文章目录
1. ESPCN概述
《Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel》 提出了一种新的上采样方式,对于SR(super-resolution) 任务的计算速度和重建效果都有不错的提升。
文章推出了一种在以往算法(SRCNN、Bicubic)上对于重建表现力以及计算效率(重建速度、计算资源损耗)都有一定提升的SR算法——ESPCN。
SRCNN先对输入图像做Bicubic插值,然后进行特征提取,这种方式相当于直接在HR层面做超分,作者证明这种方式是一种次优策略且会带来计算复杂度的提升。
针对这种问题,作者提出了ESPCN结构:
- 这是一种直接对输入LR图像做特征提取。
- 在网络中引入了一种
亚像素卷积层,该层通常为网络的最后一层,它以之前特征提取后的feature map为输入,通过学习一个上采样滤波器来做到LR→SR的重建。 - 直接对LR图像做卷积取代了SRCNN中的bicubic预处理部分,这直接带了计算复杂度的降低以及执行速度的提升,作者实现了在1080P视频中的超分效果,做到了标题中的”Real-Time“。
- ESPCN在图像和视频上都做了相关的实验,分别提升了0.15dB以及0.39dB;此外ESPCN的执行速度也超越了之前的CNN-based系列SR算法。
2. 论文详解
2.1 Introduction
ESPCN主要2个点很重要:①是直接对L R LR层级图像进行特征提取,②就是一个亚像素卷积层,下面展开来说下:
- ESPCN直接对LR层级的图像进行卷积提取特征,因此我们可以采用一个较小的滤波器去整合不同level的特征信息,相比于SRCNN,这种做法不仅减小了训练参数,同时也降低了计算的复杂度,减少了训练时间。
此外,正如DCSCN这篇论文中所说的,在r ≥ 3的时候,直接对输入图像提取的特征和先用bicubic插值放大之后提取到的特征其实并无差异,因此插值就会显得多余,且浪费计算成本。 - SRCNN中上采样的方式就是一个简单的处理过程:将输入LR图像做插值,只需要一个滤波器即可。而在ESPCN中,假设整个网络有L层,那么第L−1层产生的 n L − 1 n_{L-1} nL−1张feature map,那么在第L层,我们就可以学习一种更复杂的方式,训练 n L − 1 n_{L-1} nL−1个卷积核而不是简单的一个。
更重要的是,最后这层可以隐式地去学习这个通道数 n L − 1 n_{L-1} nL−1地滤波器,它本质上就是一个shuffle地过程,将 r 2 r^2 r2张feature map进行整合,这就是亚像素卷积层。
2.2 Method
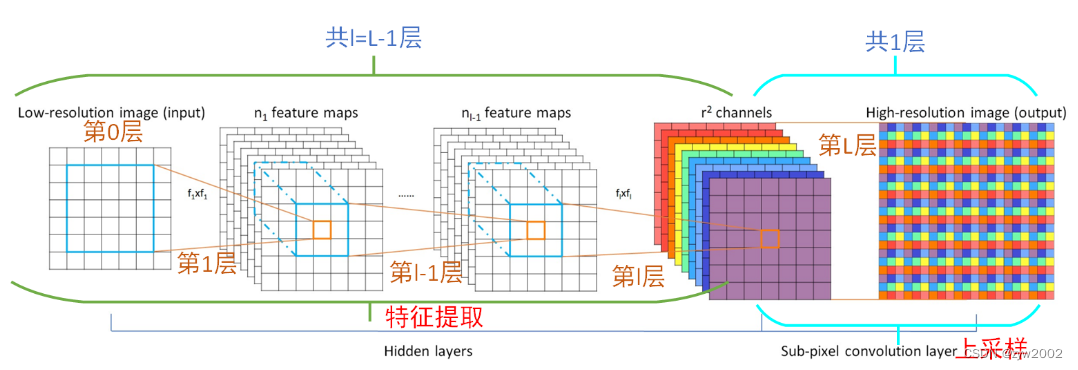
上图就是ESPCN网络结构,接下来对其中几点进行说明:
- 输入图像是LR图像,通道数为C,比如RGB格式图像中,C = 3,我们的目标就是从 C × H × W C\times H\times W C×H×W的图像变成 C × r H × r W C\times rH\times rW C×rH×rW的图像。
- 整个网络分为2部分:特征提取部分,由连续的CNN网络组成;上采样部分,由一个亚像素卷积层构成。
- 设整个网络一共有L层,前L − 1 层通过卷积、非线性激活组成,具体表达式为:
f 1 ( I L R ; W 1 , b 1 ) = ϕ ( W 1 ∗ I L R + b 1 ) , f l ( I L R ; W 1 : l , b 1 : l ) = ϕ ( W l ∗ f l − 1 ( I L R ) + b l ) , \begin{aligned}f^1\left(\mathbf{I}^{L R} ; W_1, b_1\right) & =\phi\left(W_1 * \mathbf{I}^{L R}+b_1\right), \\f^l\left(\mathbf{I}^{L R} ; W_{1: l}, b_{1: l}\right) & =\phi\left(W_l * f^{l-1}\left(\mathbf{I}^{L R}\right)+b_l\right),\end{aligned} f1(ILR;W1,b1)fl(ILR;W1:l,b1:l)=ϕ(W1∗ILR+b1),=ϕ(Wl∗fl−1(ILR)+bl),
其中 W l , b l , l ∈ ( 1 , L − 1 ) W_l, b_l, l∈(1,L−1) Wl,bl,l∈(1,L−1)分别是可学习的网络权值和偏差。 W l W_l Wl为大小为 n l − 1 × n l × k l × k l n_{l−1}×n_l×k_l×k_l nl−1×nl×kl×kl的二维卷积张量,其中 n l n_l nl为 l l l 层特征的个数, n 0 = C n_0 = C n0=C, k l k_l kl为 l l l 层滤波器的大小。偏差 b l b_l bl为长度为 n l n_l nl的向量。非线性函数(或激活函数) ϕ \phi ϕ 按element-wise应用,且是固定的。 - 特征提取层保持图像的大小不变。
2.2.1 Deconvolution layer
增加deconvolution layer是从最大池化和其他图像下采样层恢复分辨率的常用方法。这种方法已经成功地用于visualizing layer activations[49]和 generating semantic segmentations using high level features from the network[24]。
可以看出,SRCNN中使用的双三次插值(bicubic interpolation)是反卷积层的一个特殊情况,如[24,7]所述。[50]中提出的deconvolution layer可以看作是每个input pixel 与一个步幅 r r r的滤波器元素的element-wise 成绩,以及对结果输出窗口的和,也称为backwards convolution[24]。
2.2.2 Efficient sub-pixel convolution layer
提出背景:
另一种upscale LR图像的方法是在LR空间中进行步幅为 1 r \frac {1}{r} r1的卷积,如[24]所述,这可以简单地通过interpolation、perforate[27]或从LR空间un-pooling到HR空间[49],然后在HR空间中又进行步幅为1的卷积来提升性能。这些实现增加了 r 2 r^2 r2的计算成本,因为卷积发生在HR空间中。
因此作者提出了一种同样以 1 r \frac{1}{r} r1 为步长,但不需要额外计算量的隐式卷积层——亚像素卷积层(sub-pixel convolution layer)。
亚像素卷积的核心思想:一张图像放大r倍,就相当于每个像素都放大r倍。
在网络倒数第二层卷积过程输出通道数为r^2与原图同样大小的特征图像
然后经过亚像素卷积层周期性排列,得到大小为(w × r , h × r) 的重建图像。
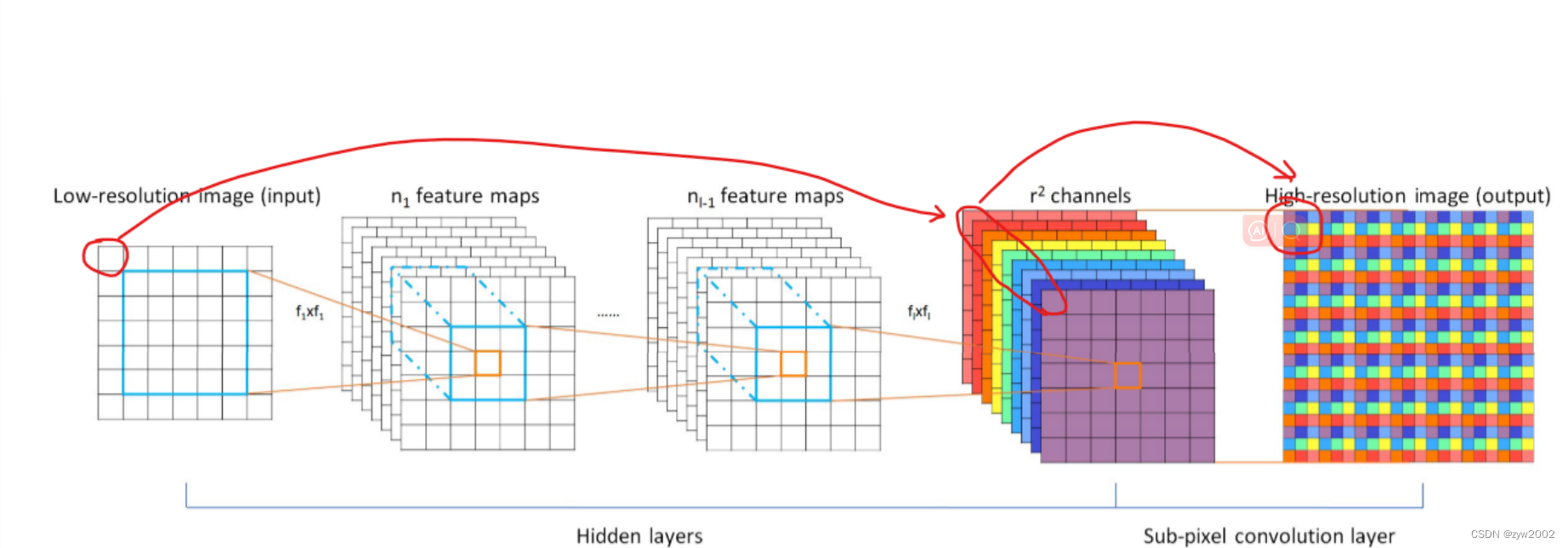
如上图中倒数第二层红圈框住的9个特征,排列后组成箭头所指的最后一层小方框,这就是原图中框住的像素经过网络构成的重建块。这九个像素刚好使原像素的长宽各放大了三倍。
亚像素卷积(Sub-pixel Convolution)其实并没有卷积运算,只是抽取特征然后进行简单排列。
亚像素卷积的原理
- 为什么叫亚像素卷积?
可以将亚像素卷积层看成是一个隐式卷积的过程:隐式卷积的意思就是还是会用一个滤波器去抽取信息,但是和传统的卷积运算不同,这里并没有涉及可学习的滤波器参数以及任何乘加运算。
亚像素卷积过程中从左到右的过程就好像以一个 s t r i d e = 1 r stride=\frac{1}{r} stride=r1对LR图像做卷积,从而在直观上好像卷积生成出了一些小小的像素点,又因为 1 r ≤ 1 \frac{1}{r}\leq1 r1≤1 ,意味着它做的是整像素内部的运算,我们称之为亚像素,比如视频处理中常见的 1 2 \frac{1}{2} 21、 1 4 \frac{1}{4} 41像素都是亚像素。
- 亚像素卷积是如何工作的?
在LR空间中,一个步幅为 1 r \frac {1}{r} r1的卷积与一个大小为 k s k_s ks且weight spacing为 1 r \frac {1}{r} r1的滤波器 W s W_s Ws将激活卷积中 W S W_S WS的不同部分。落在像素之间的权重不被激活,不需要计算。激活模式的数量正好是 r 2 r^2 r2。每个激活模式,根据其位置,最多激活 ⌈ k s r ⌉ 2 \left\lceil\frac{k_s}{r}\right\rceil^2 ⌈rks⌉2个权重。根据不同的sub-pixel 的位置: m o d ( x , r ) mod (x, r) mod(x,r), m o d ( y , r ) mod (y, r) mod(y,r),其中 x , y x, y x,y是HR空间中的输出像素坐标。在本文中,我们提出了在 m o d ( k s , r ) = 0 mod (k_s, r) = 0 mod(ks,r)=0时实现上述操作的一种有效方法 :
I S R = f L ( I L R ) = P S ( W L ∗ f L − 1 ( I L R ) + b L ) \mathbf{I}^{S R}=f^L\left(\mathbf{I}^{L R}\right)=\mathcal{P} \mathcal{S}\left(W_L * f^{L-1}\left(\mathbf{I}^{L R}\right)+b_L\right) ISR=fL(ILR)=PS(WL∗fL−1(ILR)+bL)
其中 P S PS PS是一个周期变换算子,它将 H × W × C ⋅ r 2 H×W×C·r^2 H×W×C⋅r2 张量的元素重新排列为 r H × r W × c rH × rW × c rH×rW×c形张量。该操作的效果如图1所示。数学上,这个操作可以用下面的方式描述 :
P S ( T ) x , y , c = T ⌊ x / r ⌋ , ⌊ y / r ⌋ , C ⋅ r ⋅ m o d ( y , r ) + C ⋅ m o d ( x , r ) + c \mathcal{P S}(T)_{x, y, c}=T_{\lfloor x / r\rfloor,\lfloor y / r\rfloor, C \cdot r \cdot \bmod (y, r)+C \cdot \bmod (x, r)+c} PS(T)x,y,c=T⌊x/r⌋,⌊y/r⌋,C⋅r⋅mod(y,r)+C⋅mod(x,r)+c
卷积操作 W L W_L WL 的形状是 n L − 1 × r 2 C × k L × k L n_{L-1}\times r^2C\times k_L\times k_L nL−1×r2C×kL×kL。请注意,我们没有将非线性应用到最后一层卷积的输出。很容易看出,当 K L = k s r K_L=\frac{k_s}{r} KL=rks, 而 m o d ( k s , r ) = 0 mod(k_s,r)=0 mod(ks,r)=0 则相当于在LR空间与滤波器 W s W_s Ws进行sub-pixel convolution。
我们将我们的新层称为sub-pixel convolution layer,我们的网络称为efficient sub-pixel convolutional neural network(ESPCN)。最后一层从LR特征映射直接生成一个HR图像,每个特征映射都有一个upscaling 滤波器,如图4所示。

训练方式
给出了一个包含HR Image 示例的训练集 I n H R , n = 1... N I_n^{HR},n=1...N InHR,n=1...N,我们生成相应的LR图像 I n L R , n = 1 , . . , N I_n^{LR},n=1,..,N InLR,n=1,..,N,然后计算 pixel-wise mean squared error (MSE) 作为目标函数来训练我们的网络。
ℓ ( W 1 : L , b 1 : L ) = 1 r 2 H W ∑ x = 1 r H ∑ x = 1 r W ( I x , y H R − f x , y L ( I L R ) ) 2 \ell\left(W_{1: L}, b_{1: L}\right)=\frac{1}{r^2 H W} \sum_{x=1}^{r H} \sum_{x=1}^{r W}\left(\mathbf{I}_{x, y}^{H R}-f_{x, y}^L\left(\mathbf{I}^{L R}\right)\right)^2 ℓ(W1:L,b1:L)=r2HW1x=1∑rHx=1∑rW(Ix,yHR−fx,yL(ILR))2
3. pytorch中的相关实现
关于亚像素卷积层,pytorch 中也提供了对应的实现torch.nn.PixelShuffle() 和 torch.nn.PixelUnshuffle()
用法详见【torch.nn.PixelShuffle】和 【torch.nn.UnpixelShuffle】