环境:kaggle平台+python3.7+TensorFlow
完整代码、模型及参数、详细文档见:猫狗大战完整代码+详细文档+模型参数
文章目录
1.概述
1.1 任务
猫狗大战的实验目的是通过给定的猫狗图片数据集训练神经网络模型,通过CNN架构提取图片特征,实现模型对于猫狗两种动物的识别。
1.2 数据集
采用kaggle官方Cats VS. Dogs比赛数据集。该数据集是由 Microsoft Research Asia 发布的猫狗大战数据集。该数据集包括 25000 张猫和狗的图片,其中 12500 张是猫的图片,另外 12500 张是狗的图片。每张图片的大小不一,颜色、角度、光线等也有所不同。
1.3 解决方案
基于深度学习的解决方案:基于tensorFlow框架搭建神经网络,从零开始一步步完成数据读取、网络构建、模型训练和模型测试等过程,最终实现一个可以进行猫狗图像分类的分类器;并借助数据增强技术,例如旋转、翻转、缩放等,来增加数据集的多样性,从而提高模型的泛化能力和鲁棒性。
以下使用卷积神经网络来构建模型。在 CNN 中,通过卷积层、池化层、全连接层等结构,可以自动学习图像的特征,并将其转化为一个向量表示。通过这个向量表示,可以进行分类或者其他任务。
2 解决方案
2.1 加载、查看训练集/测试集
查看训练集/测试集大小,样例:
os.listdir():返回指定目录中的所有文件和文件夹的列表。
#返回指定路径下的所有文件和目录的名称列表
train_path = '/kaggle/working/train'
test_path = '/kaggle/working/test'
train_file_names = os.listdir(train_path)
test_file_names = os.listdir(test_path)
print("训练集大小:{}".format(len(train_file_names)))
print("测试集大小:{}".format(len(test_file_names)))
print("训练集样例:{}".format(train_file_names[0:5]))#训练集文件名:标签+序号
print("测试集样例:{}".format(test_file_names[0:5])) #测试集文件名:序号

2.2 处理数据
训练集/测试集路径、标签存入DataFrame:
#训练集 train_image_path label
import pandas
image_paths = []
labels = []
for train_file in train_file_names:
label = train_file.split('.')[0]
labels.append(label)
image_path = os.path.join(train_path, train_file)
image_paths.append(image_path)
train_df = pandas.DataFrame()
train_df['train_image_path'] = image_paths #为自定义属性名添加列表
train_df['label'] = labels
train_df.head()
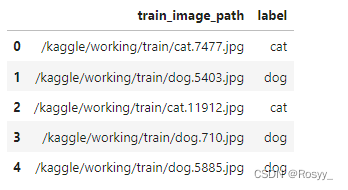
#测试集 teat_image_path
image_paths = []
test_idx = []
for test_file in test_file_names:
idx = test_file.split('.')[0]
test_idx.append(idx)
image_path = os.path.join(test_path, test_file)
image_paths.append(image_path)
test_df = pandas.DataFrame()
test_df['test_image_path'] = image_paths
test_df.head()

分割训练集、验证集:
train_test_split()用于将数据集分成训练集和测试集。设置stratify参数可以按照标签进行分层抽样,以免数据分割是有偏的。
# 以下是分层抽样,因为随机抽样容易导致样本偏差
from sklearn.model_selection import train_test_split
# !pip install numpy --upgrade #更新Numpy
#stratify 参数被设置时,会按照标签的比例将数据集分成训练集和测试集。
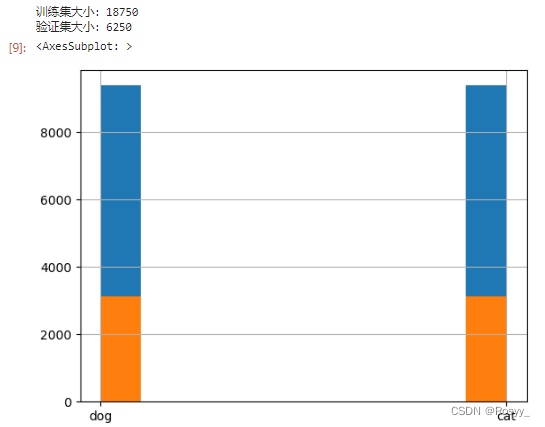
train_set, val_set = train_test_split(train_df, random_state=42, stratify=train_df['label'])# 设置分层抽样
print("训练集大小:{}".format(len(train_set)))
print("验证集大小:{}".format(len(val_set)))
train_set['label'].hist() #此时样本是无偏的
val_set['label'].hist()
查看图片(以验证集为例):
import matplotlib.pyplot as plt
import matplotlib.image as img
#fig 是一个 Figure 对象,表示整个图表,而 axes 是一个包含每个子图的 Axes 对象数组。可以使用 fig 对象控制整个图表的属性,使用 axes 对象控制每个子图的属性。
fig, axes = plt.subplots(3,3,figsize=(10,10))
axes = axes.ravel()
for i in range(9):
axes[i].imshow(img.imread(val_set.iloc[i,0]))
axes[i].axis('off')#控制图表中的四个轴是否显示
#自动调整子图之间的间距和位置,以便它们更好地适应图表的大小
fig.tight_layout()
plt.show()

数据增强:
数据增强仅对训练集操作,
ImageDataGenerator()可以在训练模型时实时生成数据的批次,并对数据进行随机变换。例如,可以将图像进行随机旋转、缩放、剪切和翻转等操作。这些变换可以增加数据集的多样性,从而提高模型的泛化性能。
flow_from_dataframe()可以从 DataFrame 中读取图像文件的路径和标签信息,然后使用 ImageDataGenerator 对象对图像数据进行数据增强和预处理,最终生成增强后的图像数据流以供模型的训练。
关于数据增强的一些疑惑???
数据增强时候设置的batchsize和模型训练时中的batchsize需要相等吗?为什么说数据增强可以增加训练样本数量,而在执行完数据增强后没有将其与原始训练样本合并?
数据增强后的数量会大于原始数据集数量,所以一个epoch中的数据中有重复的吗?不同epoch的数据集一样吗?
理解放在:【数据增强】彻底搞懂数据增强做了哪些工作?
train_gen = ImageDataGenerator(
zoom_range=0.1,
rotation_range=10,
rescale=1./255,
shear_range=0.1,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1
)
train_generator = train_gen.flow_from_dataframe(
dataframe=train_set,
x_col='train_image_path',
y_col='label',
target_size=(200,200),
class_mode='binary',
batch_size=128,
shuffle=False
)
print(len(train_generator))

#验证集
val_gen = ImageDataGenerator(
rescale=1./255
)
val_generator = val_gen.flow_from_dataframe(
dataframe=val_set,
x_col='train_image_path',
y_col='label',
target_size=(200,200),
class_mode='binary',
batch_size=128,
shuffle=False
)
print(len(val_generator))

#测试集
test_datagen = ImageDataGenerator(
rescale=1./255
)
test_generator = test_datagen.flow_from_dataframe(
dataframe=test_df,
x_col='test_image_path',
y_col=None,
target_size=(200,200),
class_mode=None,
batch_size=128,
shuffle=False
)
print(len(test_generator))

2.3 搭建模型
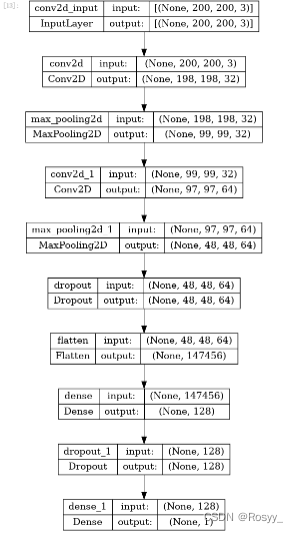
CNN结构设计如下:
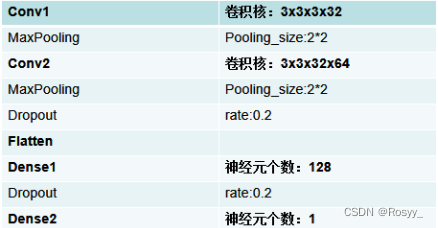
model = Sequential()
model.add(Conv2D(32,kernel_size=(3,3),input_shape=(200,200,3),activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(64,kernel_size=(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
2.4 设置优化器、损失函数
优化器:Adam。
损失函数:交叉熵损失,用于分类。
model.compile(optimizer='adam', #优化器Adam
loss='binary_crossentropy', #损失函数:交叉熵损失
metrics=['accuracy']) #准确率:accuracy:y_/y均为数值;categorical_accuracy:y_/y都是独热码;sparse_categorical_accuracy:y_/y是数值+独热码
model.summary()

2.5 存取模型、断点续训
每训练一个epoch,保存一次模型参数。
tf.keras.callbacks.ModelCheckpoint 函数可以保存模型的权重和偏置,以及训练进度等信息,以便在中断训练后可以恢复到之前的模型状态继续进行训练。
参数含义:filepath 参数指定了保存模型配置的文件路径,save_weights_only 参数指定是否只保存模型权重,save_best_only 参数指定是否只保存最好的模型结果。默认情况下,该回调函数会在每个 epoch 后保存模型配置。
#一旦改变模型就要删掉模型文件
checkpoint_save_path = "./checkpoint/mnist.ckpt"
if os.path.exists(checkpoint_save_path + '.index'): #index:
print('------------------------load the model----------------------------')
model.load_weights(checkpoint_save_path) #加载模型
cp_callback = tf.keras.callbacks.ModelCheckpoint( #保存模型cp_callback
filepath=checkpoint_save_path,
save_weights_only=True, #只保存weight
save_best_only=True #只保存最好的一次
)
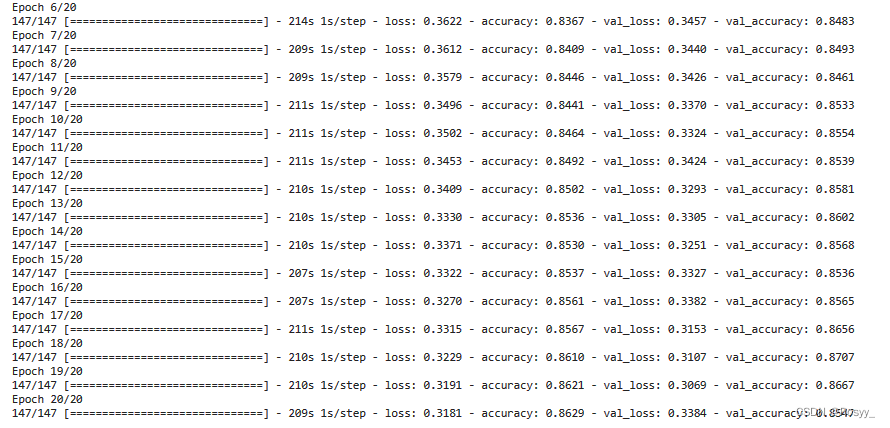
history = model.fit(train_generator,
epochs=20,
batch_size=128,
validation_data=val_generator,
validation_freq=1,
callbacks=[cp_callback],
verbose=1)
2.6 参数保存
将训练参数保存至weights.txt文件中。
file = open('./weights.txt', 'w') #设置weights保存路径
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()#
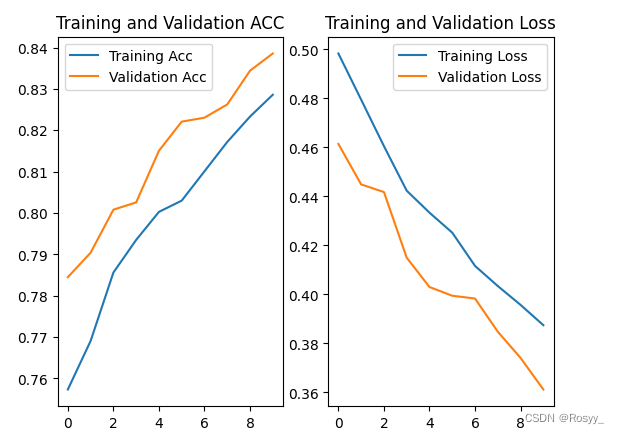
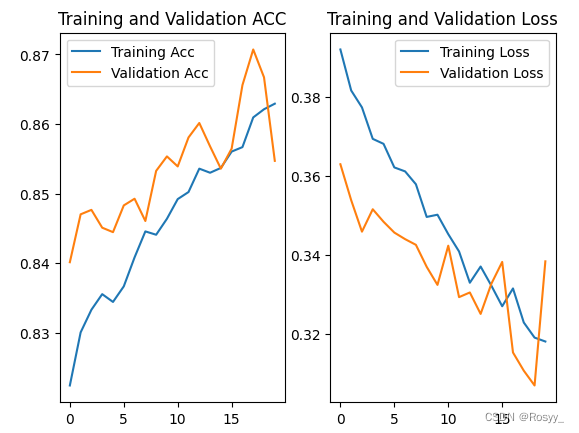
2.7 训练结果可视化
通过 matplotlib 库画出训练集和测试集的acc/loss曲线,如下图:
#训练集acc/loss
acc = history.history['accuracy']
loss = history.history['loss']
#测试集acc/loss
val_acc = history.history['val_accuracy']
val_loss = history.history['val_loss']
#acc曲线
plt.subplot(1,2,1)
plt.plot(acc, label='Training Acc')
plt.plot(val_acc, label='Validation Acc')
plt.title('Training and Validation ACC')
plt.legend()
#loss曲线
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
epoch=10时,模型未收敛:
epoch=20时,
2.8 预测测试集
predictions = model.predict(test_generator)
predictions = numpy.round(predictions.flatten()).astype(int)
print(numpy.size(predictions))

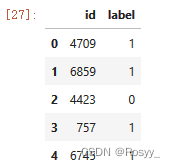
将测试集上的预测结果存入submission.csv文件。
submission = pandas.DataFrame({'id':test_idx,'label':predictions})
submission.to_csv("submission.csv",index=False)
df = pandas.read_csv('/kaggle/working/submission.csv')
df.head()
3 总结
基于TensorFlow框架,实现了从零开始一步步完成数据读取、网络构建、模型训练和模型 测试等过程,最终实现一个可以进行猫狗图像分类的分类器。通过本实验,掌握在Kaggle平台上实现一个完整竞赛题目的过程,加深了对卷积神经网络用于图像分类任务的理解,提高了实践能力。