统计的结果请见第一篇文章.
代码已经开源至GitHub
本文下面所有的爬虫项目都有详细的配套教程以及源码,都已经打包好上传到百度云了,链接在文章结尾处!
扫码此处领取大家自行获取即可~~~

讲真, 这个应该是我做过的最难受的爬虫项目. 一共搞了两天半, 嘛都干不了哎哟.
因为Pixiv的反爬机制, 好端端的代码硬生生地堆成了屎山.
首先, 我们来确定一下我们的统计逻辑.
要统计各角色的涩图数量, 可以直接在Pixiv搜索角色的名字. 但是对于爬虫来说, 或许要用如下链接.
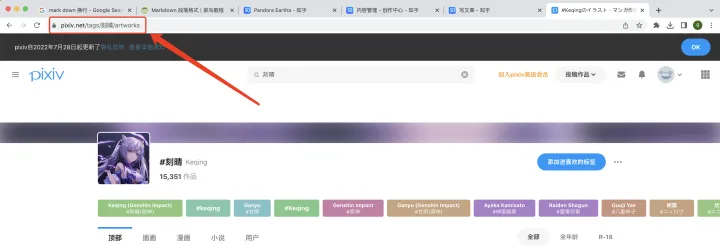
Pixiv中主要使用的语言有, 简体中文, 繁体中文, 日文, 英文, 韩文五种. 虽然也有些创作者会采用俄语, 但是考虑到原神并没有俄语版本, 因此我们不统计俄语的.
同时, 我们注意到, 对于每一个角色的名字来说, 有些名字搜索出来的并不一定就是和和原神相关的, 这种我们自然不能让其被统计进去.
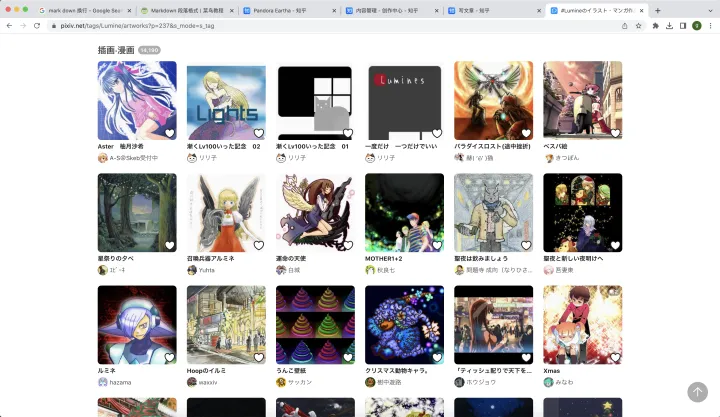
Lumine tag下 也有和原神 荧 不相关的作品
OK, 那么总结一下, 我们的逻辑就是:
- 先获取到原神各角色各语言的名字, 比如说凯亚, Kaeya, 凱亞, ガイア, 케이아.
- 然后, 再在Pixiv上根据这些名字爬取所有作品,
- 爬取到的作品中, 并不是全部都和原神相关, 因此, 我们创建一个list, 要求该作品必须出现这个list的一个元素, 或者其他原神角色的名字(任意语言都行), 才能被判断为属于该原神角色的涩图. 具体的list会在后面给出
- 统计上述作品中不重复的部分.
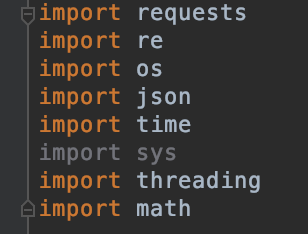
用到的package如下所示.
首先, 我们得获取原神各角色名字, 这个在原神官网就能爬取到.

但是, 在实际爬取过程中, 这个网站切换语言经常失败或者自动根据IP地址跳转.
甚至还可以返回一半英语一半日文的内容. 因此我手动保存了这个网站的个语言的源代码,

简体中文的名字在原神国内官网就能找到, 和国际官网类似, 但是注意, 一定注意.
国内官网刻晴和七七的顺序有误, 需要在保存的源代码中调整.
繁体中文

简体中文(顺序错误)
之后再用正则识别出各角色的各语言名字.

注意为了数据的准确性, 可以对一些稻妻角色姓名做一些调整, 增加一些搜索内容

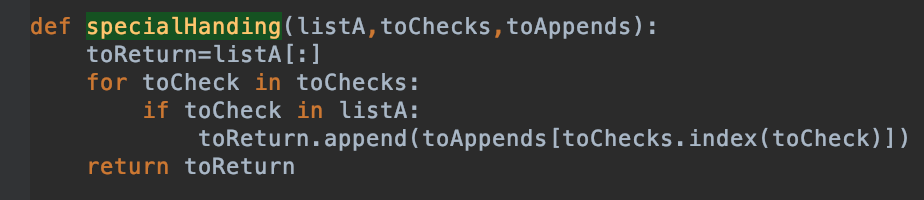
注意, 原神官网上没有荧和空, 需要特殊处理
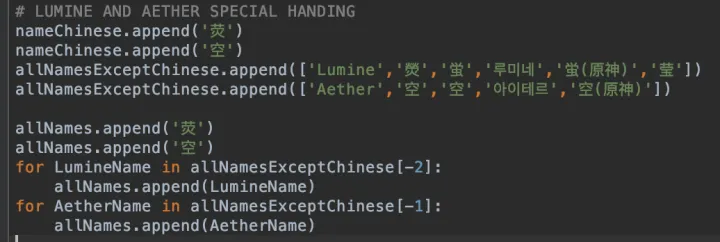
关于判断一个作品是不是和该原神角色相关, 我们的逻辑是如果在该作品中出现了其他原神角色的名字, 或者除本语言外的本角色名字, 或者出现一个在下面list中列出的元素, 就认为其和该原神角色相关.
注意忽略大小写.
judgeTag=[‘原神’,‘Genshin’,‘Impact’,‘米哈游’,‘米哈遊’,‘HoYoLAB’,‘원신’,‘HOYOVERSE’,‘miHoYo’,‘蒙德’,‘璃月’,‘须弥’,‘稻妻’,‘枫丹’,‘纳塔’,‘至冬’,‘提瓦特’,‘Mondstadt’,‘Liyue’,‘Inazuma’,‘Sumeru’,‘Fontaine’,‘Natlan’,‘Snezhnaya’,‘爷’,‘派蒙’,‘Paimon’,‘旅行者’,‘履刑者’,‘屑’,‘森林书’,‘兰纳罗’,‘双子’,‘愚人众’,‘Traveller’,‘Traveler’,‘雷音权现’,‘七星’,‘水’,‘火’,‘岩’,‘冰’,‘风’,‘雷’,‘草’,‘タル蛍’,‘雷电影’,‘雷电真’,‘雷電影’,‘黄金梦乡’,‘深渊’,‘Abyss’,‘七圣召唤’,‘Twins’,‘崩坏’,‘星穹铁道’,‘爱莉希雅’,‘Elysia’,‘女仆’,‘旅人’,‘Travel’,‘公子’,‘捷德’,‘风花节’,‘海灯节’,‘纠缠’,‘Wish’,‘Pull’,‘海祈岛’,‘珊瑚宫’,‘渊下宫’,‘尘歌’,‘萍姥姥’,‘龙脊雪山’,‘苍风高地’,‘风啸山坡’,‘明冠山地’,‘坠星山谷’,‘珉林’,‘璃沙郊’,‘云来海’,‘碧水原’,‘甜甜花’,‘层岩巨渊’,‘Status’,‘天理’,‘琪亚娜’,‘食岩之罚’,‘仙跳墙’,‘佛跳墙’,‘野菇鸡肉串’,‘珊瑚宫’,‘心海’,‘Pyro’,‘Cyro’,‘Hydro’,‘Nature’,‘Anemo’,‘Geo’,‘Dendro’,‘Electro’,‘Swirl’,‘原石’,‘Primogem’,‘Jade’,‘God’,‘Fate’,‘Intertwined’,‘纠缠之缘’,‘Serenitea’,‘Artifact’,‘圣遗物’,‘博士’,‘doctor’,‘同人’]
之后就是重头戏, 爬取Pixiv.
Pixiv不登录不给爬, 但是我们也得学会变通一点. 我们不要硬钢那个登录接口, 我们采取迂回的办法.
我们直接把我们登录后在浏览器看到的cookie复制下来, 写进header里面.
(至于为什么我用了好几个cookie, 我后面会讲)
有了cookie之后, 我们再爬取tags的时候才会返回正常内容.
不过注意, 内容并不是在网页HTML中返回的, 而是需要请求另外一个页面, 才会返回给我们有意义的内容.
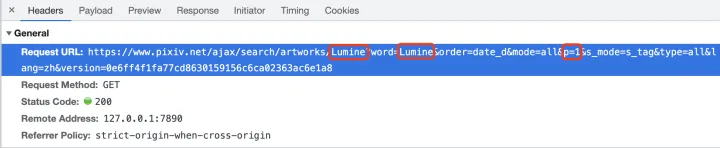
其中, 红圈圈出来的, 就表示需要请求的 tag 和 第几页.
具体来说, 我们就是要用装有cookie的header, 生成这个链接, 然后再请求, 这样才能取到有实际意义的内容.
这个链接很简单, 就用如下字符串拼接的方式生成.

requestURL='https://www.pixiv.net/ajax/search/artworks/'+name+'?word='+name+'&order=date_d&mode=all&p='+str(page)+'&s_mode=s_tag_full&type=all&lang=zh&version=1bb9c95cd9cbc108a16ddf9fea198f3210ac5053'

之后还需要load一下json
之后再用正则筛选出有用的信息

不过注意, Pixiv脾气并不是很好. 短时间请求的数量太多, 会返回空内容, 所以需要判断一下内容是不是为空.

同时, 如果那个tag下面就真的没有任何内容, 返回的也是空值.
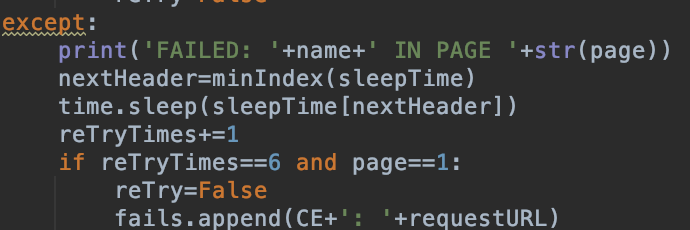
另外, 如果网络不好也可能收到空内容或者内容不全.
最后, 有时候网络是正常的, Pixiv也正常处理响应, 但是返回的内容就是不全, 或者返回了其他不完全相关的内容.
最后的最后, 当已经爬取完所有内容后, 再让 page+=1 爬取下一页的内容. Pixiv并不会返回404, 而是也返回空值.
还得注意, 返回的内容是有重复的, 这个也要考虑到.
如果自己写代码的话上面的问题都需要考虑, 我的代码中已经考虑并且测试通过了.
前面提到过, Pixiv爬取非常慢, 因此我们用多线程.

但是多线程就很容易被禁cookie, 因此我们搞多个cookie, 并且设计一套算法来决定到底用哪个cookie.
如果有一次请求不成功, 这个cookie的sleep time就加20秒.

换cookie的时候, 要睡眠对应cookie的睡眠时间
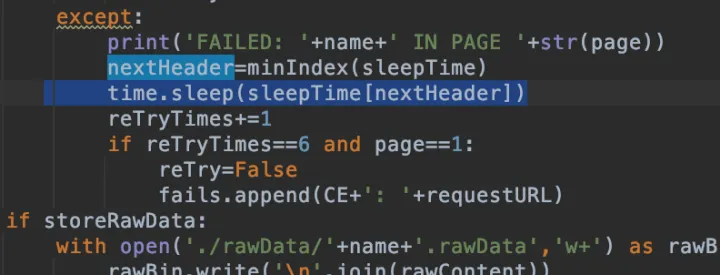
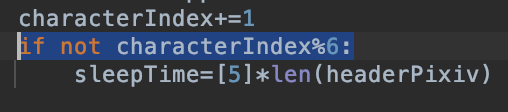
美成功处理完6个角色(所有语言的名字), 就要把睡眠时间重置. 免得最后退化成单cookie模式.
至于main.py跑完后的结果可视化, 那个讲起来太长了, 并且全都是matplotlib画图, 有问题的在评论区问我吧.