-------------------
common
hdfs //namenode + datanode + secondarynamenode
mapred
yarn //resourcemanager + nodemanager
1.Hdfs简介
Hdfs是基于流数据模式访问和处理超大文件的需求而开发的,可以运行在廉价的商用服务器上。我们通常所说的分布式系统其实是分布式文件系统,即支持分布式处理的软件系统,他是在通信网络互连的多处理机体系结构上执行任务的系统,包括分布式操作系统,分布式程序设计语言及其编译(解释)系统,分布式文件系统和分布式数据库系统等。Hadoop是分布式软件系统中文件系统层的软件,实现了分布式文件系统和部分分布式数据库系统的功能。Hadoop中的分布式文件系统Hdfs实现了数据在计算机集群上的存储和管理。Hdfs不适合:(1)低延迟的数据访问:Hdfs是为了处理大型数据集分析任务,主要是为达到高的数据吞吐量而设计的,这就要求可能以高延迟作为代价。(2)无法高效的存储大量的小文件:在Hadoop中需要用NameNode(名称节点)来管理文件系统的元数据,以响应客户端请求返回文件位置等,因此文件数量大小的限制要由NameNode来决定。例如,每个文件,索引目录及块大约占100字节左右,如果有100万文件,每个文件占一个块,那么至少要消耗200M内存,这似乎可以接受。但是如果有更多文件,那么NameNode的工作压力更大,检索处理元数据所需要的时间就不可接受了。(3):不支持多用户写入及任意修改文件。
2.Hdfs的组成以及体系结构
2.1Hdfs由3部分组成,分别是:
NameNode——主节点,主要用来保存元数据信息,维护整个文件系统的文件目录树以及这些文件的索引目录
DataNode——数据节点,主要用来存储数据。
Secondarynamenode——辅助节点,主要用来实时备份NameNode的元数据信息,并且合并edits与fsimage(后边我们来分析这两个文件)
2.2Hdfs的体系结构
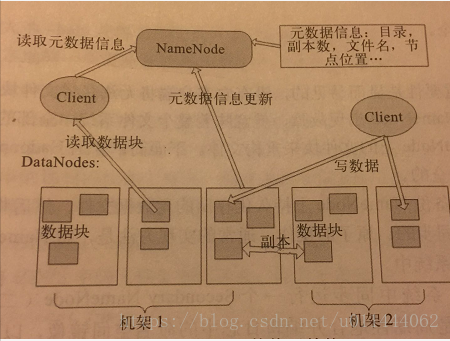
Hdfs采用Master/Slave架构对文件系统进行管理。一个Hdfs集群是由一个NmaeNode和一定数目的DataNode组成。NmaeNode是一个中心服务器,负责管理文件系统的名字空间(Namespeace)以及客户端对文件的访问。集群中的DataNode一般是一个节点运行一个DataNode进程,负责管理它所在节点上的存储。Hdfs展示了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分割成一个或多个数据块,这些块存储在一组DataNode上。NameNode执行文件系统的名字空间操作,比如打开,关闭,重命名文件或目录。NameNode也负责确定数据块到具体DataNode节点的映射。DataNode负责处理文件系统客户端的读/写请求。在NameNode的统一调度下进行数据块的创建,删除和复制。
2.2.1块(Block)
我们知道,在操作系统中都有一个文件块的概念,文件以块的形式存储在磁盘中,此处块的大小代表系统读/写可操作的最小文件大小,也就是说,文件系统每次都只能操作磁盘块大小的整数倍数据。Hdfs默认的数据块是默认大小为128M,为什么是128M呢,因为系统在寻找数据的时候(也就是寻找数据在哪个地方)有一个寻址时间,为了保证尽量不要数据的读取时间都花费在寻址时间上,所以让寻址时间占用读取时间的1%.也就是10ms左右,这样读取时间就是1s,而磁盘的速率是:100M/s大约,所以数据大小也就是为1s * 100M/s,转成2进制为128M。如果存储的数据大于128M,则Hdfs分布式文件系统会将数据进行切分,切分成多个数据块来进行存储,每个数据块都会根据配置的副本数进行复制多份,存储在集群上。以保证高可用。
2.2.2 副本的存放策略
大多数情况下,副本系数为3(将数据复制3份)。在配置文件 hdfs-site.xml中可以进行配置,在上一篇的集群搭建中我们的配置是3,Hdfs的存放策略是将一个副本存放在本地机架的节点上,另一个副本放在同一机器的另一个节点上,第三个副本放在不同机架的节点上。这种策略减少了机架间的数据传输,提高了写操作的效率。机架的错误远比节点的错误少,所以这个策略减少了不会影响数据的可靠性和可用性。同时,因为数据块只放在两个不同的机架上,所以这个策略减少了读取数据时需要的网络传输总带宽。副本的存放是Hdfs可靠性和性能的关键,优化的副本存放策略也正是Hdfs区别于其他大部分分布式系统的重要性。
2.2.3 数据的读取策略
在读取数据的时候,为了减少整体的带宽消耗和降低整体的带宽延迟,Hdfs会尽量让读取程序读取离客户端最近的副本,在海量数据处理中,其中主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。但实际上却很难实现,(它需要一个稳定的集群,并且在集群中两两节点对数量是节点数量的平方)。Hadoop为此采用一个简单的方法:把网络看做一颗数,两个节点间的距离是他们到最近共同祖先(交换机)的距离总和。该树中的层次是没有预先设定的,但是相对于数据中心,机架和正在运行的节点,通常可以设定等级。具体想法是针对以下每个场景,可用带宽依次递减:
1.同一节点上的进程
2.同一机架上的不同节点
3.同一数据中心不同机架上的节点
4.不同数据中心中的节点

2.2.4安全模式
NameNode启动之后会进入一个称为安全模式的特殊状态。处于安全模式的NameNode不会进行数据块的复制。NameNode从所有的DataNode接受心跳信号和块状态报告,块状态报告包括了某个DataNode所有的数据块列表。每个数据块都有一个指定的最小副本数(根据配置文件hdfs-site.xml中可以进行配置,上一篇写过,就是dfs.replication)。当NameNode检测确认某个数据块的副本数目达到最小值时,该数据块就会被认为是副本安全的,在一定百分比(这个参数可配置)的数据块NameNode检测确认是安全之后,NameNode将退出安全模式状态。
3.JAVA API基本操作
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
/**
* @author zpx
* @Title: ${file_name}
* @Package ${package_name}
* @Description: HDFS基本操作
* @date 2018/6/2121:58
*/
public class TestHDFS {
/**
* @Description: 从Hdfs中读取数据
* @param ${tags}
* @return void
* @throws
* @author zpx
* @date 2018/6/21 22:01
*/
@Test
public void readFile() throws Exception {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
URL url=new URL("hdfs://192.168.200.10:8020/user/zpx/hadoop/xcall.sh");
URLConnection conn=url.openConnection();
InputStream is = conn.getInputStream();
byte[] buf =new byte[is.available()];
is.read(buf);
System.out.println(new String(buf));
}
/**
* @Description: 通过HADOOP API访问文件
* @param ${tags}
* @return void
* @throws
* @author zpx
* @date 2018/6/21 22:22
*/
@Test
public void readFileByAPI() throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.200.10:8020/");
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("/user/zpx/hadoop/xcall.sh");
FSDataInputStream fis = fileSystem.open(path);
byte[] buf=new byte[1024];
int len =-1;
ByteArrayOutputStream baos=new ByteArrayOutputStream();
while((len = fis.read(buf))!=-1){
baos.write(buf,0,len);
}
fis.close();
baos.close();
System.out.println(new String(baos.toByteArray()));
}
/**
* @Description: 通过HADOOP API访问文件,推荐使用
* @param ${tags}
* @return void
* @throws
* @author zpx
* @date 2018/6/21 22:48
*/
@Test
public void readFileByAPI2() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.200.10:8020/");
FileSystem fs = FileSystem.get(conf) ;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Path p = new Path("/user/zpx/hadoop/xcall.sh");
FSDataInputStream fis = fs.open(p);
IOUtils.copyBytes(fis, baos, 1024);
System.out.println(new String(baos.toByteArray()));
}
/**
* @Description: 创建文件夹
* @param ${tags}
* @return void
* @throws
* @author zpx
* @date 2018/6/21 22:56
*/
@Test
public void mkdir() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.200.10:8020/");
FileSystem fs = FileSystem.get(conf) ;
fs.mkdirs(new Path("/user/zpx/data"));
}
/**
* @Description: 向HDFS上传输数据文件
* @param ${tags}
* @return ${return_type}
* @throws
* @author zpx
* @date 2018/6/21 23:22
*/
@Test
public void putFile() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.200.10:8020/");
FileSystem fs = FileSystem.get(conf) ;
FSDataOutputStream out = fs.create(new Path("/user/zpx/data/a.txt"));
out.write("helloworld".getBytes());
out.close();
}
/**
* @Description: 删除文件
* @param ${tags}
* @return void
* @throws
* @author zpx
* @date 2018/6/21 23:30
*/
@Test
public void removeFile() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.200.10:8020/");
FileSystem fs = FileSystem.get(conf) ;
Path p = new Path("/user/zpx/data");
fs.delete(p, true);
}
}
4.hdfs命令行的基本命令