pyAudioKits是基于librosa和其他库的强大Python音频工作流支持。
通过pip安装:
pip install pyAudioKits
pyAudioKits的GitHub地址,如果这个项目帮助到了你,请为它点上一颗star,谢谢你的支持!如果你在使用过程中有任何问题,请在评论区留言或在GitHub上提issue,我将持续对该项目进行维护。
在进行音频信号有关研究时,我们常常需要用到语谱图的分析。同时,我们也需要进行降噪或者有用的频率成分的提取。
常规情况下,为了实现降噪或者有用的频率成分的提取,我们会将整个音频信号通过一个时不变滤波器。如果噪声是平稳信号,该方法可以有效滤除噪声。然而实际情况下,噪声往往是非平稳的,这就意味着我们需要在不同时间点上使用参数不同的滤波器,即使用一个时变滤波器。
短时傅里叶变换可以用于生成音频信号的语谱图,语谱图上包含了信号随时间变化的频率成分信息,因此我们完全可以将时变滤波器的设置和语谱图的分析进行结合。
Filter-Artist基于pyAudioKits开发,实现了一个STFT语谱图定位滤波分析系统,这个系统旨在对音频信号进行短时傅里叶变换。而且,为了更好地对语谱图进行分析,我们让用户可以借助GUI,使用鼠标,在特定时间的特定频点设置巴特沃斯滤波器,交互性地提取自己感兴趣的信号成分、屏蔽噪声,观察滤波后的波形并实时播放滤波后的音频。
该项目的GitHub地址。如果它对你有用,请为它点上一颗star,谢谢!
运行环境:
Python ≥ 3.8.3
依赖:
pyAudioKits ≥ 1.0.6
PyQt5 ≥ 5.15.4
numpy ≥ 1.22.4
opencv-python ≥ 4.5.2.52
-
在命令行输入:
python main.py以执行
main.py,得到窗口如下图所示。
-
点按Load按钮,并读取预置的录音文件rec2_01.wav。

此时显示了rec2_01.wav的语谱图。

-
可以选用多种窗型来显示语谱图。默认展示的是矩形窗的结果:

使用汉明窗:
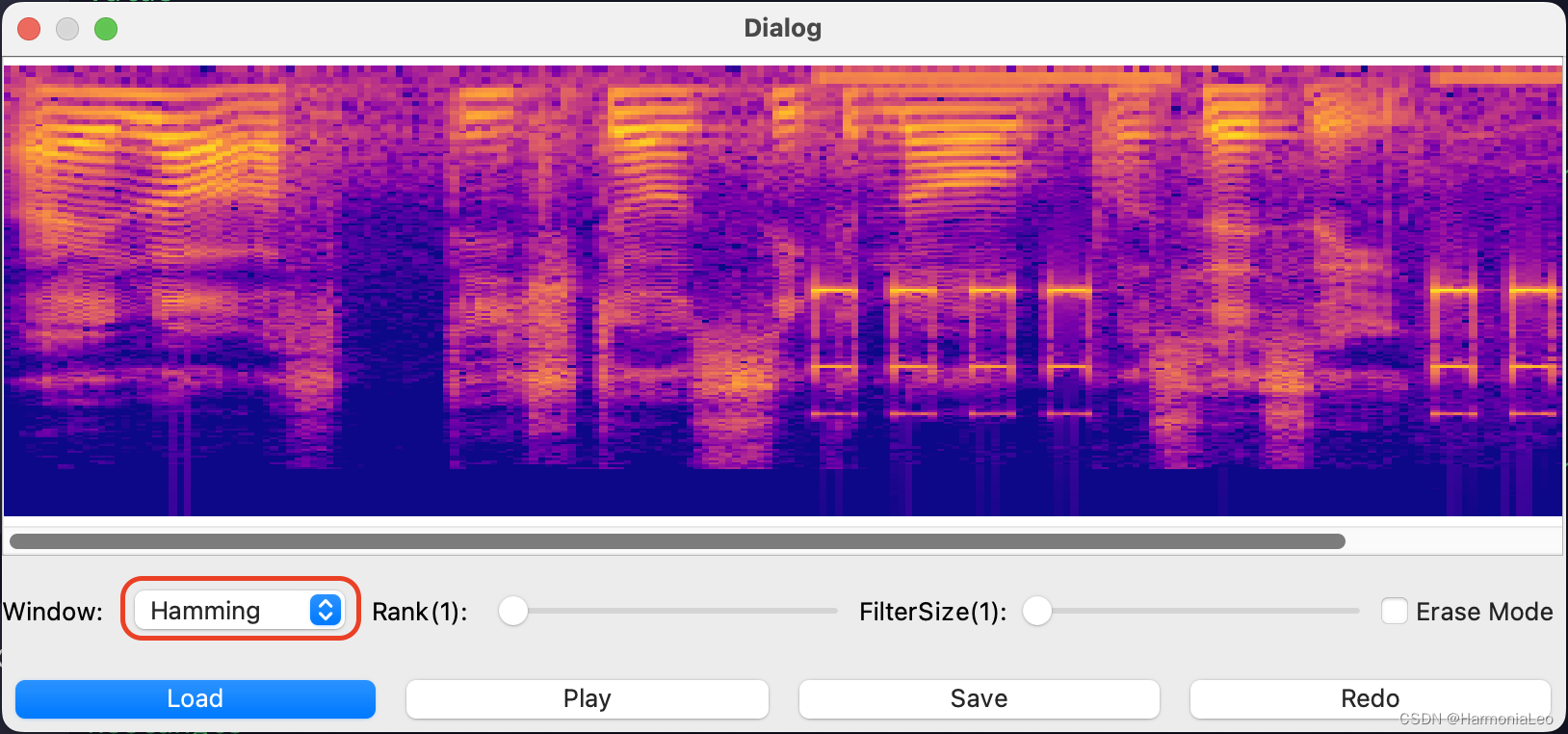
-
可以设置巴特沃斯滤波器的阶数和通带/阻带宽度。
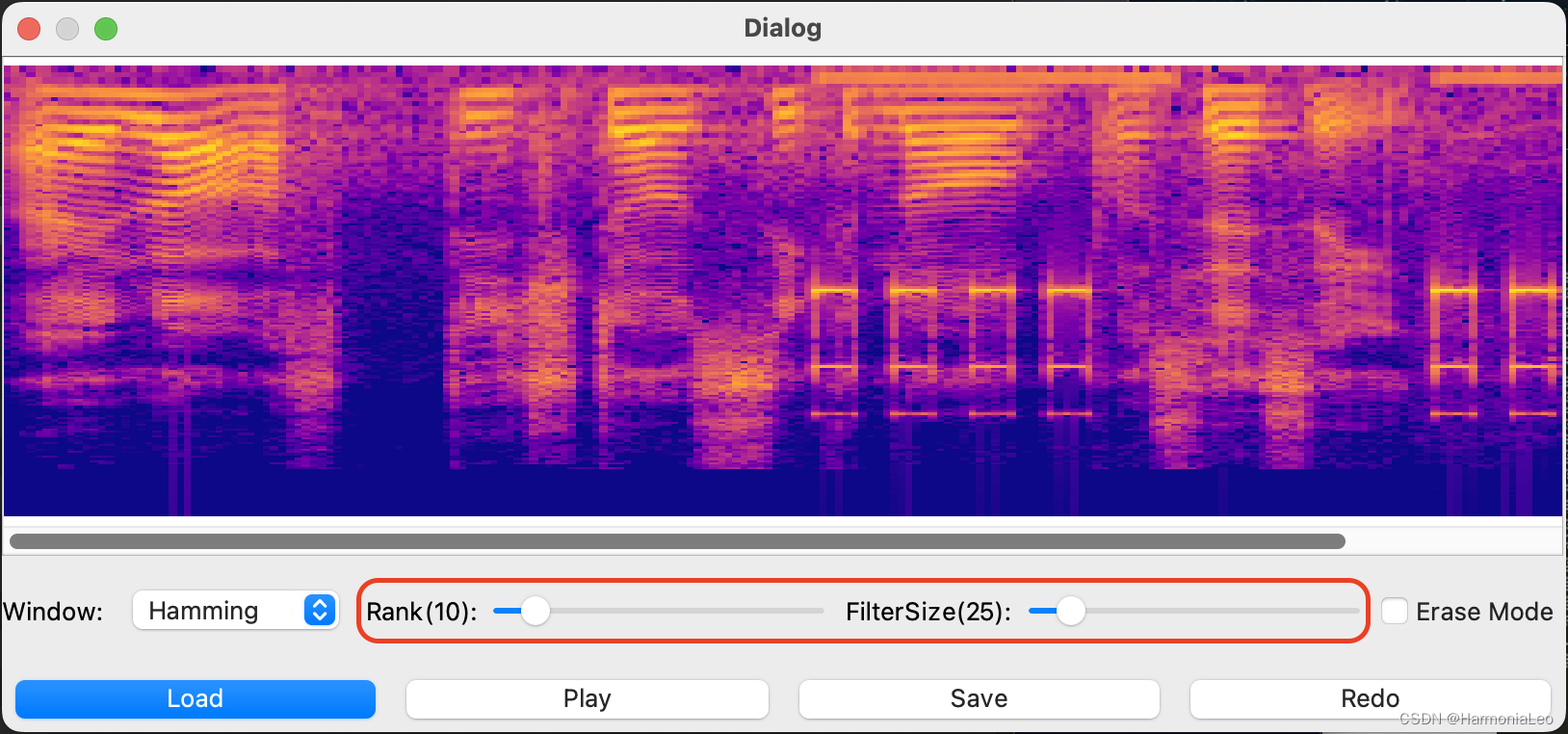
-
不勾选Erase Mode的情况下,设置的是带通滤波器。在语谱图上点按鼠标并拖动,则鼠标初始位置决定滤波器设置的起始时间和中心频率,鼠标释放位置决定滤波器设置的结束时间。设置一个宽度较大的高频通带以提取蜂鸣器音。
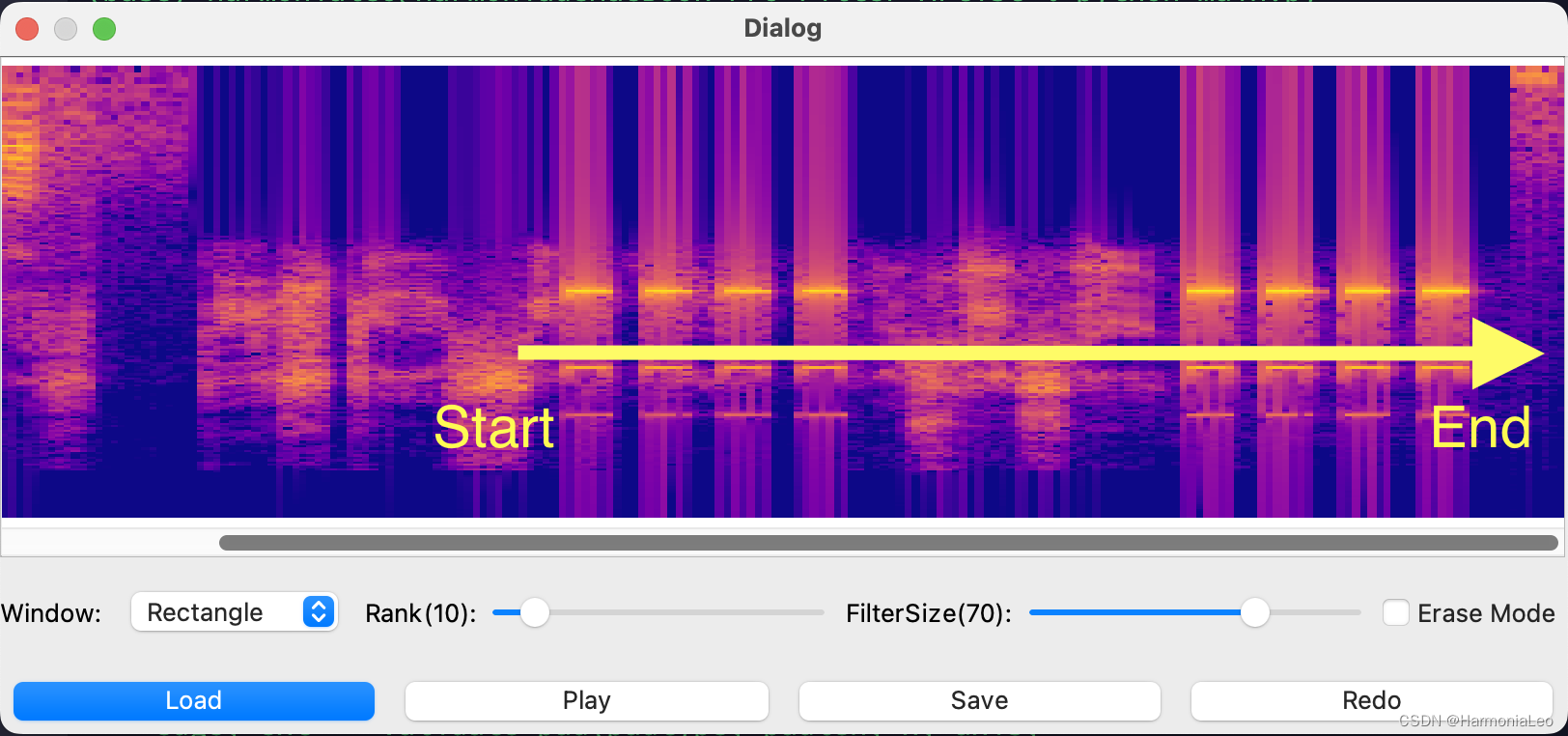
-
勾选Erase Mode的情况下,设置的是带阻滤波器。在语谱图上点按鼠标并拖动,则鼠标初始位置决定滤波器设置的起始时间和中心频率,鼠标释放位置决定滤波器设置的结束时间。设置三个宽度较小的阻带以消除蜂鸣器音。

-
点击play按钮播放音频。

-
点击Save按钮对音频进行保存。

-
点击Redo按钮重置对音频的编辑。

核心代码:
核心代码位于audio.py文件内
from pyAudioKits.audio import read_Audio
from pyAudioKits.analyse import FFT
from pyAudioKits.filters import lowPassButterN, highPassButterN, bandPassButterN, bandStopButterN
import matplotlib.pyplot as plt
import numpy as np
class myspectrogram:
def __init__(self,direction,window):
self.__wav = read_Audio(direction) #利用pyAudioKits的api读取音频
self.__M=0.03 #设置窗长为0.03s
self.__R=0.015 #设置步长为0.015s
if window=="Hamming":
self.__Window = "hamming"
elif window=="Rectangle":
self.__Window = None
def __stft(self):
self.__freq = FFT(self.__wav.framing(self.__M, 1 - self.__R/self.__M, self.__Window)) #利用pyAudioKits的api进行短时傅里叶变换
def save(self,direction):
self.__wav.save(direction) #利用pyAudioKits的api保存音频
def play(self):
self.__wav.sound() #利用pyAudioKits的api播放音频
def drawFreq(self):
self.__stft()
#创建子图,并取消横纵坐标
plt.figure(figsize=(8,2))
plt.axis('off')
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0, hspace = 0, wspace = 0)
plt.margins(0,0)
self.__freq.plot(ax=plt.gca(),cbar=False,freq_scale="mel",plot_type="dB") #将子图传入pyAudioKits的频谱绘制api
plt.savefig("tmp.png") #保存子图,后续通过PyQt读取并显示
def filtering(self,n,sizeFreq,erase,xposeStart,yposeStart,xposeEnd,yposeEnd):
def freq_transform(freq): #将鼠标在频谱上点击的y轴位置,即一个[0,1]之间的数,映射到梅尔尺度频率
sr = self.__wav.sr
length = int(self.__M * sr / 2)
max_freq_point = int(sr / 2)
max_freq = sr / 2
freq_points = 700 * (np.power(10, np.linspace(0, 2595 * np.log10(1 + max_freq/700), length)/2595) - 1)
freq_point = freq_points[int(length * freq)]
freqs = np.linspace(0,max_freq,max_freq_point)
return freqs[int(freq_point)]
#将鼠标在频谱上点击的x轴位置,即一个[0,1]之间的数,映射到音频时间,后续用于音频切片
xsize=self.__R * self.__freq.shape[0]
xposeStart=xsize*xposeStart
xposeEnd=xsize*xposeEnd
yposeNow=float(yposeStart)
width=float(sizeFreq)/200 #将滤波器宽度映射到[0,1]的尺度上
#计算滤波器的两个截止频率
low=yposeNow-width
high=yposeNow+width
#获取滤波器并进行滤波
if erase:
if low>0 and high<1:
filt = lambda x: bandStopButterN(x, n, freq_transform(low), freq_transform(high))
if low<=0:
filt = lambda x: highPassButterN(x, n, freq_transform(high))
if high>=1:
filt = lambda x: lowPassButterN(x, n, freq_transform(low))
else:
if low>0 and high<1:
filt = lambda x: bandPassButterN(x, n, freq_transform(low), freq_transform(high))
if low<=0:
filt = lambda x: lowPassButterN(x, n, freq_transform(high))
if high>=1:
filt = lambda x: highPassButterN(x, n, freq_transform(low))
if xposeStart<xposeEnd:
self.__wav[xposeStart:xposeEnd]=filt(self.__wav[xposeStart:xposeEnd])
if xposeEnd<xposeStart:
self.__wav[xposeEnd:xposeStart]=filt(self.__wav[xposeEnd:xposeStart])