文章目录
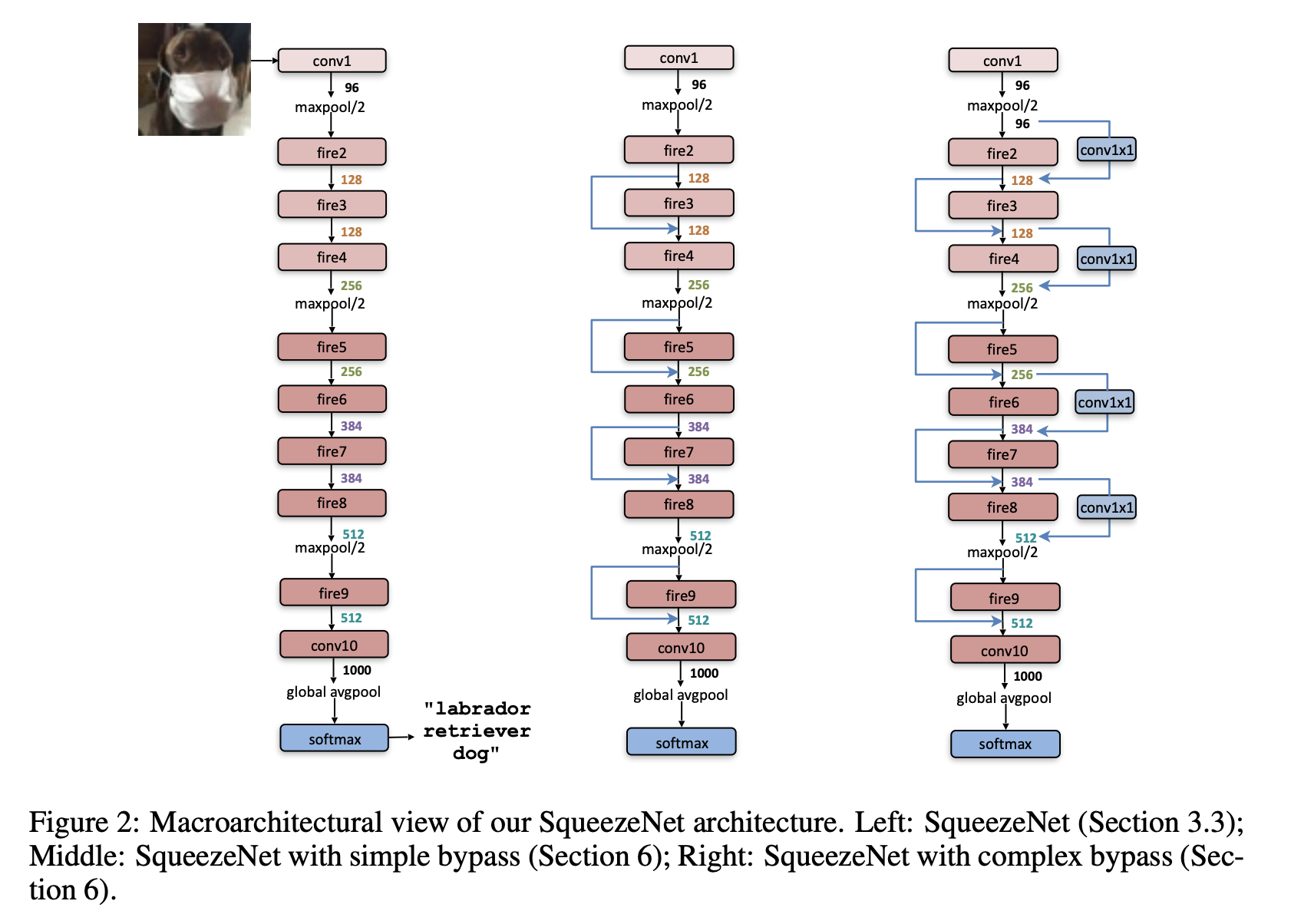
一、SqueezeNet
SqueezeNet 是一种卷积神经网络,它采用设计策略来减少参数数量,特别是使用使用 1x1 卷积“压缩”参数的 fire 模块。
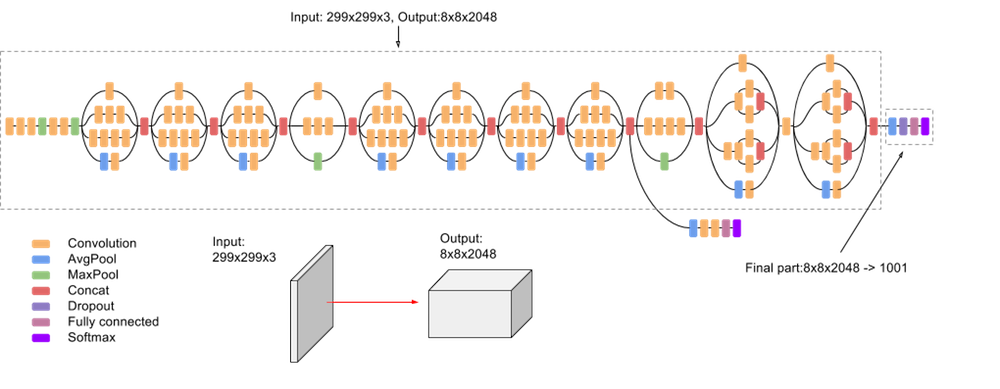
二、Inception-v3
Inception-v3 是 Inception 系列中的一种卷积神经网络架构,它进行了多项改进,包括使用标签平滑、因式分解 7 x 7 卷积以及使用辅助分类器在网络下方传播标签信息(以及使用批处理) 侧头中各层的标准化)。
三、Visual Geometry Group 19 Layer CNN
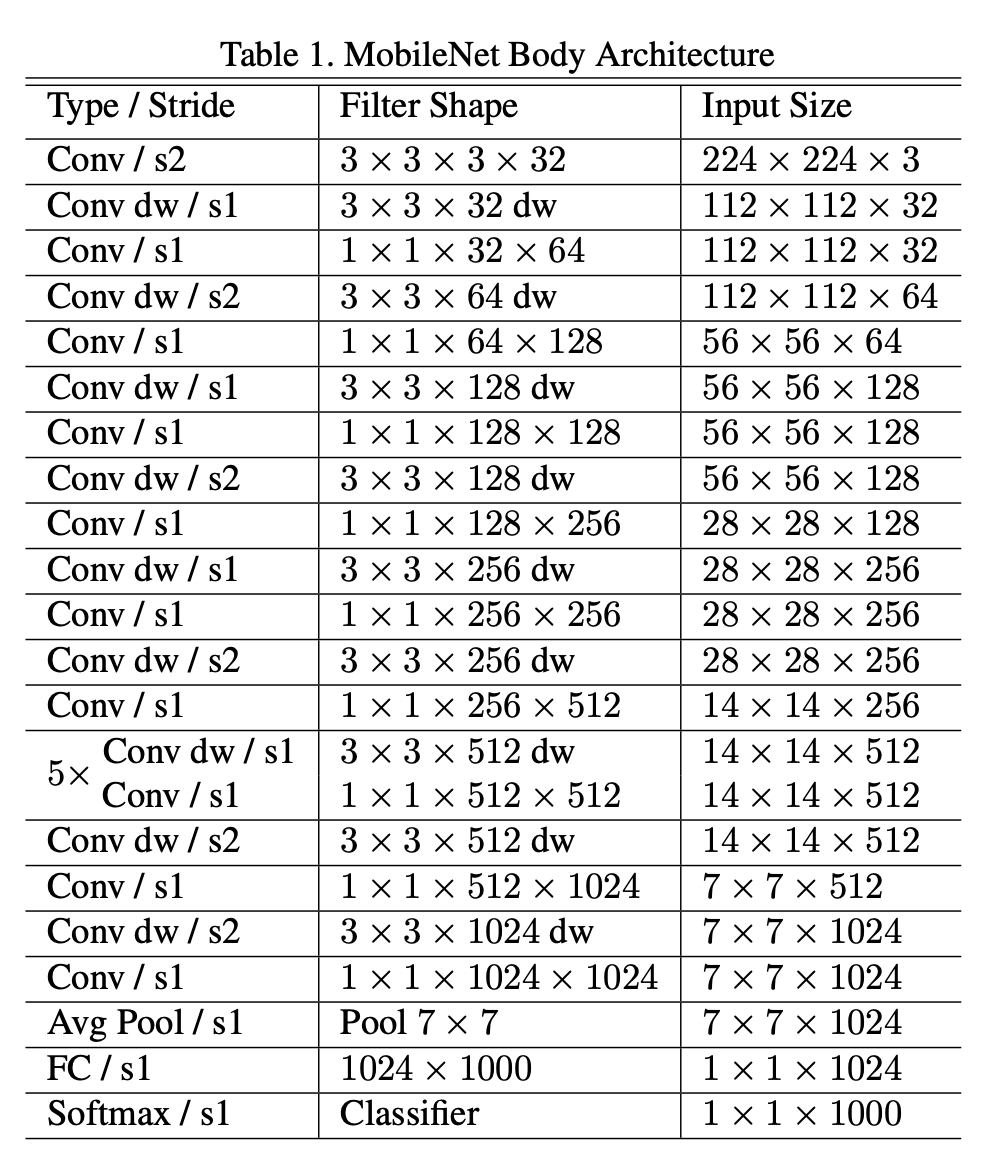
四、MobileNetV1
MobileNet 是一种专为移动和嵌入式视觉应用而设计的卷积神经网络。 它们基于简化的架构,该架构使用深度可分离卷积来构建轻量级深度神经网络,该网络可以为移动和嵌入式设备提供低延迟。
五、Data-efficient Image Transformer
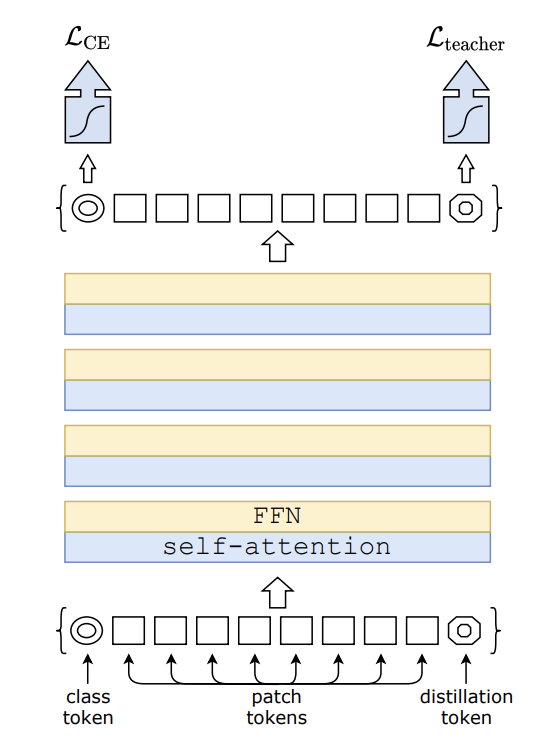
数据高效图像转换器是一种用于图像分类任务的视觉转换器。 该模型使用 Transformer 特有的师生策略进行训练。 它依赖于蒸馏令牌,确保学生通过注意力向老师学习。
六、MobileNetV3
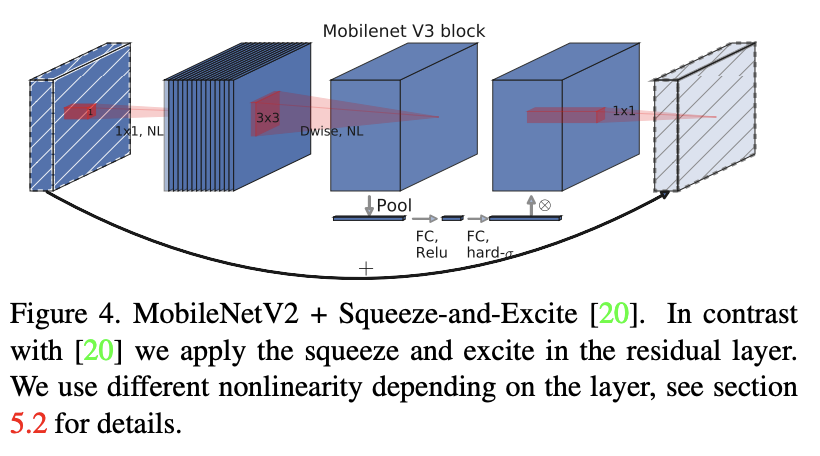
MobileNetV3 是一种卷积神经网络,通过结合硬件感知网络架构搜索 (NAS) 和 NetAdapt 算法进行调整,以适应手机 CPU,然后通过新颖的架构进步进行改进。 进步包括(1)互补搜索技术,(2)适用于移动环境的新的高效非线性版本,(3)新的高效网络设计。
网络设计包括在 MBConv 块中使用硬刷激活和挤压和激励模块。
七、self-DIstillation with NO labels(DINO)
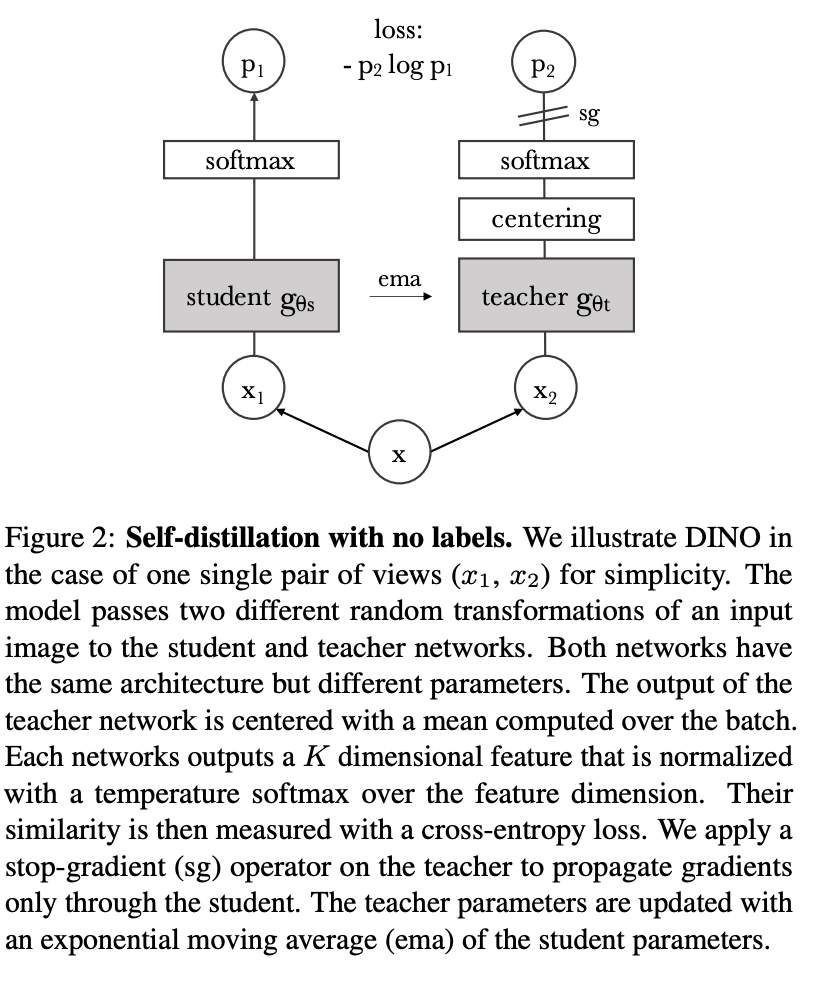
DINO(无标签自蒸馏)是一种自监督学习方法,它使用标准交叉熵损失直接预测由动量编码器构建的教师网络的输出。
在右侧的示例中,DINO 在一对视图的情况下进行了说明为了简单起见。 该模型将输入图像的两种不同的随机变换传递给学生和教师网络。 两个网络具有相同的架构,但参数不同。 教师网络的输出以批次计算的平均值为中心。 每个网络输出一个使用特征维度上的温度 softmax 标准化维度特征。 然后用交叉熵损失来测量它们的相似性。 对教师应用停止梯度 (sg) 运算符,以仅通过学生传播梯度。 教师参数使用学生参数的指数移动平均值 (ema) 进行更新
八、MLP-Mixer
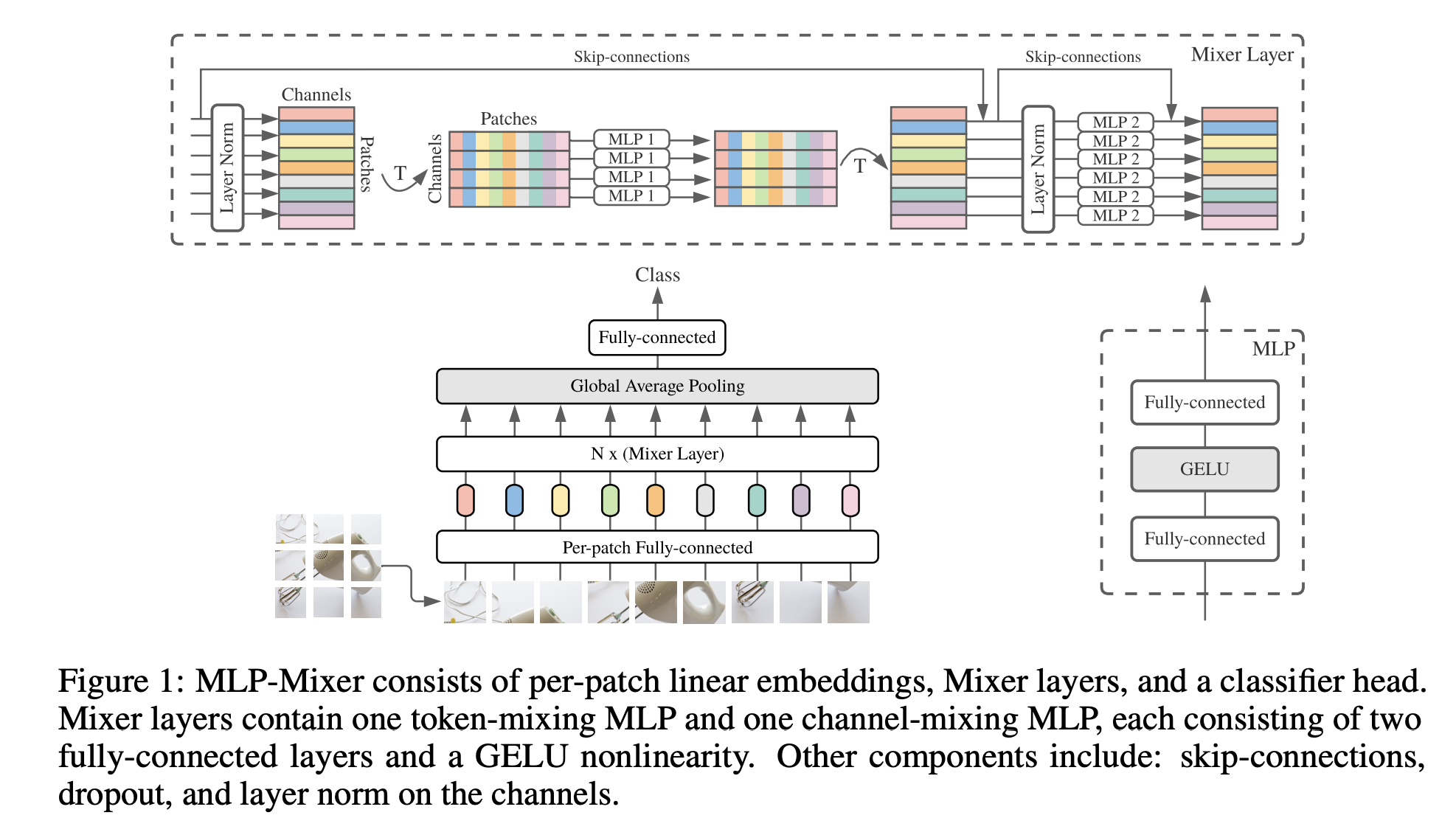
MLP-Mixer 架构(或简称“Mixer”)是一种不使用卷积或自注意力的图像架构。 相反,Mixer 的架构完全基于多层感知器 (MLP),这些感知器在空间位置或特征通道上重复应用。 Mixer 仅依赖于基本的矩阵乘法例程、数据布局的更改(重塑和转置)以及标量非线性。
它接受一系列线性投影图像块(也称为令牌),形状为“块×通道”表作为输入,并维护该维度。 Mixer 使用两种类型的 MLP 层:通道混合 MLP 和令牌混合 MLP。 通道混合 MLP 允许不同通道之间进行通信; 它们独立地对每个标记进行操作,并将表的各个行作为输入。 令牌混合 MLP 允许不同空间位置(令牌)之间进行通信; 它们独立地在每个通道上运行,并将表的各个列作为输入。 这两种类型的层交错以实现两个输入维度的交互。
九、WideResNet
宽残差网络是 ResNet 的变体,我们减少残差网络的深度并增加残差网络的宽度。 这是通过使用宽残差块来实现的。
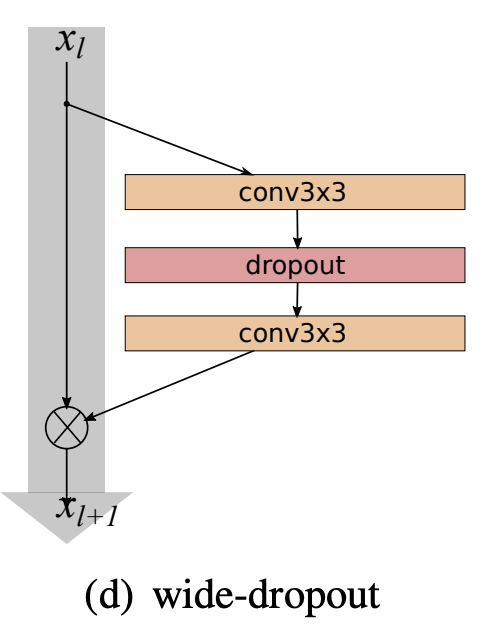
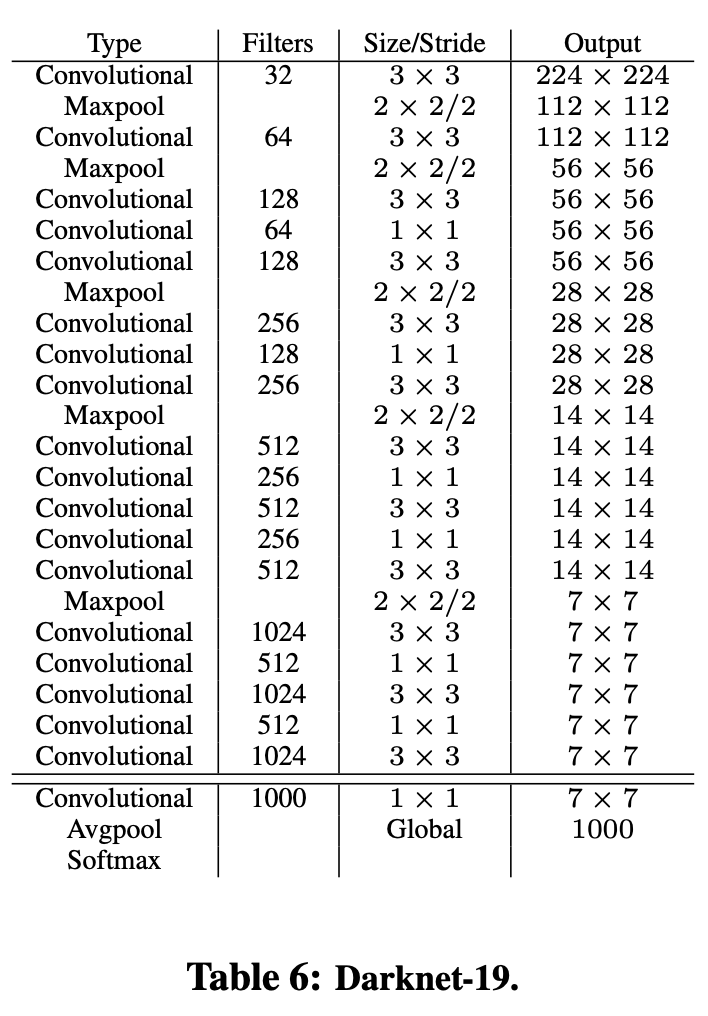
十、Darknet-19

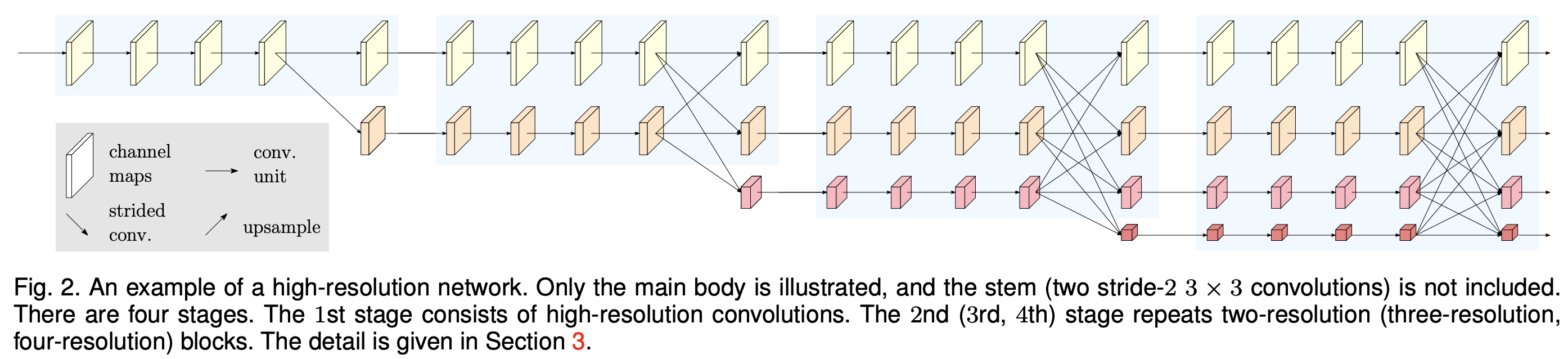
十一、HRNet
HRNet(即高分辨率网络)是一种通用卷积神经网络,用于语义分割、对象检测和图像分类等任务。 它能够在整个过程中保持高分辨率表示。 我们从高分辨率卷积流开始,逐渐逐一添加高分辨率到低分辨率的卷积流,并将多分辨率流并行连接。作者通过一遍又一遍地交换并行流中的信息来进行重复的多分辨率融合。
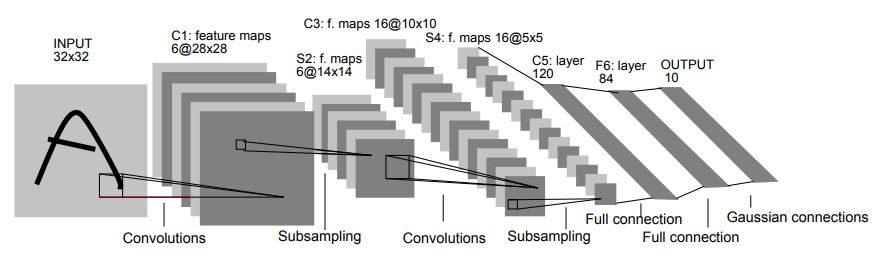
十二、LeNet
LeNet 是一种经典的卷积神经网络,采用卷积、池化和全连接层。 它用于 MNIST 数据集的手写数字识别任务。 该架构设计为 AlexNet 和 VGG 等未来网络提供了灵感。
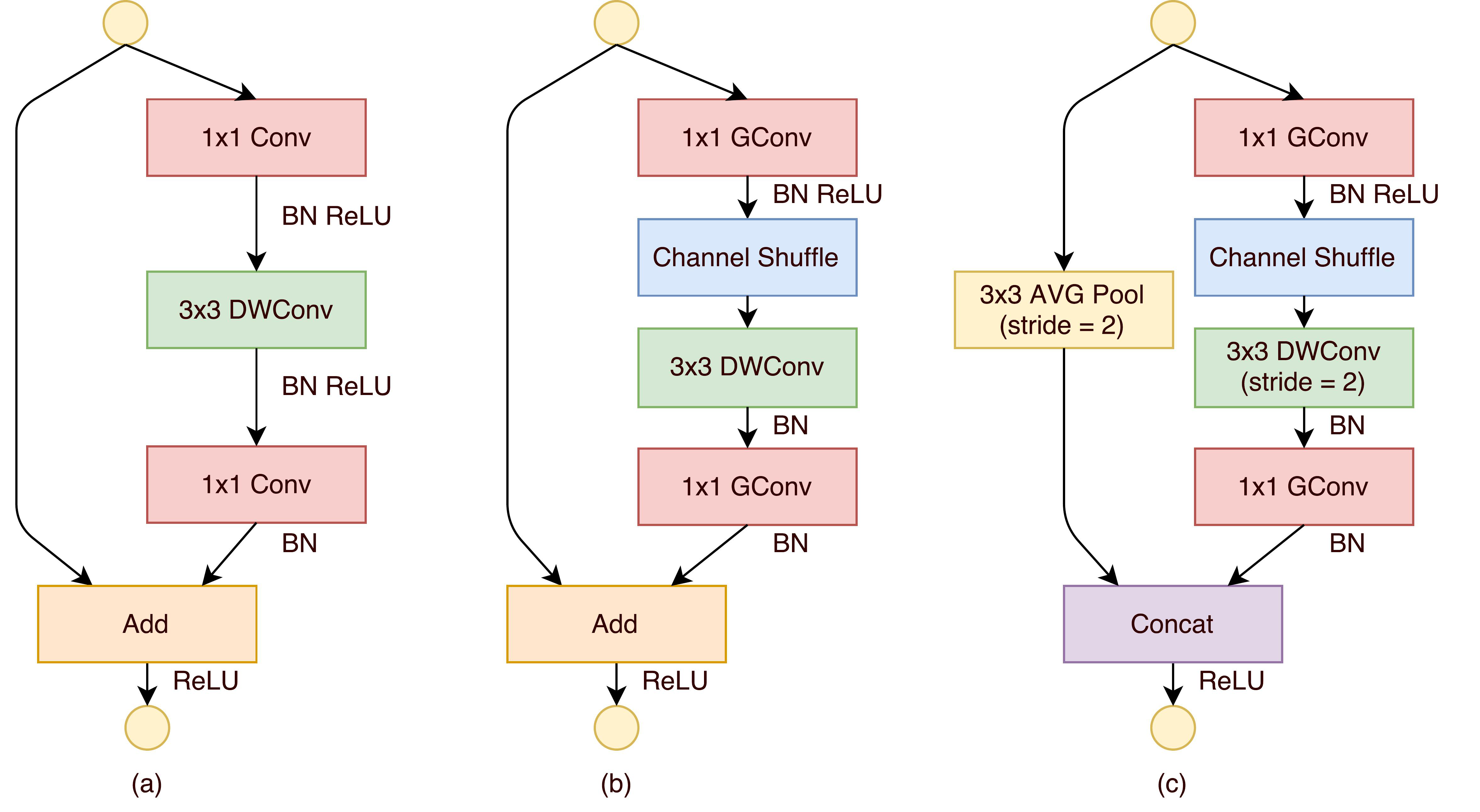
十三、ShuffleNet
ShuffleNet 是一种专门为计算能力非常有限的移动设备设计的卷积神经网络。 该架构利用两种新操作,即逐点组卷积和通道洗牌,在保持准确性的同时降低计算成本。
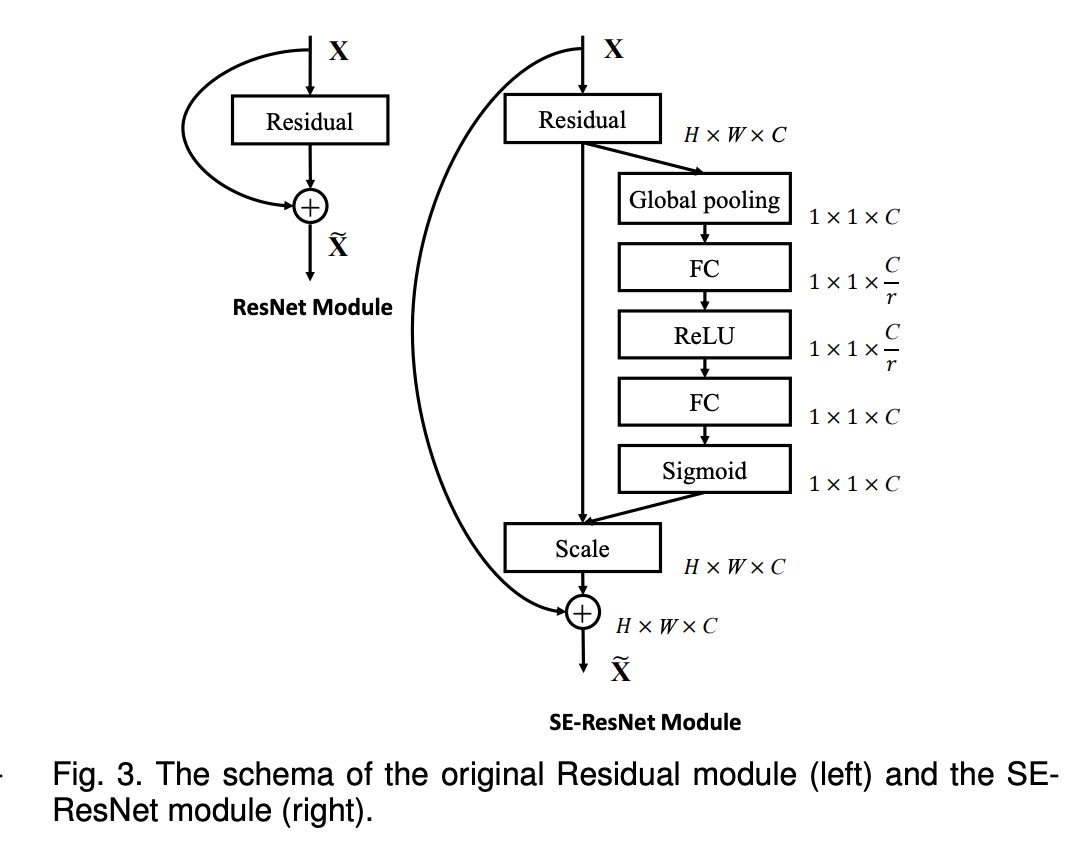
十四、SENet
SENet 是一种卷积神经网络架构,它采用挤压和激励块使网络能够执行动态通道特征重新校准。
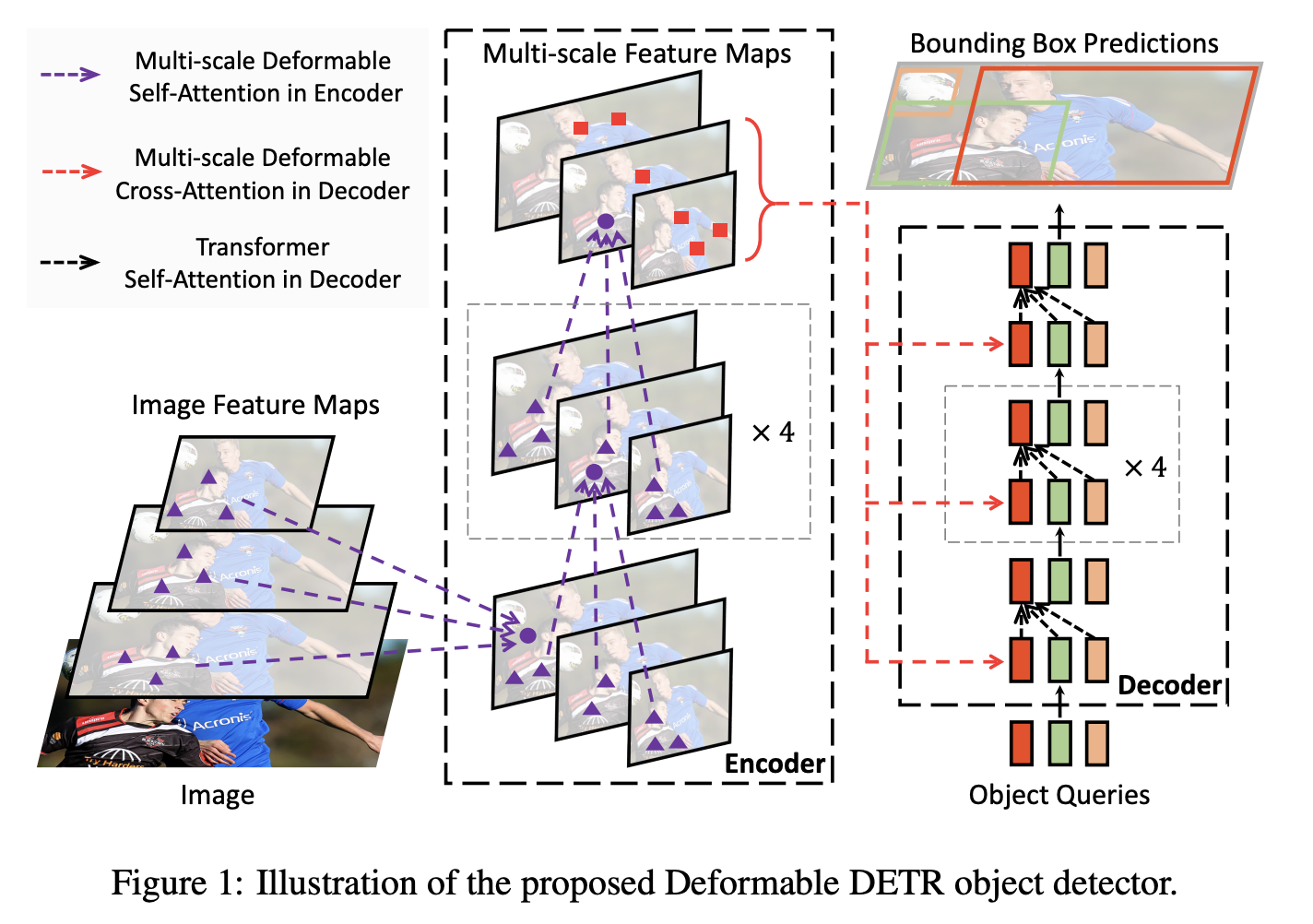
十五、Deformable DETR
可变形 DETR 是一种目标检测方法,旨在缓解 DETR 收敛速度慢和复杂度高的问题。 它结合了可变形卷积的稀疏空间采样和 Transformers 的关系建模功能的最佳性能。 具体来说,它引入了一个可变形注意模块,该模块关注一小组采样位置,作为所有特征图像素中突出关键元素的预过滤器。 该模块可以自然地扩展到聚合多尺度特征,而无需借助 FPN。