最近工作中遇到了一些数据建模的问题,趁这几天有时间,把数据挖掘过程中一些流程规范和常见的机器学习问题总结一下。本篇博文涵盖的内容有机器学习的概念,模型分类(有监督、无监督),python语言与R语言,以及基于sklearn的机器学习框架。
一、什么是机器学习
机器学习概念的来自计算机科学领域,相关的一些研究与统计学有很大的重复部分。人类个体的学习是由客观世界给出的反馈然后进行向最优方向调节的过程,计算机科学家认为机器也可以像人脑一样进行学习,基于他们的数学功底,开发出的算法命名为机器学习。学习的本质是一大批互相连接的信息传递和存储元素所组成的系统。他们共同的特点是:开始准确率很低,随着学习进行,准确率越来越高。

二、机器学习方法的分类
2.1 监督式学习 Supervised Learning
在监督式学习下,每组训练数据都有一个标识值或结果值(target)。
2.1.1 分类 Classification
(1)K最近邻 K-Nearest Neighbor (KNN)
(2)朴素贝叶斯 Naive Bayes
(3)决策树 Decision Tree
- ID3
- C4.5
- 分类回归树 Classification And Regression Tree (CART)

区别:决策树系列算法总结(ID3, C4.5, CART, Random Forest, GBDT)
(4)支持向量机器 Support Vector Machine (SVM)
2.1.2 回归 Regression
(1)线性回归 linear regression
(2)局部加权回归 Locally weighted regression
(3)逻辑回归 logistic Regression
(4)逐步回归 stepwise regression
(5)岭回归 Ridge Regression
(6)Least Absolute Shrinkage and Selection Operator ( LASSO )
(7)弹性网络 Elastic Net (L1+L2)
(8)人工神经网络
2.2 非监督学习 Unsupervised Learning
(1)聚类 Cluster (K均值 k-means)
(2)主成分分析Principal Component Analysis ( PCA )
(3)偏最小二乘回归 Partial Least Squares Regression ( PLS )
(4)关联规则 Association Rule
2.3 半监督
在半监督学习方式下,训练数据有部分被标识,部分没有被标识,这种模型首先需要学习数据的内在结构,以便合理的组织数据来进行预测。算法上,包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如深度学习:
深度学习 Deep Learning
深度学习是 监督学习的匹配学习中人工神经网络延伸出来发展出来的。
(1)受限波尔兹曼机 Restricted Boltzmann Machine ( RBM )
(2)深度信念网络 Deep Belief Networks ( DBN )
(3)卷积网络 Convolutional Network
(4)栈式自编码 Stacked Auto-encoders
2.4 增强学习 Reinforcement Learning
增强学习应用范围在机器人和工业界比较多,与深度学习结合较多,目前暂不了解。
(1)Q-Learning
(2)时间差学习 Temporal difference learning
2.5 机器学习分类面试考点
一般笔试题都会问一道题,以下降维算法是否属于监督(非监督),在这里总结以下。
- 主成分分析(Principal Component Analysis,PCA)
- 线性判别分析(Linear Discriminant Analysis,LDA)
- 等距映射(Isomap)
- 局部线性嵌入(Locally Linear Embedding,LLE)
- Laplacian 特征映射(Laplacian Eigenmaps)
- 局部保留投影(Local Preserving Projection,LPP)
- 局部切空间排列(Local Tangent Space Alignment,LTSA)
- 最大方差展开( Maximum Variance Unfolding,MVU)
| 分类法(是否) | 是 | 不是 |
|---|---|---|
| 监 督 | PCA、LPP、Isomap、LLE、Laplacian Eigenmaps、LTSA、MVU | LDA |
| 线 性 | PCA、LDA、LPP | Isomap、LLE、Laplacian Eigenmaps、LTSA、MVU |
| 全 局 | PCA、LDA、Isomap、MVU | Laplacian Eigenmaps、LPP、LTSA |
三、Python机器学习
3.1 为什么选择python
项目里做模型的语言肯定是R/SAS/Python三者之一,项目上线一般是Java。R语言和Python语言有许多共通之处,比如pandas就是借鉴R中的dataframe。其他的相同点不再多说,比如开源、易学习,主要的不同点在:
- python 更加通用。除了可以用python进行数据分析,它还在其他领域有更多应用,比如Linux运维、socket编程、游戏开发等。
- R的包管理很复杂。虽然同样是机器学习,R中不同模型可以使用的方法都不一样,而且有时候还需要加载一些命名非常奇怪的包。更多情况下是我自己写完的R代码过几天再看,这都是啥?
- python 的社区比R更加完善。除了stackoverflow, R的一些社区感觉就是各自为战,而且大部分是讨论统计学上的问题。找到特定bug解决的成本挺高的。
总的来说,R偏向于学术上的计算,python更易上手,而且社区对新人非常友好,所以我建议用python进行数据分析。
3.2 机器学习大杀器 scikit-learn
3.2.1 什么是 sklearn
sklearn (scikit-learn简称) 是基于 numpy 和 scipy 扩展的模块,项目最早由David Cournapeau 于2007年谷歌编程大赛发起,后来越来越多的贡献者加入到模块的开发,经过多年发展,成为了python里机器学习最强大的工具包。基本涵盖了数据挖掘流程中所有可能需要用到的算法。
项目代码传送门:Github/scikit-learn
3.2.2 sklearn 安装指南
- 集成环境(推荐)
Anaconda+Spyder(清华镜像) 自定义安装(
python+Jupyter IPython Notebook)Python(>= 2.7 or >= 3.3)NumPy(>= 1.8.2)SciPy(>= 0.13.3)
安装方法:
- pip install numpy,scipy, sklearn -i https://pypi.douban.com/simple
- windows环境下遇到编译错误的情况:下载对应的.whl(编译好的文件) 到本地,再用 pip install 安装。
whl下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy - IPython Notebook
https://jupyter.readthedocs.io/en/latest/install.html
3.3 如何确定学习类型
处理不同问题的时候呢, 我们会要用到不同的机器学习-学习方法。 Sklearn 提供了一张非常有用的流程图,供我们选择合适的学习方法。

根据样本量,是否分类问题等确定解决的方法。
3.4 sklearn 通用学习模式
根据sklearn的开发规范,只要你懂使用其中一个模型,就能按一样的格式使用其他的模型。
3.4.1 通用数据库
sklearn 自带一些常用的测试数据集,比如鸢尾花、手写字符(0-9)、573条波士顿房价数据,以及更强大的自定义分类或者回归的随机数据集。
from sklearn import datasets
import matplotlib.pyplot as plt
# 自带的数据集
iris = datasets.load_riris() # load_digital
test_X = iris.data
test_y = iris.target
feat_name = iris.feature_names
# 计算机产生的数据集
## 产生样本量为100,特征维数为2,有相关关系的特征维数为2,的分类数据集
X, y = datasets.make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=2, random_state=22)
## 产生样本量为100,特征维数为2,有相关关系的特征维数为2,分类数为1,噪声为0的分类数据集
X, y = datasets.make_regression(n_samples=100, n_features=2, n_informative=2, n_targets=1, noise=0.0, random_state=22)
# 可视化
plt.scatter(X, y)
plt.show()完整数据库及介绍:
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
3.4.2 数据集切分、训练
真实建模必须要分训练集和测试集
from sklearn.model_selection import train_test_split
# 分随机抽取30%的数据作为测试集,有4个返回值
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3)模型训练、预测,以KNN模型为例
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
iris = datasets.load_iris()
X= iris.data
y = iris.target
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3)
# 引入模型
knn = KNeighborsClassifier()
# fit 训练步骤
knn.fit(train_X, train_y)
# pred 预测步骤
pred = knn.predict(test_X)
## 分别打印出来看看有没有预测错误的
print(np.array(test_y))
print(np.array(pred))
# 或者直接打印score
print(knn.score(test_X,test_y)) # 93%左右的正确率3.4.3 数据标准化(去量纲)
在梯度下降过程中,如果数据的跨度太大会导致收敛速度降低,模型产生偏差,所以一般情况下都需要对数据进行标准化或者归一化。
sklearn 提供了数据预处理的一些方法,比如scale和minmax_scale。以相同数据集iris 作为比较。
from sklearn import preprocessing
from sklearn.svm import SVC
X_scale = preprocessing.scale(X)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3)
knn.fit(train_X, train_y)
print(knn.score(test_X, test_y))使用SVM中的中的分类
from sklearn.svm import SVC
X_scale = preprocessing.scale(X)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(train_X, train_y)
print(clf.score(test_X, test_y)) ##正确率99%3.4.5 交叉验证改善模型
交叉验证(cross_validation)是指将原数据集切分成n等分,每一份做一次得分,求得平均值作为当前模型的准确度或者误差。
# 示例
from sklearn.model_selection import cross_val_score
scores = cross_val_score(knn, X, y, cv=5, scoring="accuracy")
print(scores.mean())
#array([ 0.966667, 1. , 0.93333, 0.966667, 1. ])3.4.5.1 参数调优
KNN选取k个最近邻的类别进行打分,当k不同时,对模型结果能造成一定影响。如果我们想找到最好的k的近邻,就需要进行交叉验证。
k_score = []
k = range(1,31)
for n in k:
knn = KNeighborsClassifier(n_neighbors=n)
scores = cross_val_score(knn, X, y, cv=5, scoring="accuracy") # 分类问题
# loss = -cross_val_score(knn, X, y, cv=5, scoring="mean_squared_error") # 回归
k_score.append(scores.mean())
plt.plot(k, k_score)
plt.xlabel("Value for KNN")
plt.ylabel("Cross-validation accuracy")
plt.show()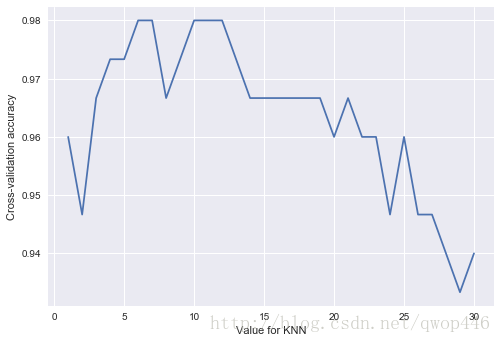
当k=10左右模型的准确率最好。
3.4.5.2 防止过拟合
sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度,对比发现有没有 overfitting 的问题。然后我们可以对我们的 model 进行调整,克服 overfitting 的问题。
# 以手写数字识别数据库为例
## 手写字体
from sklearn.model_selection import learning_curve
from sklearn.svm import SVC
digits = datasets.load_digits()
X = digits.data
y = digits.target
train_sizes, train_loss, test_loss = learning_curve(SVC(gamma=0.001), X, y, cv=5,
scoring="neg_mean_squared_error", train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss,axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-', color='r', label="training error")
plt.plot(train_sizes, test_loss_mean, 'o-', color='g', label="cross-validation")
plt.legend()
plt.show()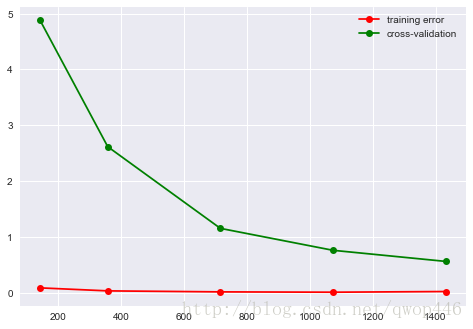
3.4.5.3 同时兼顾过拟合与参数寻优
validation_curve, 用这一种 curve 我们就能更加直观看出改变 model 中的参数的时候有没有 overfitting 的问题了。这也是可以让我们更好的选择参数的方法。
from sklearn.model_selection import validation_curve
# 参数范围
param_range = np.logspace(-6,-2.3, num=7)
train_loss, test_loss = validation_curve(SVC(), X, y, param_name='gamma', param_range=param_range,
cv=5, scoring="neg_mean_squared_error")
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(param_range, train_loss_mean, 'o-', color='r', label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color='g', label="Cross-validation")
plt.legend()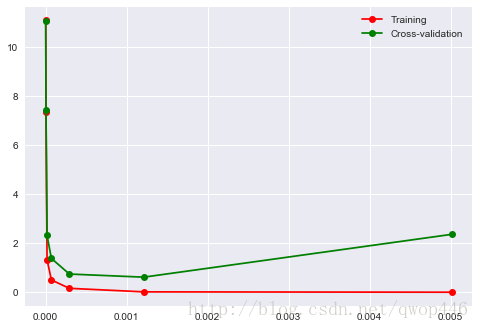
因此, 最优的gamma参数为0.001附近,此时cv=5的训练误差和测试集误差最小。
四、模型保存
# 方法 1: pickle
import pickle
## save
with open('save/clf.pickle', 'wb') as f:
pickle.dump(knn, f)
## restore
with open('save/clf.pickle', 'wb') as f:
knn = pickle.load(f)
# 方法 2: joblib
from sklearn.externals import joblib
## save
joblib.dump(knn, 'save/save.pkl')
## restore
knn = joblib.load('save/save.pkl')