本博客系博主根据个人理解所写,非逐字逐句翻译,预知详情,请参阅论文原文。
论文标题:Embracing Domain Differences in Fake News: Cross-domain Fake News Detection using Multimodal Data;
作者:Amila Silva, Ling Luo, Shanika Karunasekera, Christopher Leckie;
School of Computing and Information Systems
The University of Melbourne
Parkville, Victoria, Australia
发表地点:AAAI 2021;
论文下载链接:https://arxiv.org/abs/2102.06314
代码链接:https://github.com/amilasilva92/cross-domain-fake-news-detection-aaai2021
摘要
随着社交媒体的发展,虚假新闻(fake news)已经成了一个重要的社会问题,使用人工调查的方式很难及时解决该问题。
因此出现了大量的针对自动虚假信息检测的研究。大多数方法借助多个模态的数据(比如,文本,图像,传播网络)来训练监督的模型。然而,这些方法在面对不同领域(比如,政治,娱乐)的新闻时会出现明显的性能下降,尤其是针对训练集中没有见过或者出现较少的领域(unseen or rarely-seen domains)。
本文作者首先展示了不同领域的新闻拥有显著的用词和传播模式上的区别。进一步,对于大量的无标注的新闻,选择哪些无标注的新闻进行人工标注能够最大程度地覆盖多个领域也是很难地。
因此本文首先提出了一个框架能够同时学习领域特定(domain-specific)和跨领域(cross-domain)的知识,用于检测来自不同领域的新闻的真假。同时本文介绍了一种无监督的技术能够选择一些的无监督新闻去做人工标注,这些选择的新闻能够花费最小的标注代价,得到更好的跨领域的新闻检测性能。
本文的实验证明所提出的虚假新闻检测模型以及选择无标注数据的方法能够获得SOTA性能,针对跨领域的新闻检测问题。对新闻数据集中很少出现的领域展现出了显著的性能提升(虚假新闻检测能力)。
本文动机及现有方法的问题
- 由于虚假新闻而产生的花费和伤害日益增大,对其的早期检测和阻止其传播非常重要。且每天产生的虚假信息非常多,人工查验几乎是不可能的。因此需要自动的虚假新闻检测方法。
- 现有方法对于real-world的新闻流处理不够好,有两个原因。 一方面是现有方法大多都是在单领域的新闻数据集上进行训练的(比如数据集politifact是政治领域,gossipcop是娱乐领域)。而它们在面对实际上的多个领域中的新闻时性能下降。
- 针对上述问题,一些方法尝试忽视特定领域的新闻特征,而只关注跨领域的新闻特征,来实现对不同领域新闻的处理。但是实际上特定领域(domian-specific)的新闻特征对于检测虚假新闻也是很有必要的,不能被忽视。
- 另一方面,现有研究指出,对于训练中没有见过的或者出现较少的领域的新闻,现有检测模型的检测能力很低。如果想要在训练中拥有覆盖更多领域的新闻数据,那么就需要对大量的无标注数据进行人工标注,如何花费最少的标注成本获取更好的跨领域新闻覆盖,是需要研究的问题。
- 现有的多模态虚假新闻检测方法,虽说是利用了文本,图像,社交信息等多个模态的信息,但是模型提取的特征仍然是特定领域新闻的(比如政治新闻,娱乐新闻等),没有考虑不同领域的新闻特征。如下图所示,不同领域的新闻使用的高频词语,以及传播网络的特征都不一样。

本文主要贡献
- 本文提出了一个多模态的虚假新闻检测技术(本文的多模态不单单指文本,图像等,还包括从不同的来源/属性获取的信息),能够同时学习领域特定及跨领域的新闻信息,然后这些信息被用于检测虚假新闻。实验表明本文方法在F1值上超出SOTA方法最多7.55%。
- 本文提出了一个无监督的技术来从大规模数据池中选择一部分新闻,使得所选择的新闻能够覆盖最多的领域。通过使用这样的数据集,本文的模型针对少见领域中的新闻的检测性能的F1值能提高25%。
本文模型及方法
问题定义
R是新闻集合,每一个新闻 r 由 构成,其中
是新闻 r 发布的时间;
是新闻的文本内容;
是新闻 r 在时间
内的传播网络(propagation network)。本文将
设置为一个较低的值,5个小时,以评估本文模型早期检测的性能。
每一个传播网络都是一个有向的属性图(attributed directed garph),包含
,其中节点
代表新闻 r 的原始推文和转发推文,边
代表推文之间的转发关系,
是所有节点的属性集合。
本文包含两个子任务,(1)从新闻集合 R 中选择一部分新闻实例 来打标签,用 B 来限制这部分实例的数目。打标签的过程就是为每一个新闻 r 分配一个二元标签
(1表示假,0表示真)。(2)基于上述有标签的数据
学习一个有效的模型,能够预测无标签的新闻集合
中每一个新闻的标签。这里的
不局限于某一个领域(domain)。
为了实现上述领域多样的数据集,本文将三个不同领域的数据集混合起来构成 R (详见实验部分)。
无监督的领域发现
本文首先用无监督的方法学习新闻的所属领域 f_domain(r),用一个低维的向量表示(这部分其实就是对每一个新闻做领域聚类,确定每一个新闻所属的领域。但是不同于一般的用离散值表示不同聚类簇的方式,比如0,1,2分别代表三个不同的簇,本文用一个向量表示一个领域,这个向量就是 f_domain )。
具体步骤如下面的算法1中1-9行所示。可表述为:
(1)首先对每一个新闻 r 构建一个集合 ,包含 r 的传播网络
中的所有用户,以及 r 的新闻内容
中的所有单词。
(2)针对集合 中的每两个数据,构建一个有权重的边将它们连接起来;
(3)重复上述(1)(2)步,直到所有新闻都处理完成,就得到了最终网络 G。
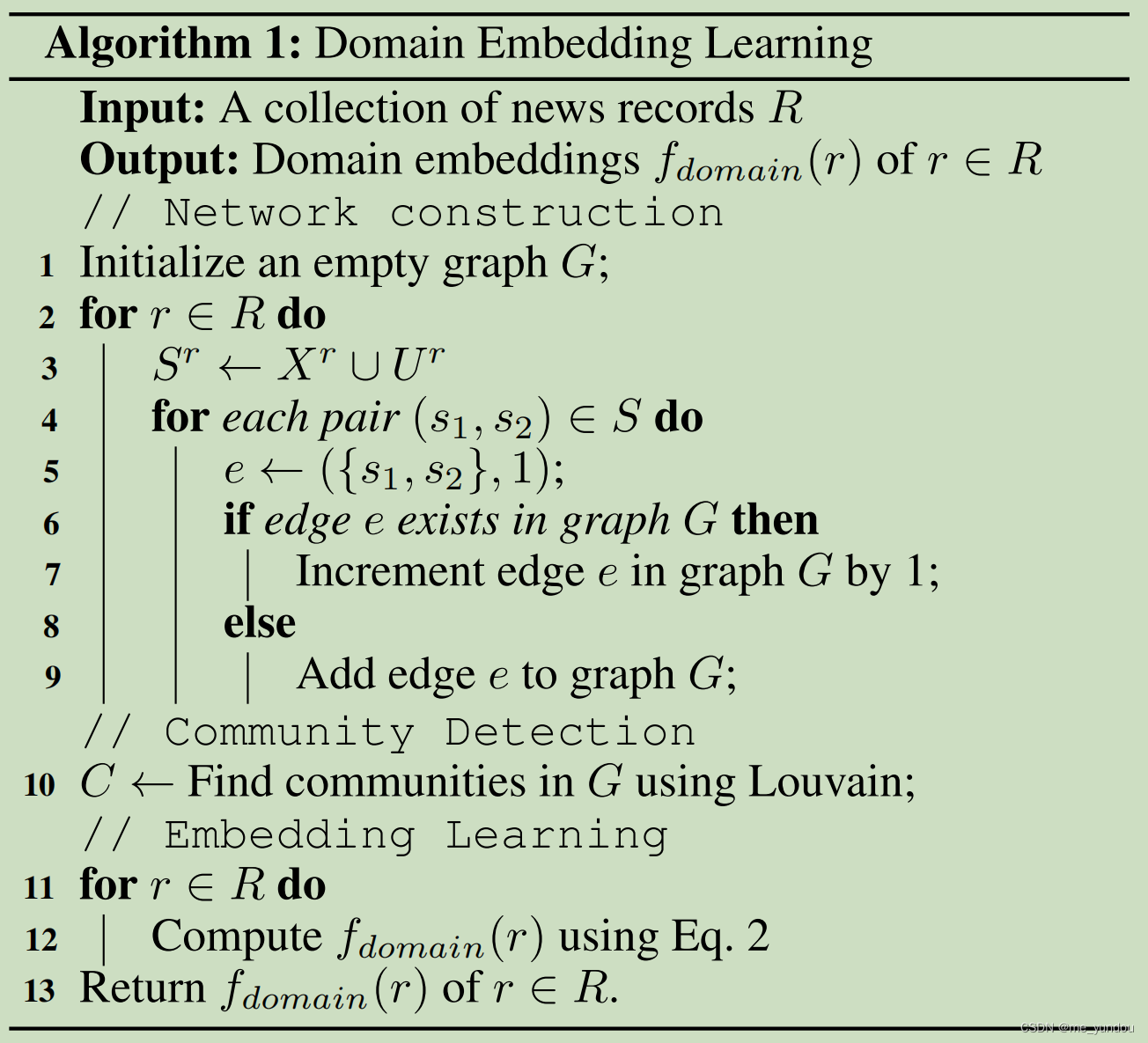
然后本文使用一个不需要参数的社区发现算法, Louvain算法检测网络 G中的社区。然后就得到了G的社区划分C(可以理解为就是对G中所有节点进行聚类,得到若干簇,这个簇的集合是 C),本文认为每一个类别C中的所有节点是属于同一个domain的,而不同类别C下的节点属于不同的domian(这个C相当于一个聚类的伪标签,代表每一个新闻属于哪一个领域)。
得到了每一个新闻的所属domain的伪标签之后,接下来就计算每一个新闻所属domain的低维向量表示了,就是 f_domain(r)。具体过程如下面公式1,2所示。
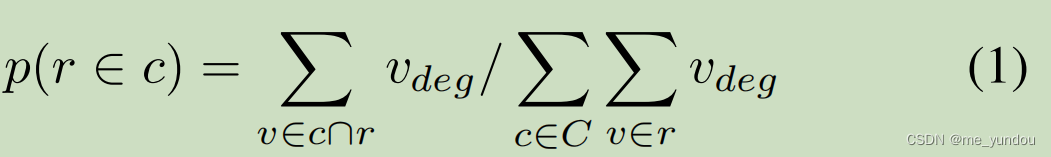
![]()
以前的方法多用单个的离散值表示新闻所属领域,但是一个新闻可能属于多个不同领域,所以本文这种用概低维概率向量表示 f_domain(r) 的方式更好。
领域无关的新闻分类
针对一个新闻 r 的输入表示 f_input(r) (这个表示的获取方法见实验部分),本文的模型分别学习到新闻的领域特定表示 f_specific 和跨领域表示 f_shared,然后从这两个表示中重构出新闻的真假标签和输入表示 f_input(r),这两个重构loss(公式3和4)就作为本文模型总loss的一部分。
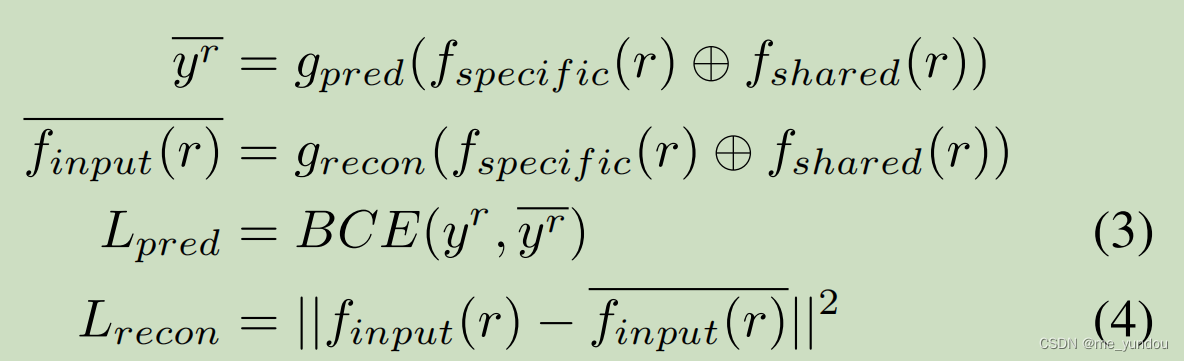
具体而言,新闻的领域特定表示 f_specific 通过下面的公式与上面获取的新闻所属领域 f_domain(r)关联起来。g_specific是一个解码器函数用于重构新闻的所属领域。

另一方面,新闻的跨领域表示 f_shared 通过公式6获取。g_shared是一个解码器函数用于预测新闻的所属领域,同时训练函数 f_shared来欺骗编码器使它无法准确预测出新闻的所属领域(就是GAN的思路,用最大最小对抗训练)。通过这种方式来学习新闻的领域无关特征,也就是跨领域的特征。
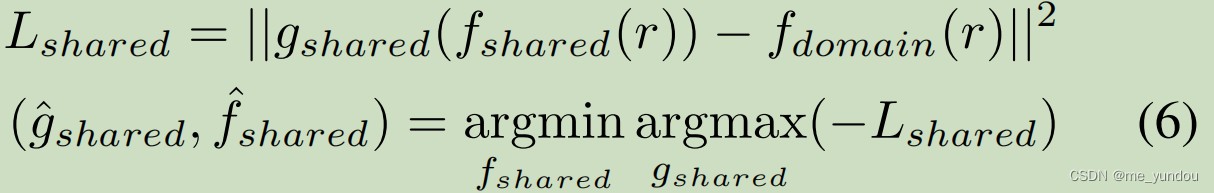
最终,本文的模型的损失函数由上面的4个loss构成:
![]()
基于LSH的实例选择
为了解决对训练集中没有出现过或者出现较少的领域中的新闻的检测性能较低的问题,本文提出一个无监督的技术来选择需要最需要打标签的少量数据,以实现覆盖尽可能多领域的目的。这个技术的最终目标是学习一个模型,能够在这样得到的数据集上对于虚假新闻检测得到最好的效果。
本文首先用新闻所属领域 f_domain(r) 来表示每一个新闻,然后采用局部敏感的哈希(Locality-Sensitive Hashing ,LSH)算法来选择 R中尽可能远的新闻(这个算法这里不详细介绍,感兴趣的同学可以去原文看看)。最终得到满足条件 B 个数目的有标记的新闻集合。
如下图a所示,分别是采用随机方式从数据集中选择样本(Rand-Fake/Real)和采用本文的LSH方式选择样本(LSH-Fake/Real)的结果。可以看出随机的方式对于数据集中少有的领域新闻(politiFact和CoAID)也采样了很少。而本文的方法对这类少见的领域新闻采样出了一个较为均衡的数目。因此本文能够较好处理训练集中unseen和rarely seen领域新闻的问题。
(但是,博主有一个问题!本文所提出的这个LSH的采样方式,可以看作将原始训练集中unseen和rarely seen的领域新闻多采样一点,从而使得采样后的训练集中各种领域的新闻数目均衡。基于这样处理之后的数据训练集,各个领域的新闻数目已经是均衡的了,本文训练他们的模型,这样得到的模型怎么能说是可以处理unseen数据的问题呢?因为作者从数据集设置上规避了unseen问题,实际上训练集已经不存在unseen问题了。)

实验
实验设置
本文模型中每一个新闻的输入表示是通过它的文本内容和传播网络得到的。作者使用RoBERTa-base来学习新闻的文本表示 f_text,然后用一个无监督的网络表征学习技术来学习新闻的传播表示 f_network,最后将这两者拼接得到新闻的输入表示 f_input.
本文所有的编码和解码网络(f_specific, f_shared, g_specific, g_shared, g_pred, g_recon)都是2层的前馈神经网络,激活函数是sigmoid函数。
其他超参数设置见论文原文,这里不再赘述。
数据集
本文将三个不同领域的数据集:(1) PolitiFact; (2) GossipCop; and (3) CoAID,组合成一个跨领域的数据集。然后随机选择75%的数据作为训练集,25%作为测试集。
针对本文的LSH选择算法,从75%的训练集中依据限制 B 来选择有标注的新闻的数目来训练模型。
结果及分析
如下表所示,本文对比了4个纯文本方法(T),两个基于社交信息的方法 (S),三个多模态方法(M)。从中可以看出本文模型的虚假新闻检测能力最好。EANN-Multimoda取得了次好的结果,说明探索领域相关的特征是有效的。EANN也本文的差距在于,前者只用了corss-domain的特征,没有用domain-specific的特征;同时EANN用一种hard的方式表示新闻的domian,而本文使用低维的概率向量表示的,因此本文模型更好。
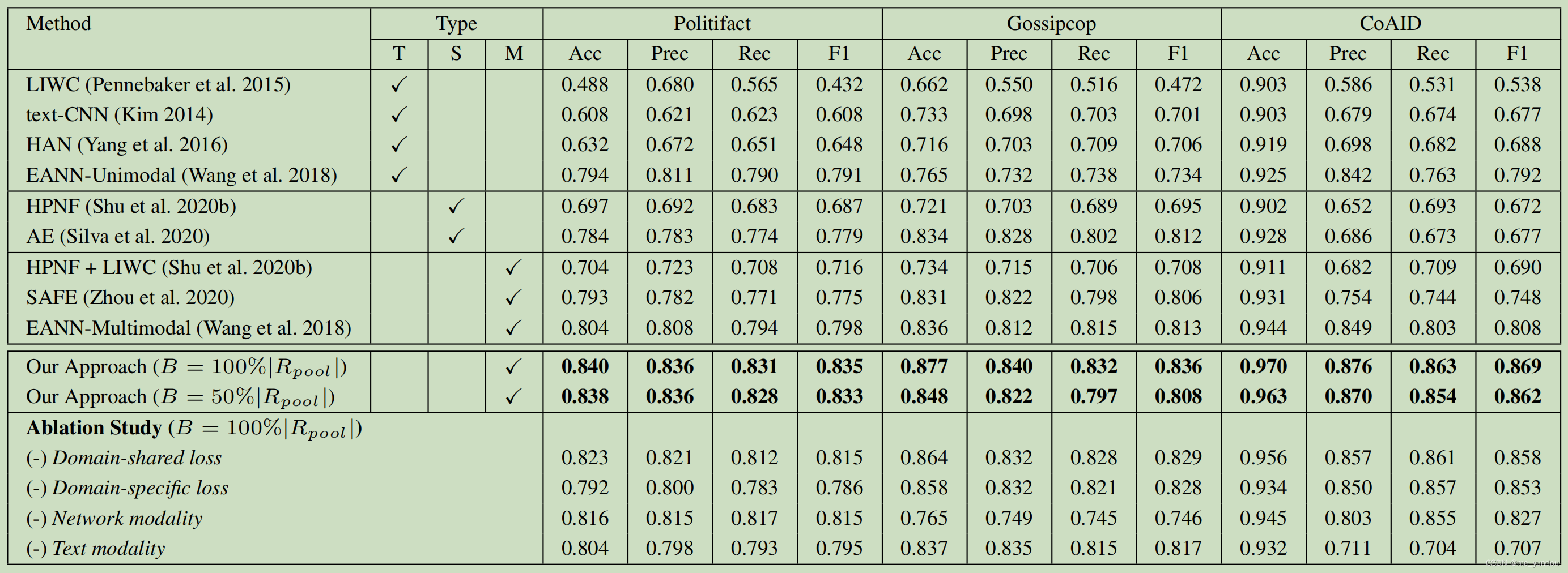
消融实验
结果如上表最后一行所示,可以看出领域特定的特征,以及跨领域的特征都对检测虚假新闻有帮助。而且每一个模态的数据(network modality以及text modality)也都有用。
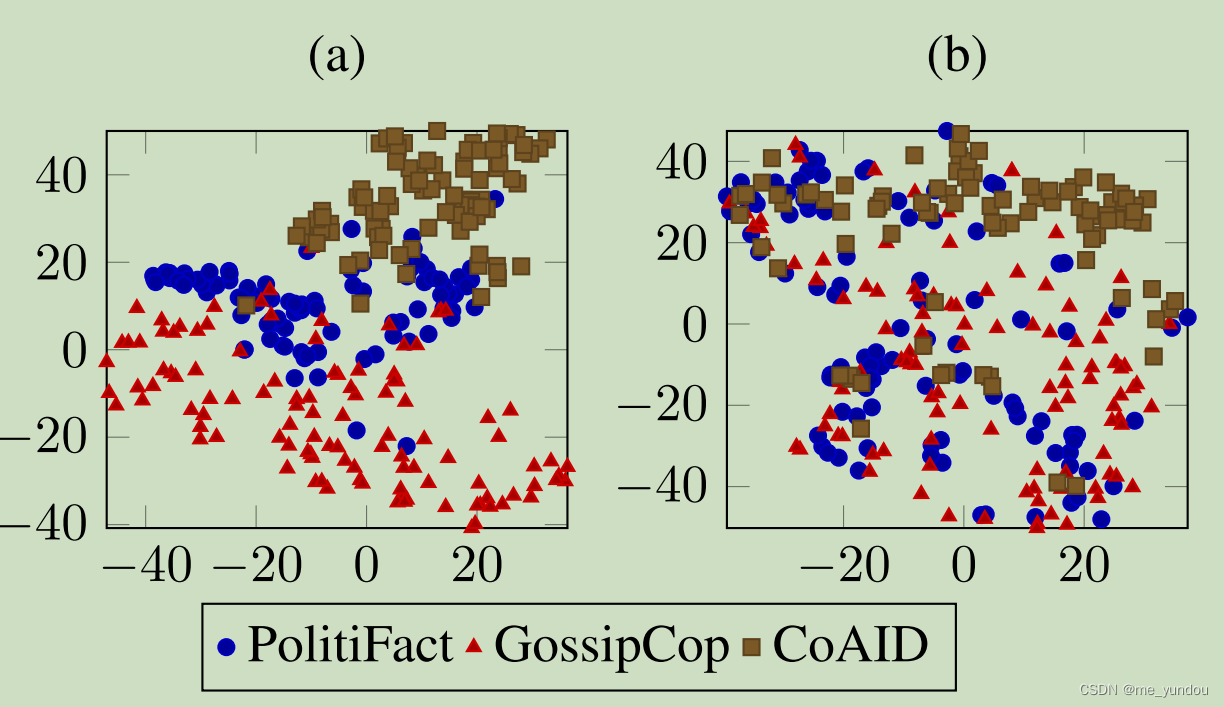
下图a是新闻的domian-specific特征,可以看出该特征反应了新闻的domain信息。而b图是corss-domain特征,就与domian无关了。
总结及展望
本文提出一个新的虚假新闻检测框架,能够探索领域特定以及跨领域的新闻特征。
针对未来的工作,作者后续想做实时在线的虚假新闻检测,针对新闻流处理。这种数据会有更多的领域新闻,带来更多的问题,比如,新出现的未见过的domain,以及实时性问题。另外,如何利用多模态的对齐来弱引导模型的训练过程,也值得探索,也许可以降低打标签的开销。
个人理解及问题
- 关于实验部分,作者不是说将三个不同领域的数据集combine在一起成为一个corss-domain的新数据集了吗?为什么虚假新闻检测的实验结果Acc,F1等值,还是分别在三个数据集上显示的呢?
- 使用LSH的样本选择算法,是将原始数据集中在训练集中unseen或者rarely seen的领域新闻,多采样一些,得到一个新的各领域新闻数目均衡的训练集。基于这种采样后的训练集训练出来的模型,博主认为不能说它解决了unseen问题。