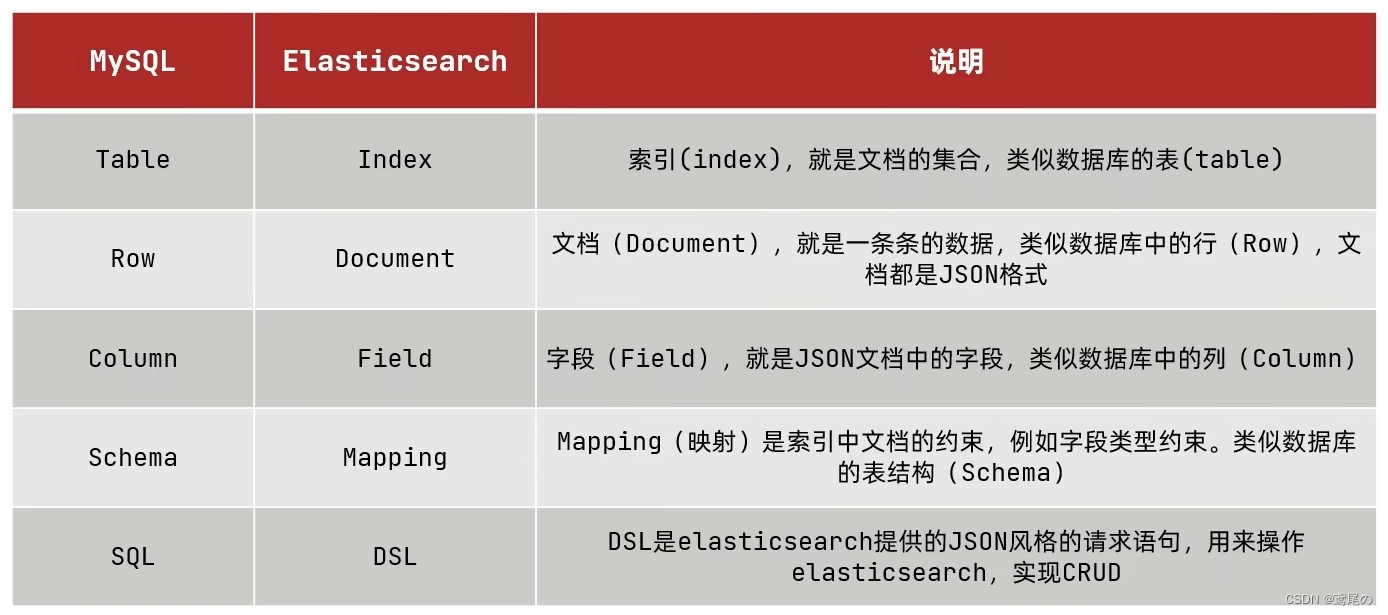
ElasticSearch从入门到精通–第六话(补充篇:Docker启动es、Kibana、IK分词器使用、地理位置、分数查询设置、聚合)
elasticsearch是ELK的核心,负责存储、搜索、分析数据(ELK包含:Elasticsearch、Logstash(数据抓取)、Kibana(数据可视化))
es底层是Lucene实现,Lucene是一个Java语言的搜索引擎类库,优势:
- 易扩展
- 高性能(
基于倒排索引)
es优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任意语言调用
倒排索引
以词条和文档id对应起来,形成反向索引

查询数据时,会先将关键词用分词器进行拆分,然后将拆分的多个词条,依次在倒排表中查询对应的文档id,再拿着id查询
ES核心
索引
- 索引:相同类型的文档的集合
- 映射:索引中文档的字段约束信息,类似表的结构约束
Docker启动单点ES
-
创建docker网络(后面确保es和kibana在同一网络互通)
docker network create es-net -
拉取镜像
docker pull elasticsearch:7.17.7 docker pull kibana:7.17.7 -
启动运行容器
启动es
docker run -d \ --name es \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1-e设置环境变量,discovery.type=single-node,单节点模式启动kibana
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network es-net \ -p 5601:5601 \ kibana:7.12.1
ES分词器
es创建倒排索引时需要对文档分词;但默认的分词规则对中文处理不友好。我们可以在设置分词,执行DSL语句
POST请求至 /_analyze
{
"analyzer": "standard", // 使用默认分词器
"text": "学习es的很多天"
}

可以看到,学习es的很多天,被一个一个字拆分了,对中文分词来讲不太友好。
我们可以使用其他的分词器插件,如IK分词器,使用时需要先将ik的插件包放到es的plugins包下面。
-
先解压
unzip -d ik elasticsearch-analysis-ik-7.12.1.zip,解压至ik文件夹 -
按照上面的docker启动的话,我们需要把ik包放到
es-plugins中# 查看es-plugins数据卷,找到对应的位置为 /var/lib/docker/volumes/es-plugins/_data docker volume inspect es-plugins # 将ik拷贝至es的plugins目录下 cp -r ik/ /var/lib/docker/volumes/es-plugins/_data -
然后重启es容器即可。
# 重启es docker restart es # 查看es日志 docker logs -f es
Ik分词器有两种模式:
- ik_smart: 最少切分
- ik_max_word:最细切分
再次尝试分词
POST请求至 /_analyze
{
"analyzer": "ik_smart",
"text": "学习es的很多天"
}
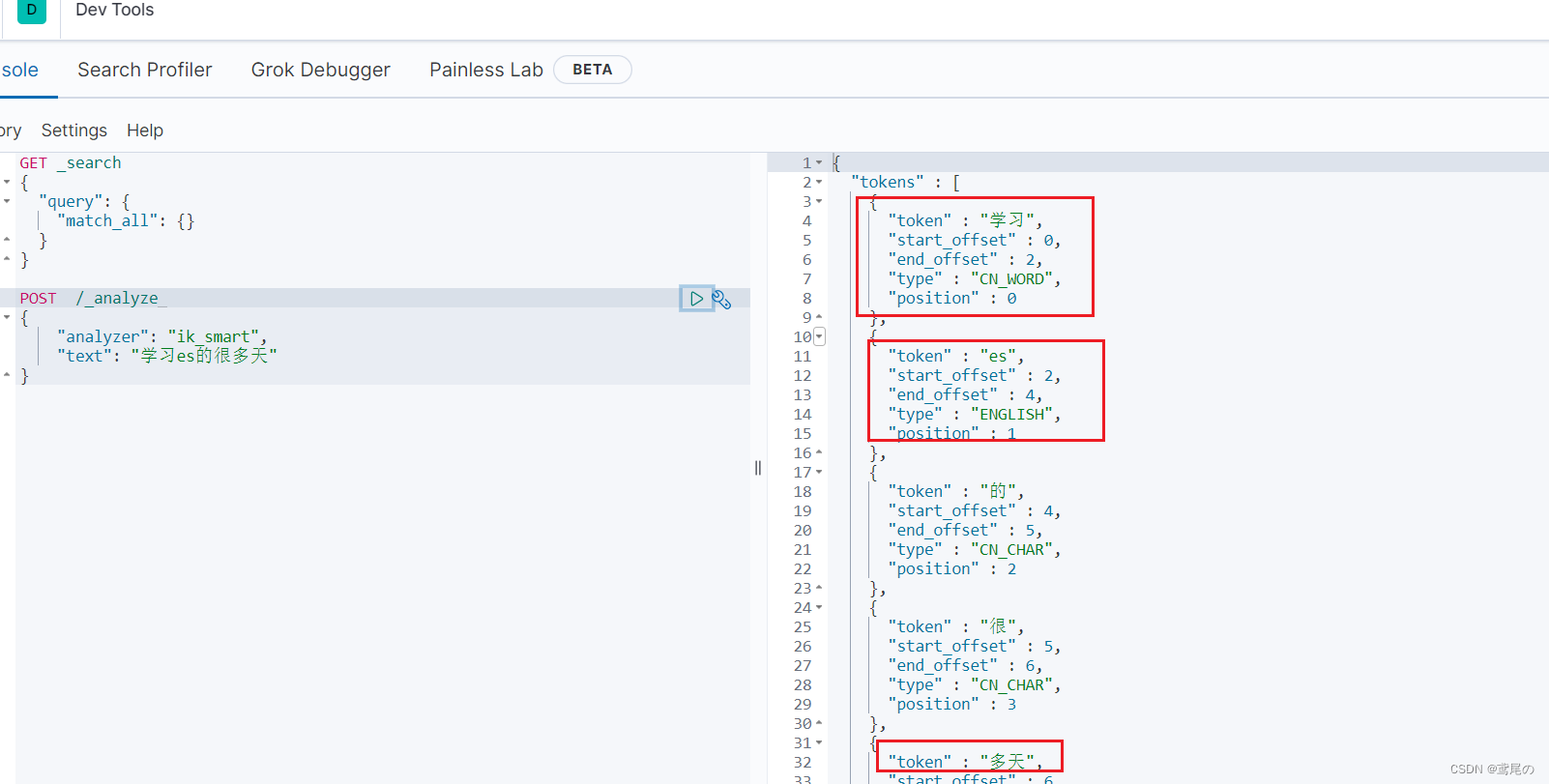
OK,智能切分。再试试ik_max_word
{
"analyzer": "ik_max_word",
"text": "学习es的很多天"
}
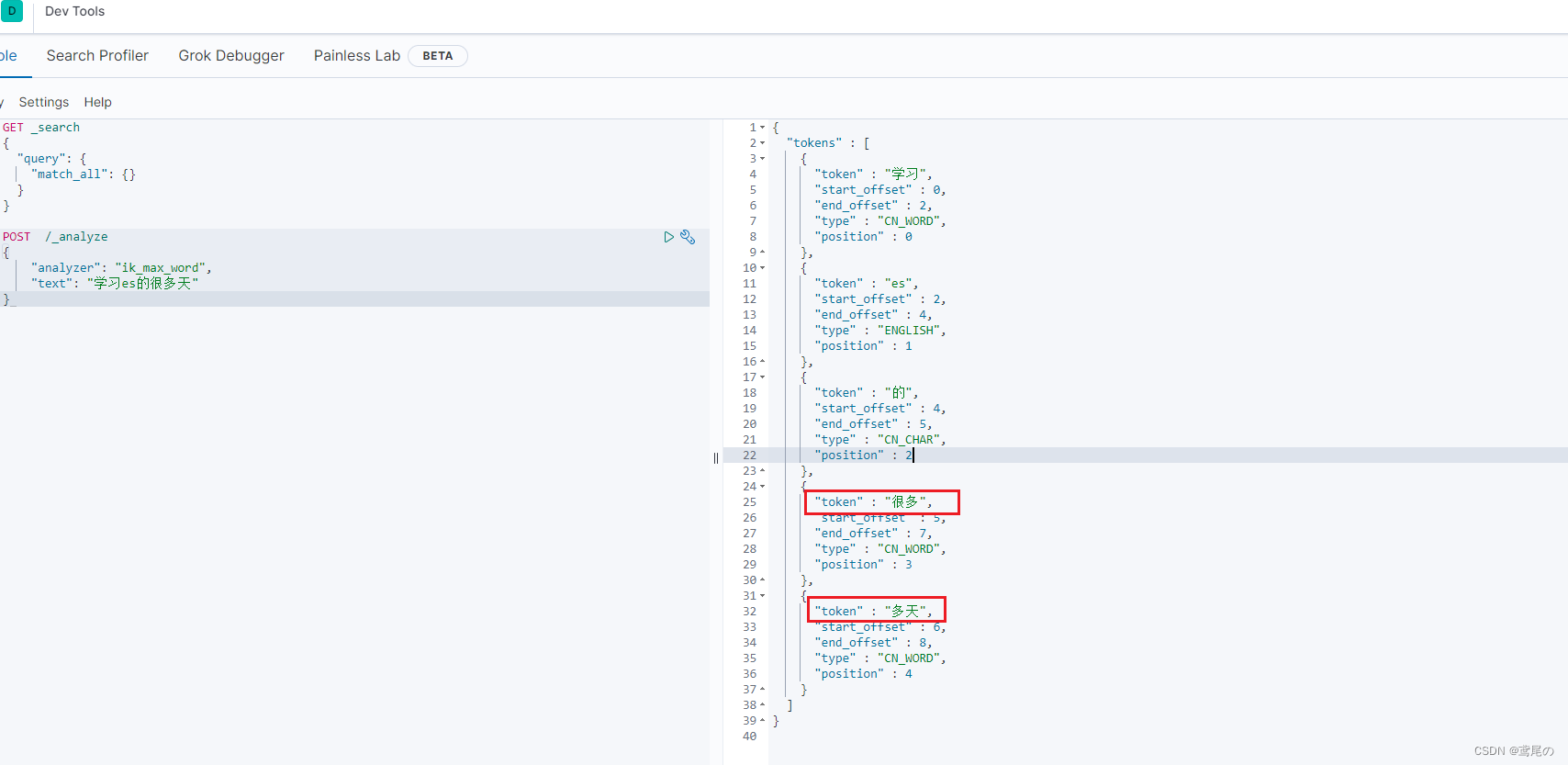
这种模式,会将所有的词细粒度拆分,会产生更多的词条,会占有更多的内存。
IK分词器扩展
像ik分词器分词时会去查询字典,是否是一个词汇。但是像一些网络用语等,字典是没有的,那么我们如何扩展呢?
需要修改ik分词器目录中config/IKAnalyzer.cfg.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
新建ext.dic文件,分别加入要扩展的
ext.dic
白嫖
奥利给
到stopword.dic中加入要剔除的词汇
....
的
哦
了
重启es服务
docker restart es
启动后,再次分词尝试
{
"analyzer": "ik_max_word",
"text": "学习es的很多天,白嫖,奥利给"
}

网络词汇被合成了。
ES mapping

-
在es中没有数组类型,所有字段都可以有多个值,只需要确定数组元素的类型即可,es会自动识别,多个值时在Java中还是用集合接收即可。
-
而且object类型中的字段值,也会被进行索引。
-
index:设置为false时,将不会被加入倒排索引中,无法被索引(一些秘密数据)
-
analyzer:设置使用的分词器
-
properties:设置子字段,如上图的name中的
firstName和lastName
创建索引示例:

索引
索引一旦被创建,是无法进行修改字段和映射的,但是可以添加新的字段
PUT /索引名/_mapping
{
"properties":{
"新字段":{
"type": "integer"
}
}
}
其中es的mapping中有geo_point的类型(一个字符串,存放经纬度信息),查询时可按照地理查询法:
- geo_bounding_box:查询geo_point值在某个矩形范围的所有文档
- geo_distance:查询指定中心点,小于某个距离值的所有文档(附近的人)
GET /indexName/_search
{
"query":{
"geo_distance":{
"distance": "15km",
"FIELD": "经度,纬度值" // 文档中的某个geo_point字段和值
}
}
}
DSL
相关性
当我们查询时,文档结果会根据与搜索磁条的关联度打分(_score),返回结果时按照分值降序排列。
可认为手动设置加分,让其排名靠前,利用function score query
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BEZasz88-1668157785845)(C:/Users/EDZ/Desktop/文档/微服务/imgs/22.png)]](https://img-blog.csdnimg.cn/1c4b11cb42c34edab0c198914497edd0.png)
function score query使用:
- 过滤条件:哪些文档要加分
- 算分函数:使用weight即可
- 加权方式:function score和query score如何进行运算
ES分页
- from+size:深度分页问题,from+size<=10000
- after search:从排序值开始查,能破万,但只能向后查询
- scroll:被淘汰,占用内存,结果非实时
ES高亮
高亮查询,默认情况下,ES搜索的字段,必须要与高亮字段一致
可以将默认的设置为false
{
"query":{
"match":{
"all":"哈哈"
}
},
"highlight":{
"fields":{
"name":{
"require_field_match": "false"
}
}
}
}
地理位置原生API
request.source().sort(SortBuilders
.geoDistanceSort("location", new GeoPoint("31.21, 121.5"))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS)
);

指定排名打分
SearchRequest request = new SearchRequest("user");
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(
// 原始查询
QueryBuilders.matchQuery("all", "a")
// function score数组
, new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD", true), // 字段isAD为true的,需要加分
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQueryBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
聚合

-
桶

request.source().size(0); // 不返回任何source文档 request.source().aggregation(AggregationBuilders .terms("title_agg") .field("title") .size(20)); -
管道

聚合结果解析
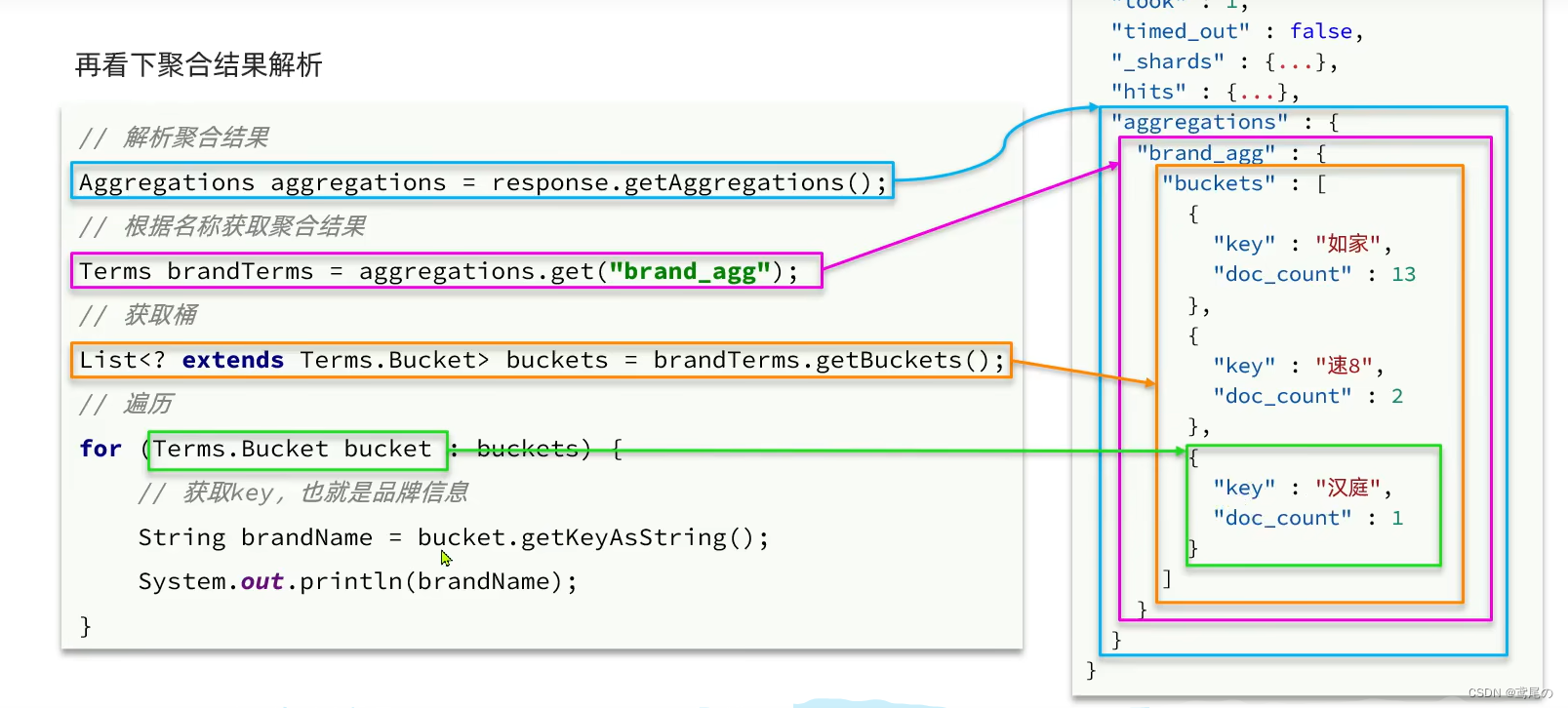
request.source().aggregation(AggregationBuilders
.terms("title_agg")
.field("title")
.size(20));
Aggregations aggregations = response.getAggregations();
Terms titleAgg = aggregations.get("title_agg");
List<? extends Terms.Bucket> buckets = titleAgg.getBuckets();
for (Terms.Bucket bucket : buckets) {
// 获取Key,也就是title字段
System.out.println(bucket.getKeyAsString());
}
多聚合条件
request.source().aggregation(AggregationBuilders
.terms("title_agg")
.field("title")
.size(20));
request.source().aggregation(AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20));
request.source().aggregation(AggregationBuilders
.terms("xxx_agg")
.field("xxx")
.size(20));
带过滤条件的聚合
// 添加查询条件
request.source().query(QueryBuilders.termQuery("title", "a"));
// 添加聚合
request.source().aggregation(AggregationBuilders
.terms("title_agg")
.field("title")
.size(20));