一:C语言中的文件IO相关操作
1.fopen
函数原型如下:

函数参数:1.path为打开文件的相对或者绝对路径
2. mode打开文件的方式
常见的文件打开方式:
r :以读方式打开,该文件必须存在
r+:以读写方式打开,该文件必须存在
w :打开只写文件,若文件存在长度清为0,如果没有,则创建
w+:打开可读写文件,若文件长度存在长度清为0,如果没有,则创建
a:以附加的方式打开只写文件,若文件不存在,建立文件,如果文件存在,写入的数据会被追加到文件结尾,原先的
内容会被保留
a+:以附加的方式打开可读写的文件,若文件不存在,建立文件,如果文件存在,写入的数据会被追加到文件尾部
返回值:如果打开文件成功返回该指向该文件流的指针,失败返回-1
2.fwrite
函数原型:
函数功能:是向指定的文件中写入若干数据块,如果成功返回实际写入的数据块数目
函数参数:ptr要获取数据的地址,size每个数据块字节数,nmemb要写入的数据块个数,stream目标文件指针
函数返回值:返回实际写入得到数据块个数,注意此处不是实际读到的字节数
3.fread
函数原型:

函数功能:是从指定文件中读数据,最多读取nmemb个数据块,每个数据块size字节,如果调用成功返回实际读取到的数据块个数,如果不成功或读到文件末尾返回0
函数参数:ptr指定读到哪里,size每个数据块字节数,nmemb要读取的数据块数,stream从哪个文件读取
二:系统调用的相关文件IO操作函数
1.open
函数原型:

函数参数:pathname为要打开的文件名,flag打开文件的方式,mode为新文件的访问权限
flag:打开文件时,可以传入多个参数选项,用下面一个或者多个常量进行或运算,构成flag
参数:
O_RDONLY:只读打开
O_WRONLY:只写打开
O_RDWR:读写打开(这三个常量,能且只能指定一个)
O_CREAT:若文件不存在则创建它,需要用mode权限来指定新创建文件的默认权限
返回值:
成功:新打开的文件描述符
失败:-1
2.write
函数原型:

函数功能:从buf指定的位置向文件描述符为fd的文件中写入count字节
函数返回值:成功:实际写入的字节数 ssize_t为有符号整形
失败:返回-1
注意:write不会将源文件里面的内容,清空而是从头写,将原来的内容覆盖掉,其他不变。这也正是write和fwrite的区别之处,fwrite是清空,而write是覆盖。
3.read
函数原型:

函数功能:从文件描述符为fd的文件中,读数据读count字节个数据到buf.
函数返回值:成功:实际读到buf的字节数 失败:-1
总结:上面所说的所有带f的为c库函数,而不带f的为系统调用
系统调用和库函数区别:系统调用是更底层的,库函数是封装了系统调用
三:文件描述符
当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件,于是有了file结构体。表示一个已经打开的文件对象,进程执行open系统调用接口,所以必须让进程和文件关联起来,每个进程的PCB中都有一个指针*files,指向一张表files_struct,该表中最重要的一部分就是包含一个指针数组,数组中每个元素都是指向一个打开文件的指针。
本质:文件描述符本质其实是一个结构体中一个数组的下标,
文件描述符的分配规则是从0开始找第一个未分配的下标

使用命令ulimit -n 可以查看当前文件描述符的上限 1024
但是这个上限是可以修改的,使用命令ulimit -n 2048是可以修改的。但是修改上限也是有限的----cat /proc/sys/fs/file-max可以查看我们可以修改的上限的最大值-------系统里面的上限
四:重定向
1.上面我们说到运行一个进程会默认分配0,1,2号文件描述符,对应打开的是标准输入(键盘),标准输出(屏幕),标准错误(屏幕)。
常见的重定向:输出重定向>,输入重定向<,追加重定向>>.
输出重定向的概念:我们知道运行一个进程,结果会默认输出到屏幕上。而重定向就是指让输出结果不再输出到屏幕上,而是输出到指定的文件中。
输出重定向的本质:重定向的本质是关闭文件描述符1,然后打开一个文件,系统会为这个文件分配一个文件描述符,而文件描述符的分配规则是从0开始找最小的未使用的进行分配。因此就把1文件描述符分配给这个文件,接下来程序运行结果就不再是输出到屏幕,而是输出到你新打开的这个文件中。
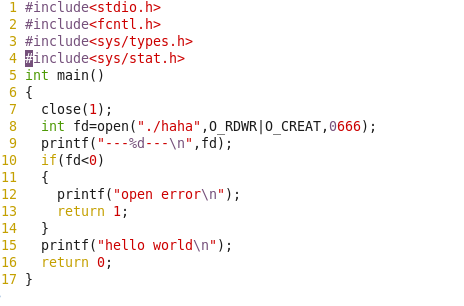
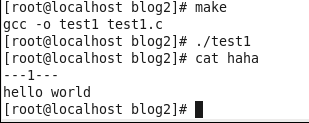
2.输出重定向可以使用上面这种方式实现,也可以用下面这个函数函数实现
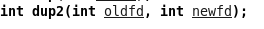
函数功能:把newfd重定向到oldfd.(注意此处不要搞错)
返回值:成功返回新的文件描述符,失败返回-1

学一个命令:

五:缓冲方式
常见的缓冲方式有三种:1.无缓冲 : 直接写道I/O设备
2.行缓冲 : 遇到\n,刷新
3.全缓冲: 缓冲区满,或者手动刷新
你会几种方式输出一个字符串.

可以看出上面这种方式都可以输出字符串.我们接着看。
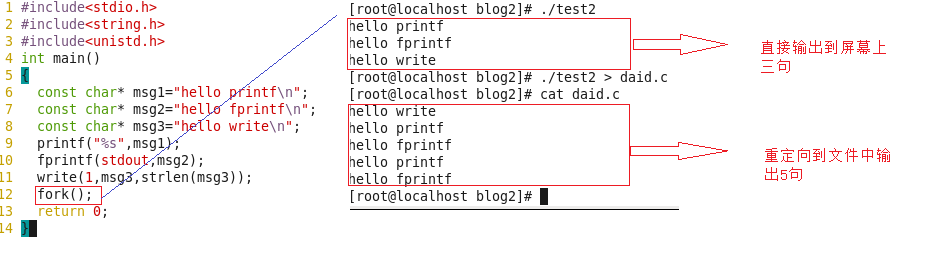
我们发现fork之后我们什么也没干,按理来说应该和上面那个图一样的结果可是为什莫呢?
重定向到文件里面为什莫fprintf和printf多打印了呢?而且多打印的和fork有关。
原因如下:
printf和fprintf是C库函数有缓冲区,并不是直接写到屏幕上,C库函数写入显示器是行缓冲的,写入普通文件是全缓冲的。 而系统调用write没有缓冲区。 fork的时候子进程会把缓冲区的内容继承了,然后等到进程退出后统一刷新。因此输出5条。
结论:printf fprintf库函数会自带缓冲区,而write系统调用没有带缓冲区。我们这里所说的缓冲区都是用户级缓冲区,此缓冲区 是C库提供的。
五:文件系统
1.

我们使用ls-l时,不仅可以看到文件名,还看到文件元数据,也就是文件属性。
看到的7列分别是:模式 硬链接数 文件所有者 组 大小 最后修改时间 文件名
一个文件由两部分组成:1.文件内容 2.文件属性(元数据)
命令:stat 可以查看文件元数据

我们先来了解一下文件系统:

内存 支持随机访问 一次1字节
磁盘 也支持随机访问 一次1块512字节
创建一个新文件的四个操作:
1.存储属性:内核先找到一个空闲的i节点(23110)(根据inode_bitmap)。内核把文件信息记录到其中
2.存储数据内容:找到n个空闲block块(根据block_bitmap),
3.记录分配情况:比如说文件内容按顺序在200 300磁盘块存放,内核要在inode中记录上述列表块
4.添加文件名到目录:新的文件名为abc ,linux如何在当前的目录中记录这个文件,内核将入口(23110,abc)添加到目录 文件,文件名和inode的对应关系将文件名和文件的内容及属性连接起来。
了解了上面这些我们应该知道,真正找到磁盘上文件的不是文件名而是inode号。
疑问:
为什莫要这样分区存储呢,文件扩展收缩更加的容易。
解释:因为文件的内容等等我们有时需要改动,我采用分区存储,只要加一个block块,然后把这个块的地址,记录inode里面即 可
如果采用传统的将文件属性和文件的内容存放到一起,如果文件内容要修改,就要搬动其他的文件。(这还是搬运磁盘会 慢死人的),因此分区存储的好处就是文件的扩展收缩更加容易。
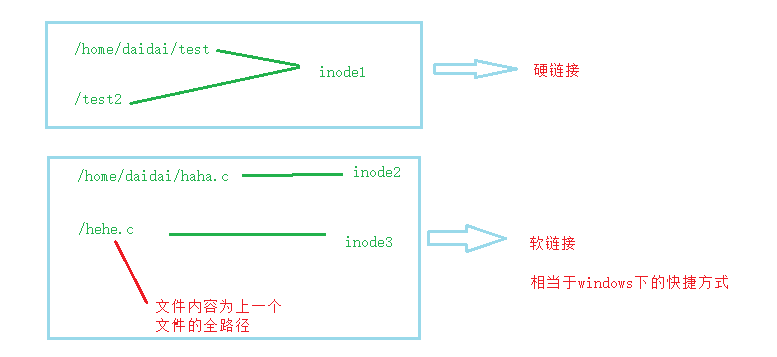
2.硬链接
两个文件inode相同
创建硬链接:ln abc haha
硬链接数:有几个文件指向一个inode,硬链接数就是几
在删除时:硬链接数-1,等到硬链接数减为0,才真正删除
ls -li abc可以查看inode号

3.软连接
inode不相同的两个文件,但是有一个文件的内容是另一个文件的全路径
创建软连接:ln -s test.c aaa ---------->
文件类型变了,由普通文件-变为链接文件l
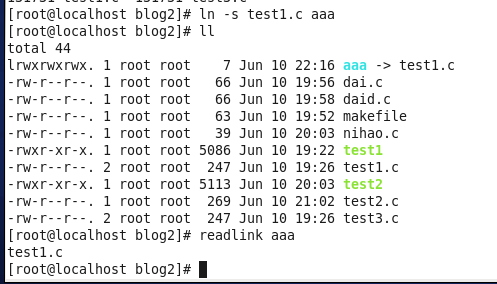
软硬链接图解: