Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
本文简单的介绍了关于通过flink sql与kafka的进行交互的内容及相关示例。
本文依赖环境是hadoop、kafka环境好用,如果是ha环境则需要zookeeper的环境。
一、Table & SQL Connectors 示例:Apache Kafka
1、maven依赖(java编码依赖)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.1</version>
</dependency>
2、创建 Kafka 表
以下示例展示了如何创建 Kafka 表,分别使用了csv和json格式文件:
1)、csv格式文件示例
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
CREATE TABLE t1 (
`id` INT,
name STRING,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't_kafkasource',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'csv'
);
------kafka关于主题和发送数据命令
kafka-topics.sh --delete --topic t_kafkasource --bootstrap-server server1:9092
kafka-topics.sh --create --bootstrap-server server1:9092 --topic t_kafkasource --partitions 1 --replication-factor 1
kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
--测试数据
1,alan,15
2,alanchan,20
3,alanchanchn,25
4,alan_chan,30
5,alan_chan_chn,45
[root@server2 bin]# kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
>1,alan,15
>2,alanchan,20
>3,alanchanchn,25
>4,alan_chan,30
>5,alan_chan_chn,45
>
- flink sql查询结果
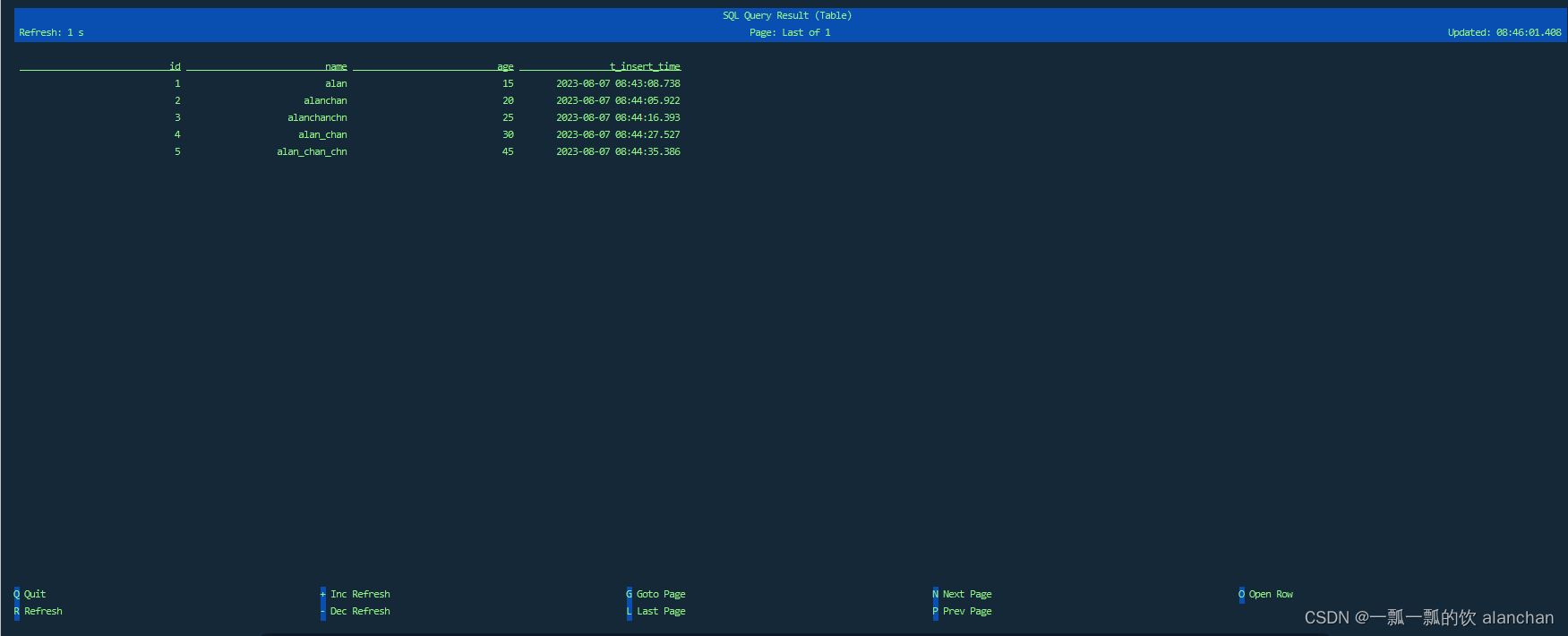
2)、csv格式文件示例
CREATE TABLE t2 (
`id` INT,
name string,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't_kafkasource_t2',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'json'
);
--------kafka关于主题和发送数据命令
kafka-topics.sh --delete --topic t_kafkasource_t2 --bootstrap-server server1:9092
kafka-topics.sh --create --bootstrap-server server1:9092 --topic t_kafkasource_t2 --partitions 1 --replication-factor 1
kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource_t2
----- 测试数据
{
"id":"1" ,"name":"alan","age":"12" }
{
"id":"2" ,"name":"alanchan","age":"22" }
{
"id":"3" ,"name":"alanchanchan","age":"32" }
{
"id":"4" ,"name":"alan_chan","age":"42" }
{
"id":"5" ,"name":"alan_chan_chn","age":"52" }
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource_t2
>{
"data": [{
"id":"1" ,"name":"alan","age":"12" } ]}
>{
"id":"1" ,"name":"alan","age":"12" }
>{
"id":"2" ,"name":"alanchan","age":"22" }
>{
"id":"3" ,"name":"alanchanchan","age":"32" }
>{
"id":"4" ,"name":"alan_chan","age":"42" }
>{
"id":"5" ,"name":"alan_chan_chn","age":"52" }
>
- Flink sql 查询结果
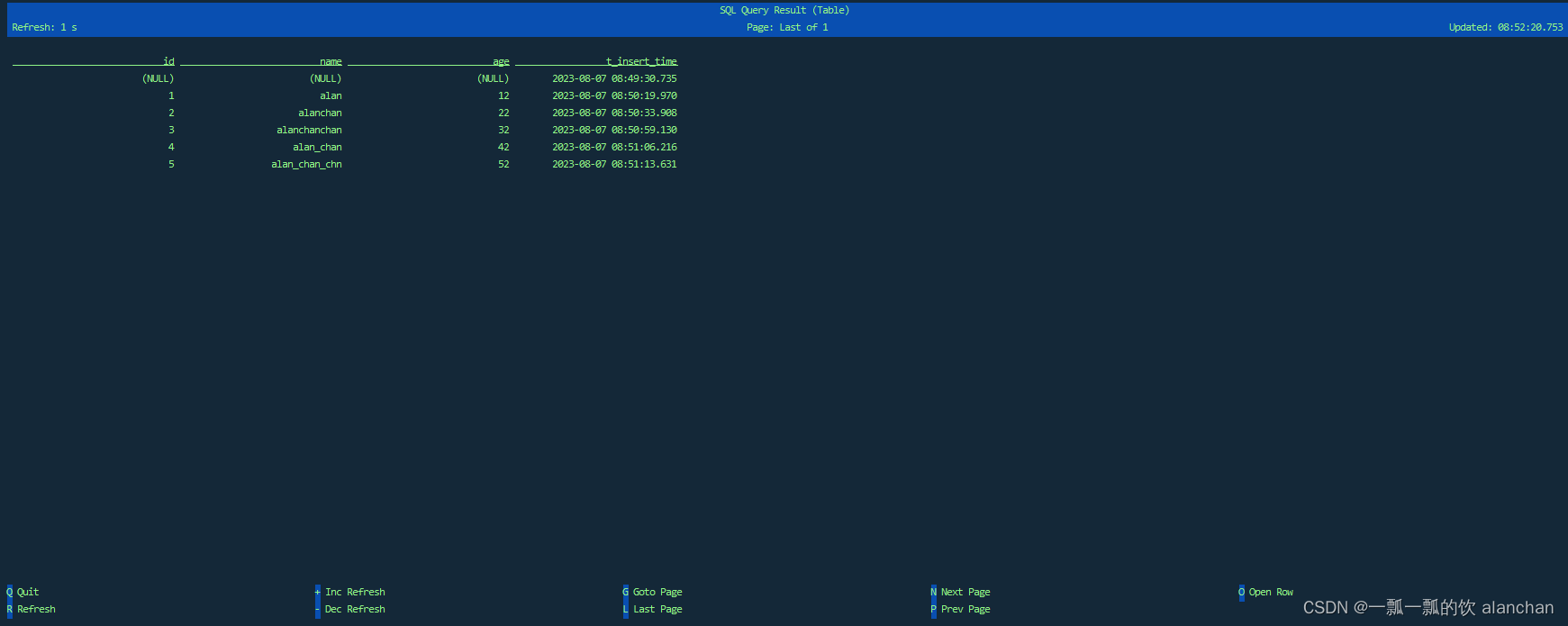
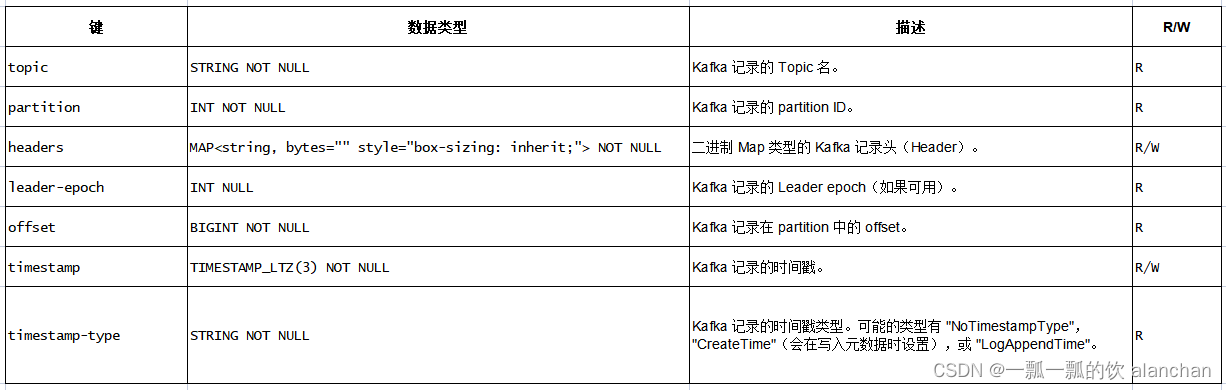
3、可用的元数据
以下的连接器元数据可以在表定义中通过元数据列的形式获取。
R/W 列定义了一个元数据是可读的(R)还是可写的(W)。 只读列必须声明为 VIRTUAL 以在 INSERT INTO 操作中排除它们。
以下扩展的 CREATE TABLE 示例展示了使用这些元数据字段的语法:
CREATE TABLE Alan_KafkaTable_1 (
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
---------------------------------验证--------------------------------
Flink SQL> CREATE TABLE Alan_KafkaTable_1 (
> `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
> `partition` BIGINT METADATA VIRTUAL,
> `offset` BIGINT METADATA VIRTUAL,
> `user_id` BIGINT,
> `item_id` BIGINT,
> `behavior` STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'user_behavior',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.
Flink SQL> desc Alan_KafkaTable_1;
+------------+--------------+------+-----+---------------------------+-----------+
| name | type | null | key | extras | watermark |
+------------+--------------+------+-----+---------------------------+-----------+
| event_time | TIMESTAMP(3) | true | | METADATA FROM 'timestamp' | |
| partition | BIGINT | true | | METADATA VIRTUAL | |
| offset | BIGINT | true | | METADATA VIRTUAL | |
| user_id | BIGINT | true | | | |
| item_id | BIGINT | true | | | |
| behavior | STRING | true | | | |
+------------+--------------+------+-----+---------------------------+-----------+
6 rows in set
---kafka发送数据
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic user_behavior
>1,1001,login
>1,2001,p_read
----flink sql 查询结果
Flink SQL> select * from Alan_KafkaTable_1;
2023-08-21 05:40:38,916 INFO org.apache.hadoop.yarn.client.AHSProxy [] - Connecting to Application History server at server1/192.168.10.41:10200
2023-08-21 05:40:38,916 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2023-08-21 05:40:38,919 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface server4:40896 of application 'application_1688448920799_0009'.
+----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
| op | event_time | partition | offset | user_id | item_id | behavior |
+----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
| +I | 2023-08-21 05:38:47.009 | 0 | 0 | 1 | 1001 | login |
| +I | 2023-08-21 05:39:03.994 | 0 | 1 | 1 | 2001 | p_read |
连接器可以读出消息格式的元数据。格式元数据的配置键以 ‘value.’ 作为前缀。
以下示例展示了如何获取 Kafka 和 Debezium 的元数据字段:
CREATE TABLE KafkaTable (
`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL, -- from Kafka connector
`offset` BIGINT METADATA VIRTUAL, -- from Kafka connector
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json'
);
--------------------验证--------------------------------------
Flink SQL> CREATE TABLE Alan_KafkaTable_2 (
> `event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
> `origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
> `partition_id` BIGINT METADATA FROM 'partition' VIRTUAL, -- from Kafka connector
> `offset` BIGINT METADATA VIRTUAL, -- from Kafka connector
> `user_id` BIGINT,
> `item_id` BIGINT,
> `behavior` STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'user_behavior2',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'value.format' = 'debezium-json'
> );
[INFO] Execute statement succeed.
Flink SQL> desc Alan_KafkaTable_2;
+--------------+--------------+------+-----+------------------------------------------------+-----------+
| name | type | null | key | extras | watermark |
+--------------+--------------+------+-----+------------------------------------------------+-----------+
| event_time | TIMESTAMP(3) | true | | METADATA FROM 'value.source.timestamp' VIRTUAL | |
| origin_table | STRING | true | | METADATA FROM 'value.source.table' VIRTUAL | |
| partition_id | BIGINT | true | | METADATA FROM 'partition' VIRTUAL | |
| offset | BIGINT | true | | METADATA VIRTUAL | |
| user_id | BIGINT | true | | | |
| item_id | BIGINT | true | | | |
| behavior | STRING | true | | | |
+--------------+--------------+------+-----+------------------------------------------------+-----------+
7 rows in set
-----测试数据
{
"before": null,
"after": {
"user_id": 1,
"item_id": "1001",
"behavior": "login"
},
"source": {
"version": "1.13.5"},
"op": "c",
"ts_ms": 1692593500222,
"transaction": null
}
{
"before": {
"user_id": 1,
"item_id": "1001",
"behavior": "login"
},
"after": {
"user_id": 1,
"item_id": "2001",
"behavior": "p_read"
},
"source": {
"version": "1.13.5"},
"op": "u",
"ts_ms": 1692593502242,
"transaction": null
}
---kafka发送数据
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic user_behavior2
>{ "before": null, "after": { "user_id": 1, "item_id": "1001", "behavior": "login" }, "source": {
"version": "1.13.5"}, "op": "c", "ts_ms": 1692593500222, "transaction": null}
>{ "before": { "user_id": 1, "item_id": "1001", "behavior": "login" }, "after": { "user_id": 1, "item_id": "2001", "behavior": "p_read" }, "source": {
"version": "1.13.5"}, "op": "u", "ts_ms": 1692593502242, "transaction": null}
>
----flink sql 查询结果,没有获取到debezium的元数据,是因为测试环境没有debezium运行环境,由于该种方式基本上被Flink CDC取代,故不做深入的验证
Flink SQL> select * from Alan_KafkaTable_2;
2023-08-21 06:43:59,445 INFO org.apache.hadoop.yarn.client.AHSProxy [] - Connecting to Application History server at server1/192.168.10.41:10200
2023-08-21 06:43:59,445 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2023-08-21 06:43:59,449 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface server4:40896 of application 'application_1688448920799_0009'.
+----+-------------------------+--------------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
| op | event_time | origin_table | partition_id | offset | user_id | item_id | behavior |
+----+-------------------------+--------------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
| +I | (NULL) | (NULL) | 0 | 0 | 1 | 1001 | login |
| -U | (NULL) | (NULL) | 0 | 1 | 1 | 1001 | login |
| +U | (NULL) | (NULL) | 0 | 1 | 1 | 2001 | p_read |
4、连接器参数
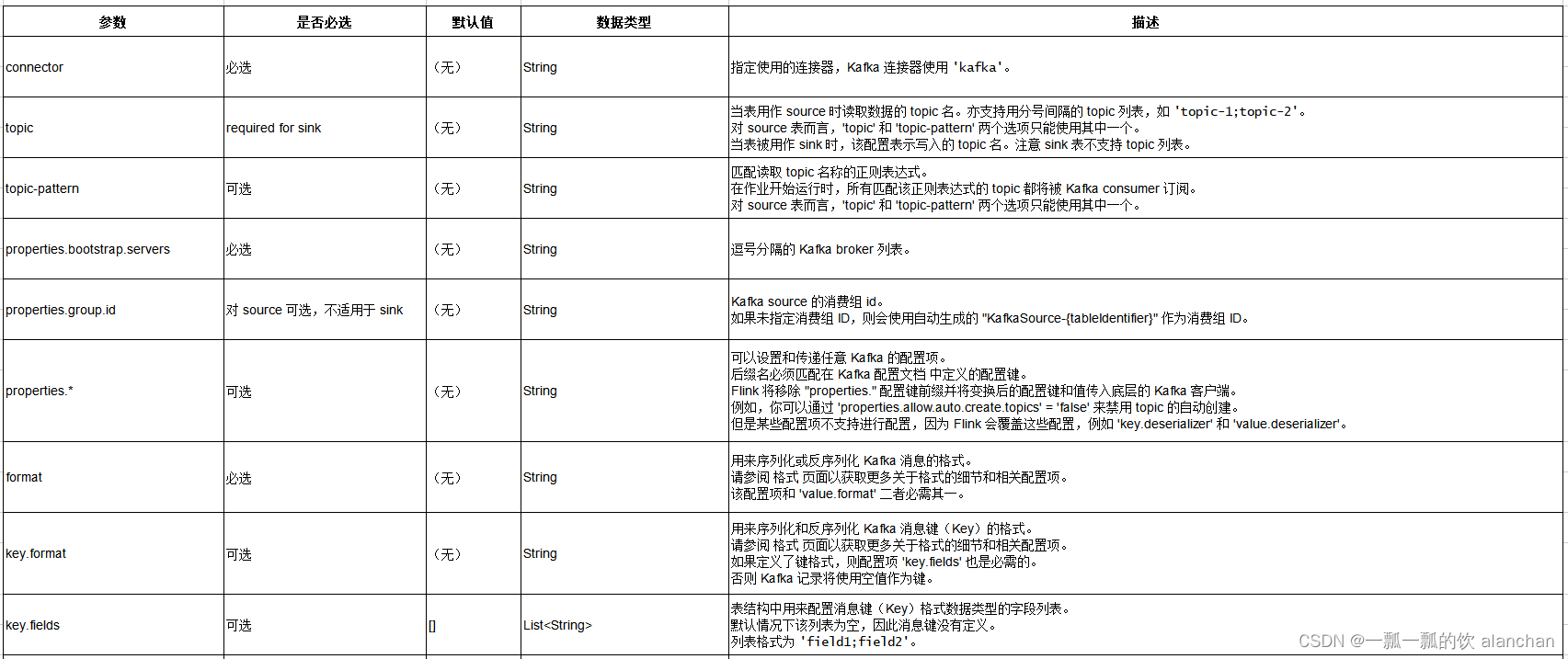
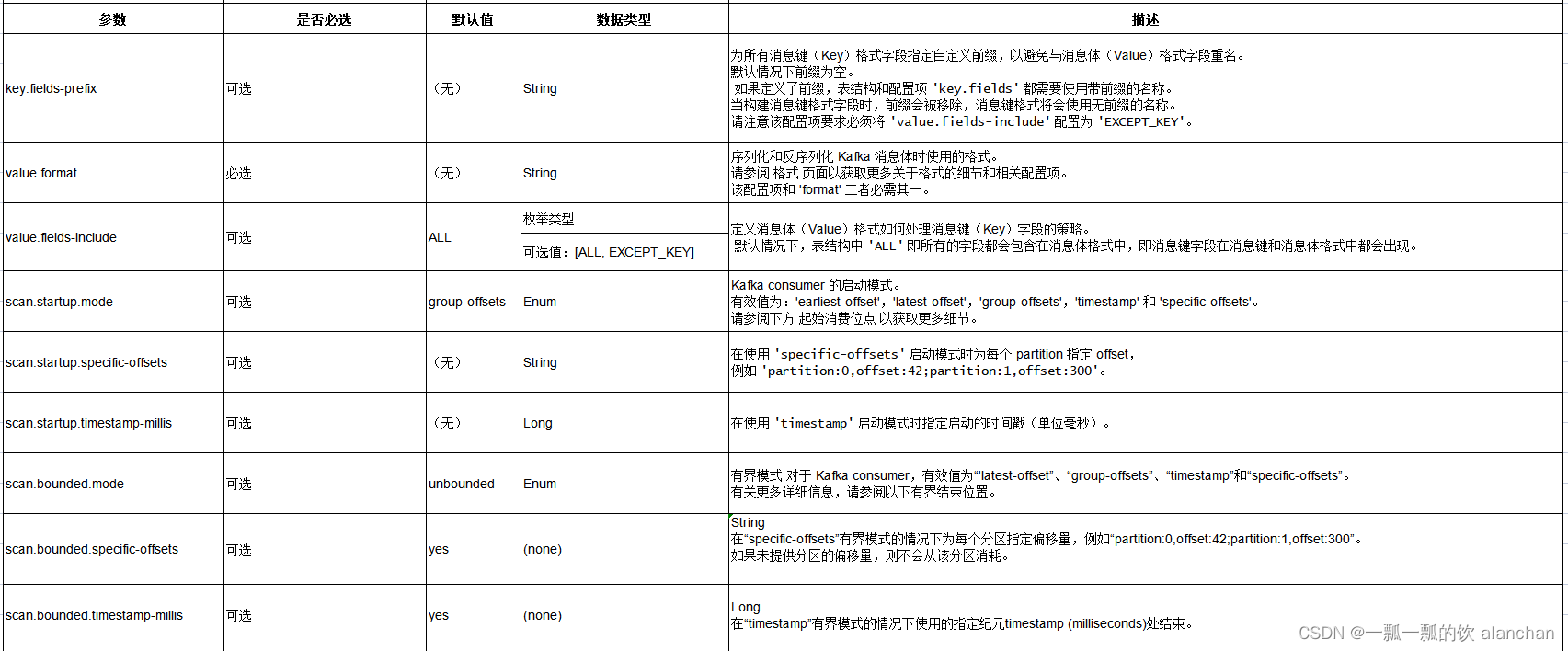
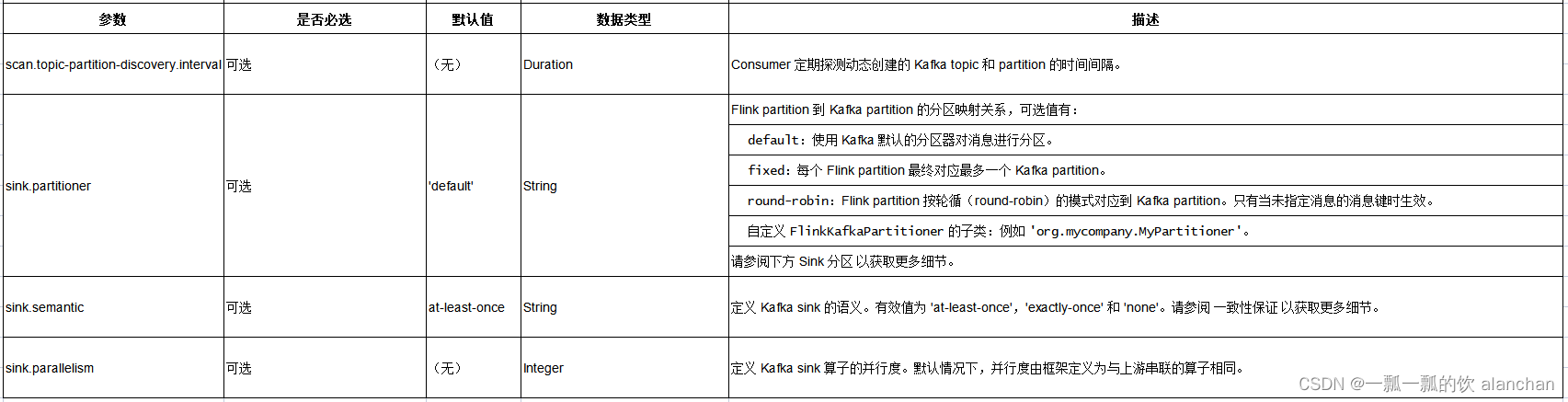
上图中的格式请参考链接:35、Flink 的JSON Format
5、特性
1)、消息键(Key)与消息体(Value)的格式
Kafka 消息的消息键和消息体部分都可以使用某种 35、Flink 的JSON Format 来序列化或反序列化成二进制数据。
1、消息体格式
由于 Kafka 消息中消息键是可选的,以下语句将使用消息体格式读取和写入消息,但不使用消息键格式。 ‘format’ 选项与 ‘value.format’ 意义相同。 所有的格式配置使用格式识别符作为前缀。
CREATE TABLE KafkaTable (
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
...
'format' = 'json',
'json.ignore-parse-errors' = 'true'
)
消息体格式将配置为以下的数据类型:
ROW<`user_id` BIGINT, `item_id` BIGINT, `behavior` STRING>
2、消息键和消息体格式
以下示例展示了如何配置和使用消息键和消息体格式。 格式配置使用 ‘key’ 或 ‘value’ 加上格式识别符作为前缀。
CREATE TABLE KafkaTable (
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
...
'key.format' = 'json',
'key.json.ignore-parse-errors' = 'true',
'key.fields' = 'user_id;item_id',
'value.format' = 'json',
'value.json.fail-on-missing-field' = 'false',
'value.fields-include' = 'ALL'
)
消息键格式包含了在 ‘key.fields’ 中列出的字段(使用 ‘;’ 分隔)和字段顺序。 因此将配置为以下的数据类型:
ROW<`user_id` BIGINT, `item_id` BIGINT>
由于消息体格式配置为 ‘value.fields-include’ = ‘ALL’,所以消息键字段也会出现在消息体格式的数据类型中:
ROW<`user_id` BIGINT, `item_id` BIGINT, `behavior` STRING>
3、重名的格式字段
如果消息键字段和消息体字段重名,连接器无法根据表结构信息将这些列区分开。 ‘key.fields-prefix’ 配置项可以在表结构中为消息键字段指定一个唯一名称,并在配置消息键格式的时候保留原名。
以下示例展示了在消息键和消息体中同时包含 version 字段的情况:
CREATE TABLE KafkaTable (
`k_version` INT,
`k_user_id` BIGINT,
`k_item_id` BIGINT,
`version` INT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
...
'key.format' = 'json',
'key.fields-prefix' = 'k_',
'key.fields' = 'k_version;k_user_id;k_item_id',
'value.format' = 'json',
'value.fields-include' = 'EXCEPT_KEY'
)
消息体格式必须配置为 ‘EXCEPT_KEY’ 模式。格式将被配置为以下的数据类型:
# 消息键格式:
ROW<`version` INT, `user_id` BIGINT, `item_id` BIGINT>
# 消息体格式:
ROW<`version` INT, `behavior` STRING>
2)、Topic 和 Partition 的探测
topic 和 topic-pattern 配置项决定了 source 消费的 topic 或 topic 的匹配规则。topic 配置项可接受使用分号间隔的 topic 列表,例如 topic-1;topic-2。 topic-pattern 配置项使用正则表达式来探测匹配的 topic。例如 topic-pattern 设置为 test-topic-[0-9],则在作业启动时,所有匹配该正则表达式的 topic(以 test-topic- 开头,以一位数字结尾)都将被 consumer 订阅。
为允许 consumer 在作业启动之后探测到动态创建的 topic,请将 scan.topic-partition-discovery.interval 配置为一个非负值。这将使 consumer 能够探测匹配名称规则的 topic 中新的 partition。
请参阅 37、Flink 的Apache Kafka connector 以获取更多关于 topic 和 partition 探测的信息。
topic 列表和 topic 匹配规则只适用于 source。对于 sink 端,Flink 目前只支持单一 topic。
3)、起始消费位点
scan.startup.mode 配置项决定了 Kafka consumer 的启动模式。有效值为:
- group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。
- earliest-offset:从可能的最早偏移量开始。
- latest-offset:从最末尾偏移量开始。
- timestamp:从用户为每个 partition 指定的时间戳开始。
- specific-offsets:从用户为每个 partition 指定的偏移量开始。
默认值 group-offsets 表示从 Zookeeper/Kafka 中最近一次已提交的偏移量开始消费。
如果使用了 timestamp,必须使用另外一个配置项 scan.startup.timestamp-millis 来指定一个从格林尼治标准时间 1970 年 1 月 1 日 00:00:00.000 开始计算的毫秒单位时间戳作为起始时间。
如果使用了 specific-offsets,必须使用另外一个配置项 scan.startup.specific-offsets 来为每个 partition 指定起始偏移量, 例如,选项值 partition:0,offset:42;partition:1,offset:300 表示 partition 0 从偏移量 42 开始,partition 1 从偏移量 300 开始。
4)、Bounded Ending Position
配置选项 scan.bounded.mode 指定 Kafka 使用者的有界模式。有效的枚举为:
- “group-offsets”:以特定消费者组的 ZooKeeper/Kafka 代理中的已提交偏移量为界。这是在给定分区的使用开始时评估的。
- “latest-offset”:以最新偏移量为界。这是在给定分区的使用开始时评估的。
- “timestamp”:以用户提供的时间戳为界。
- “specific-offsets”:以用户为每个分区提供的特定偏移量为界。
如果未设置配置选项值 scan.bounded.mode,则默认值为无界表。
如果指定了时间戳,则需要另一个配置选项 scan.bounded.timestamp-millis 来指定自 1970 年 1 月 1 日 00:00:00.000 GMT 以来的特定有界时间戳(以毫秒为单位)。
如果指定了特定偏移量,则需要另一个配置选项 scan.bounded.specific-offset 来为每个分区指定特定的有界偏移量,例如,选项值 partition:0,offset:42;partition:1,offset:300 表示分区 0 的偏移量为 42,分区 1 的偏移量为 300。如果未提供分区的偏移量,则不会从该分区消耗。
5)、CDC 变更日志(Changelog) Source
Flink 原生支持使用 Kafka 作为 CDC 变更日志(changelog) source。如果 Kafka topic 中的消息是通过变更数据捕获(CDC)工具从其他数据库捕获的变更事件,则你可以使用 CDC 格式将消息解析为 Flink SQL 系统中的插入(INSERT)、更新(UPDATE)、删除(DELETE)消息。
在许多情况下,变更日志(changelog) source 都是非常有用的功能,例如将数据库中的增量数据同步到其他系统,审核日志,数据库的物化视图,时态表关联数据库表的更改历史等。
Flink 提供了几种 CDC 格式:
6)、Sink 分区
配置项 sink.partitioner 指定了从 Flink 分区到 Kafka 分区的映射关系。 默认情况下,Flink 使用 Kafka 默认分区器 来对消息分区。默认分区器对没有消息键的消息使用 粘性分区策略(sticky partition strategy) 进行分区,对含有消息键的消息使用 murmur2 哈希算法计算分区。
为了控制数据行到分区的路由,也可以提供一个自定义的 sink 分区器。‘fixed’ 分区器会将同一个 Flink 分区中的消息写入同一个 Kafka 分区,从而减少网络连接的开销。
7)、一致性保证
默认情况下,如果查询在 启用 checkpoint 模式下执行时,Kafka sink 按照至少一次(at-lease-once)语义保证将数据写入到 Kafka topic 中。
当 Flink checkpoint 启用时,kafka 连接器可以提供精确一次(exactly-once)的语义保证。
除了启用 Flink checkpoint,还可以通过传入对应的 sink.semantic 选项来选择三种不同的运行模式:
- none:Flink 不保证任何语义。已经写出的记录可能会丢失或重复。
- at-least-once (默认设置):保证没有记录会丢失(但可能会重复)。
- exactly-once:使用 Kafka 事务提供精确一次(exactly-once)语义。当使用事务向 Kafka 写入数据时,请将所有从 Kafka 中消费记录的应用中的 isolation.level 配置项设置成实际所需的值(read_committed 或 read_uncommitted,后者为默认值)。
请参阅 37、Flink 的Apache Kafka connector 以获取更多关于语义保证的信息。
8)、Source 按分区 Watermark
Flink 对于 Kafka 支持发送按分区的 watermark。Watermark 在 Kafka consumer 中生成。 按分区 watermark 的合并方式和在流 shuffle 时合并 Watermark 的方式一致。 Source 输出的 watermark 由读取的分区中最小的 watermark 决定。 如果 topic 中的某些分区闲置,watermark 生成器将不会向前推进。 你可以在表配置中设置 ‘table.exec.source.idle-timeout’ 选项来避免上述问题。
请参阅 7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现) 策略 以获取更多细节。
9)、安全
要启用加密和认证相关的安全配置,只需将安全配置加上 “properties.” 前缀配置在 Kafka 表上即可。下面的代码片段展示了如何配置 Kafka 表以使用 PLAIN 作为 SASL 机制并提供 JAAS 配置:
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
...
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";'
)
另一个更复杂的例子,使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制:
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
...
'properties.security.protocol' = 'SASL_SSL',
/* SSL 配置 */
/* 配置服务端提供的 truststore (CA 证书) 的路径 */
'properties.ssl.truststore.location' = '/path/to/kafka.client.truststore.jks',
'properties.ssl.truststore.password' = 'test1234',
/* 如果要求客户端认证,则需要配置 keystore (私钥) 的路径 */
'properties.ssl.keystore.location' = '/path/to/kafka.client.keystore.jks',
'properties.ssl.keystore.password' = 'test1234',
/* SASL 配置 */
/* 将 SASL 机制配置为 as SCRAM-SHA-256 */
'properties.sasl.mechanism' = 'SCRAM-SHA-256',
/* 配置 JAAS */
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";'
)
如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置。例如在 SQL client JAR 中,Kafka client 依赖被重置在了 org.apache.flink.kafka.shaded.org.apache.kafka 路径下, 因此 plain 登录模块的类路径应写为 org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule。
关于安全配置的详细描述,请参阅 Apache Kafka 文档中的"安全"一节。
6、数据类型映射
Kafka 将消息键值以二进制进行存储,因此 Kafka 并不存在 schema 或数据类型。Kafka 消息使用格式配置进行序列化和反序列化,例如 csv,json,avro。 因此,数据类型映射取决于使用的格式。请参阅 格式 页面以获取更多细节。
以上,简单的介绍了关于通过flink sql与kafka的进行交互的内容。