
论文:https://arxiv.org/pdf/2301.00808.pdf
提出一个完全卷积的MAE框架和一个新的全局相应归一化层GRN,可以添加到ConvNeXt架构中,以增强通道间的特性经济。这种自监督学习技术和架构的改进的共同设计产生了一个新的模型family,称为ConvNeXt V2,它显著提高了纯convnet在各种识别基准上的性能,包括ImageNet分类,COCO目标检测和ADE20k分割。还提供了各种尺寸的预训练ConvNeXt v2模型,从而在ImageNet上具有76.7%精度的3.7M Atto model和88.9%精度的650M huge model。
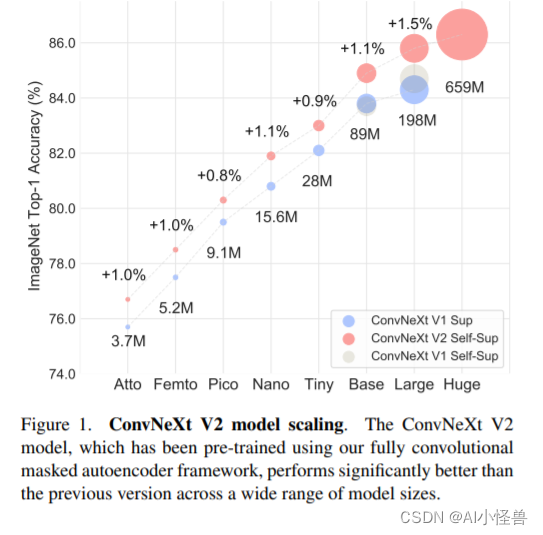
提供了各种大小的预训练 ConvNeXt V2 模型,范围从高效的 3.7M 参数 Atto 模型到 650M 的 Huge 模型。如下图所示,这里也展示了论文题目中提到的强大的模型缩放能力(Scaling),即在所有模型大小的监督训练的 baseline(ConvNeXt V1)上,ConvNeXt V2 的性能都得到了一致的改进。
下 图展示了作者对每个特征通道的激