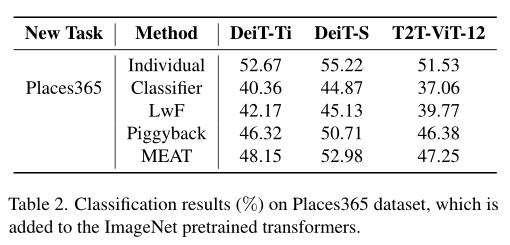
另一个大规模数据集 Places365也作为一项新任务被引入,该任务与初始 ImageNet 任务相比有显着的域转移,如上表所示。实验结果与小型数据集上的结果几乎相同。本文提出的 MEAT 大大提高了性能,同时避免了增加太多的模型参数。
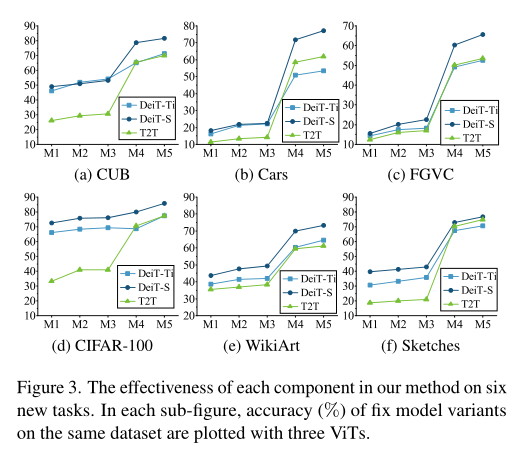
在上图中,作者展示了本文的方法如何从每个设计的组件中受益。具体来说,(M1)Classifier基线;(M2) 在 MHSA 上带有 MEAT 掩码的Transformer,没有drop-control loss ; (M3) 在 MHSA 上带有 MEAT 掩码的Transformer,有drop-control loss ; (M4) 在 FFN 块的神经元上带有 MEAT 掩码的Transformer;(M5) 提出的 MEAT。可以看出,本文方法中采用的每个组成部分都始终如一地促进持续学习表现。

鉴于大多数现有的增量学习工作都基于 CNN,作者在 CIFAR-100 数据集上进行了比较 CNN和视觉Transformer的实验,使用 LwF、Piggyback 和本文提出的 MEA T,如上图所示。由于 MHSA 块仅存在于 ViT 中,因此在使用 CNN 的 MEAT 实验中,作者仅将 MEAT 注意掩码应用于在 ImageNet 上预训练的所有参数。由于没有关于 self-attention 的注意力掩码,MEAT 下的 CNNs 仅比 Piggyback 下的 CNNs 略好一些。
值得注意的是,EfficientNet 是一种出色的网络架构,在 LwF 和 Piggyback 实验中,模型尺寸相对较小,性能优于 DeiT-Ti 和 T2T。然而,使用 MEAT 掩码只能获得与 Piggyback 类似的结果。相比之下,三个 ViT 使用 MEA T 比 LwF 和 Piggyback 表现得更好,因为 MEAT 不仅在部分参数上引入了注意力掩码,而且还为自注意分配了特殊的注意掩码,并为新任务生成了独特的token交互模式。
作者将这种现象归因于本文工作的基本理念:关注自注意力。ViTs 中的自注意力机制在所有图像patch之间建立了密集和长距离的依赖关系。应用 MEAT 掩码为图像token分配不同的注意力值,每个新任务都可以以很少的开销构建独特的token交互模式。然而,CNNs 的 mask 只修改了训练过的神经元的激活状态,缺乏对长距离关系的建模,并且与使用 ViTs 的 MEA T 相比,带来的性能提升更少。

作者在涉及六个数据集和三个采用的 ViT 上可视化了第 2 层和第 11 编码器层的训练二进制掩码。可以观察到,同一token在浅层和深层的激活和隔离状态在数据集和主干之间呈现出明显不同的模式。
首先,所有的 ViT 倾向于在浅层激活更多的图像token,并在所有新任务上随着层的加深隔离更多的token,这是合理的,在浅层隔离太多的token会导致严重的信息丢失。浅层主要隔离输入图像的边缘和背景token,而深层进一步隔离更多的中心token并专注于目标对象区域。

作者还比较了中所有连续任务的平均图像token和训练神经元的激活比率。上图a 中,图像token上的注意掩码倾向于在深层逐渐隔离更多token,这与对可视化结果的观察相匹配。此外,值得注意的是,大模型 DeiT-S 比浅层的两个较小模型激活了更多的图像token,从而有助于获得更好的结果。上图b 给出了 MEAT 掩码在 FFN 神经元上的激活状态。与token掩码类似,深层比浅层更倾向于激活更少的神经元。
05
总结
本文提出了一种新的任务连续学习方法MEAT,该方法是为ViT量身定制的,旨在使预训练好的ViT适应新的任务。MEAT将注意力掩码应用于MHSA中的图像token来为新任务自适应生成唯一的token交互模式。
作者进一步扩展了MEAT机制,以关注神经元,以便在每个任务的FFN块中探索合适的子网络。因此,MEAT充分利用了VIT的架构特征,在自注意上有任务特定的注意力掩码,部分参数没有手动超参数设置。实验结果表明,MEAT有效地提高了持续学习任务的性能,并且参数存储和再训练的开销很小。
参考资料
[1]https://arxiv.org/abs/2203.11684
[2]https://github.com/zju-vipa/meat-til