准备接触大数据体系,所以我优先去了解一下Hadoop这个大生态环境,并且去了解这个生态的整体组件内容,都有什么。Apache Hadoop官网,了解到Hadoop是一个开源软件作为可靠,可升级的分布式计算。要了解Hadoop我觉得先去了解其中的组件,了解其对应的组件都有什么,这样方便你有一个大范围的了解,并可以更好的深入了解其中各个内容,并串联起来。
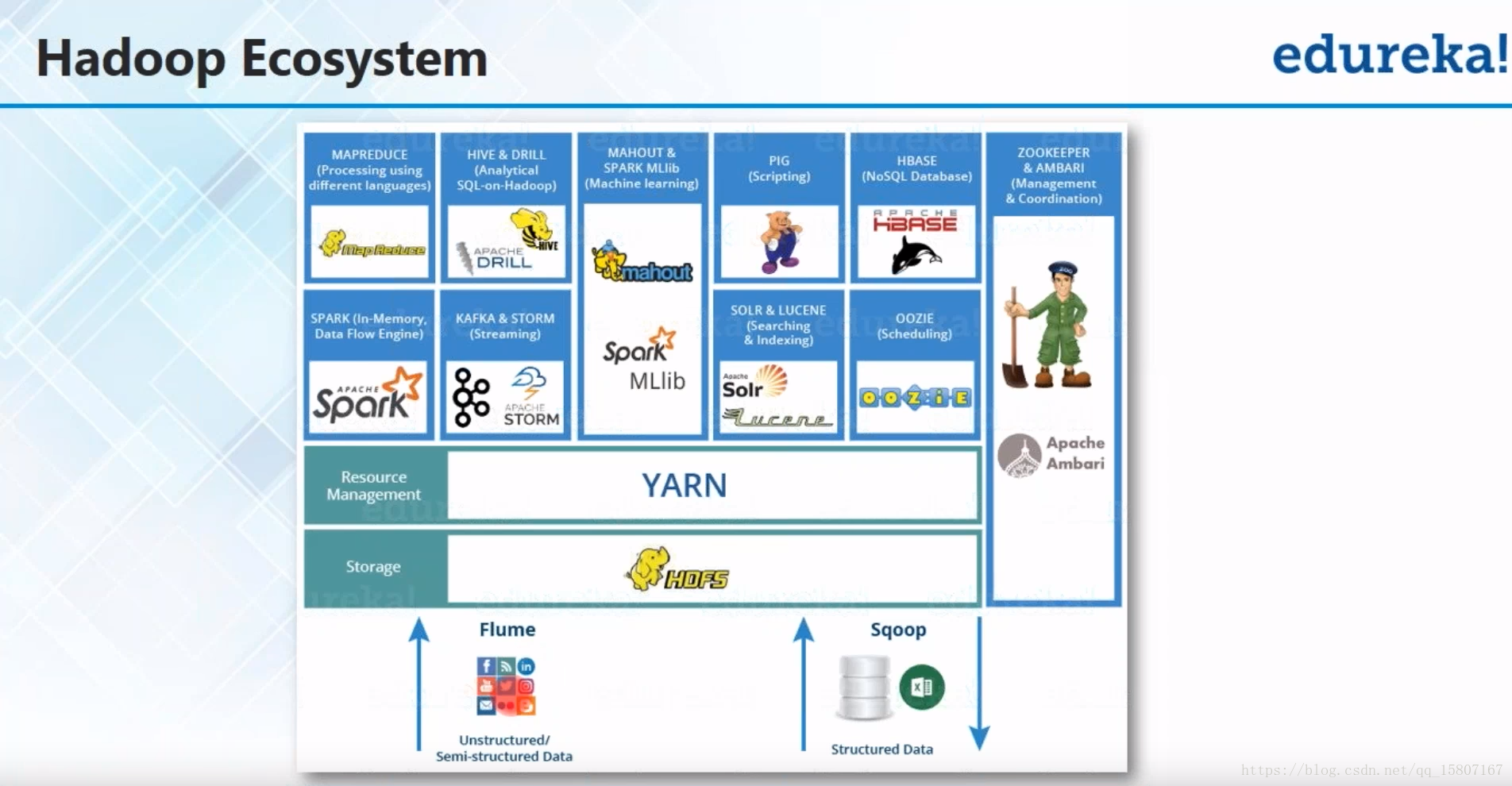
| 模块名 | |
|---|---|
| Hadoop Common | 公用的工具模块 |
| Hadoop Distributed File System(HDFS) | 高效的数据处理分布式文件系统 |
| Hadoop YARN | 工作时序和从机资源管理 |
| Hadoop MapReduce | 基于YARN系统的平行处理大数据集 |
| Ambari | 一个基于Web的工具,用于提供、管理和监视ApacheHadoop集群,更加友好的图形化展示界面 |
| Avro | 数据序列化系统。 |
| Cassandra | 没有单点故障的可扩展多数据库 |
| Chukwa | 管理大型分布式系统的数据收集系统。 |
| HBase | 支持数据结构化存储的可扩展的分布式数据库 |
| Hive | 提供数据摘要和临时查询的数据仓库基础结构。 |
| Mahout | 可扩展的机器学习和数据挖掘库 |
| Pig | 并行计算的高级数据流语言和执行框架 |
| Spark | Hadoop数据的快速通用计算引擎。SMARK提供了一个简单而有表现力的编程模型,它支持广泛的应用程序,包括ETL、机器学习、流处理和图形计算。 |
| Tez | 它提供了一个强大而灵活的引擎来执行任意DAG任务,为批处理和交互用例处理数据。Hadoop生态系统中的Hive™、Pig™和其他框架以及其他商业软件(例如ETL工具)都采用了TEZ,以取代Hadoop™MapReduce作为底层执行引擎。 |
| Zookeeper | 高性能的分布式应用程序协调服务。 |
参考的资料
- Hadoop Intro
- Apache Hadoop 官网
- Hadoop中文实战