摘要
在NLP的文本序列相关的任务中,深度学习的方法被广泛使用。但是深度学习模型的参数多、计算量大,所以不易于训练。对于深度学习模型的效果,也缺乏严格的研究。在这篇文章中,我们对两种方法进行对比,即简单的、基于word-embedding、包含了pooling操作的SWEMs,以及基于word-embedding的 CNN/RNN模型。出人意料的是,在大部分任务中,SWEMs的效果能够打平甚至超过CNN/RNN。作者提出了两种额外的pooling方法,即 i) max-pooling,这种pooling方法可以有较好的直观解释性 ii) hierarchical pooling,这种pooling可以获取空间、词序信息(n-gram)。作者在17个数据集上做了三类任务的对比实验,即 i) 长文本分类 ii) 文本匹配 iii) 短文本分类、标注。
一、问题介绍
以word-embedding为基本组件,深度学习方法被用于对可变长度的句子序列进行建模。这些方法包括了简答的对word embeddings的加和操作,以及更为复杂的CNN/RNN方法。
CNN/RNN能力强大,但是计算量大,相比而言,简单模型则是通过对word embeddings (通过word2vec或者glove得到) 进行简单的加和、求平均运算。一般而言,这种SWEM方法难以保留句子内部的词序信息,但这种方法的确计算简单,所以这里就有了计算量-模型效果的trade-off。
本文中,我们设计实验,从而探寻简单的pooling操作,在何种情况下是有效的,以及有效的原因所在。
我们设计实验,探索词序信息在不同的NLP任务中的作用大小。我们发现,在文本表示任务中,很多词,诸如停用词、与情感或主题无关的词对最终预测效果的作用微乎其微。基于此,我们提出了max-pooling操作,max-pooling是在句子的全部word embedding的每一维取max,用来提取最有效的信息。为什么是每一维取max?因为word embedding的每一维都反映了某一方面的信息,每个词与某个维度信息的相关性是不一样的,我们对word embedding取max,就是取与每一维度相关性最大的word。在情感分析任务中,我们提出hierarchical pooling,这种pooling可以提取空间也就是词序信息。
二、相关工作
NLP任务中一个基本的目标就是构建有效、计算考虑高的函数去抓取自然语言序列的语义结构。那么这些函数应该是怎样的呢?最近的研究表明,在一些特定的NLP任务中,一些基于word-embedding的简单模型的效果甚至追平甚至超过了CNN/RNN等复杂模型。在这些基于word-embedding的模型中,虽然复杂结构被去除,但另外的模块,比如attention-layer被包含进来。
SWEM和Deep Averaging Network (DAN)以及fastText很相似,fastText其实就是一个简答的averaging pooling操作。在本文中,除averaging pooling之外,我们还会探索几种pooling方法。特别的,在情感分析任务中,我们提出的hierarchical pooling相比averaging会取得更好的效果。除了回答何种情况下简单的pooling操作是有效的,我们还将探索背后的原因。
三、模型和训练
考虑一个句子序列
,包含词汇
,
是token的个数,也就是句子/文档的长度,
是每一个token对应的word embedding,我么要找到一个函数
,把
映射到一个固定长度的向量
,即
,然后用
来做具体的预测任务。
Recurrent Sequence Encoder
RNN的函数形式为Convolutional Sequence Encoder
CNN卷积层的每个窗口观察 个连续的word,卷积层之上是max-pooling层,用来提取最显著的特征。Simple Word-Embedding Model (SWEM)
1) SWEM-aver
averaging pooling
2) SWEM-max
max-pooling
3) SWEM-concat
concat-pooling
将SWEM-aver、SWEM-max的结果做concat,道理在于,averaging pooling保留了全部token的信息,而max-pooling则侧重突出的信息。
4)Hierarchical Pooling
SWEM-aver和SWEM-max都无法将词序信息纳入,所以提出了Hierarchical Pooling的方法。 为窗口 内的 个token的word-embedding,先做averaging-pooling,得到 个向量,然后对这 个向量做max-pooling。参数量 & 计算复杂度比较
对于CNN、LSTM、SWEM,比较参数量以及计算开销。
记 为word-embedding的维度, 为CNN filter的尺寸, 为最终的序列表示的维度,特别的, 其实就是LSTM的hidden unit的个数,或者CNN中filter的个数。
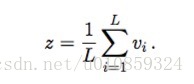
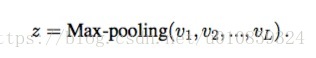

四、实验
作者在多个NLP任务上进行了实验,包括文档分类、句子匹配、文本分类。
使用glove模型得到的word embedding (维度
)。词典之外的词的向量用[-0.01, 0.01] 之间的均匀分布来初始化。glove embedding有两种使用方式,1)embedding作为初始化,然后在模型训练的过程中做fine-tune 2) embedding后接一个带有ReLU activation的MLP(就是先线性变换,再非线性变换),模型训练的过程中去更新MLP,把MLP层的输出作为最终的embedding。后者可以更好地适应不同的任务、数据集。
最后的分类器是MLP (维度从[100,300,500,1000]中选择), 后接一个sigmoid / softmax函数。
优化算法选用adam,learning rate选择范围是
,dropout 在word embedding层以及末尾的MLP层使用,dropout rate从[0.2, 0.5, 0.7] 中选择。
4.1 文档分类
也就是长文本分类。数据集分为三类,主题分类、情感分析、本体分类。各个模型效果如下
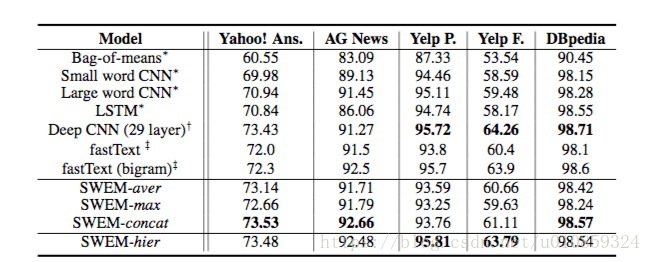
可以看到,在主题分类任务上,SWEM的效果甚至超过了CNN、LSTM。SWEM-concat甚至超过了29层的CNN模型。
而在情感分析任务中,CNN、LSTM的效果则超过了SWEM,这意味着词序信息对于分析情感是有用的。譬如”not really good” 和 “really not good”所表达的负面情感程度是不一样的。
4.1.1 模型解释
大多数情况下SWEM-concat可以取得SWEM变体中最好的效果。我们发现,SWEM-max得到的词向量很稀疏。我们统计word embedding各个维度的取值的分布,如下图
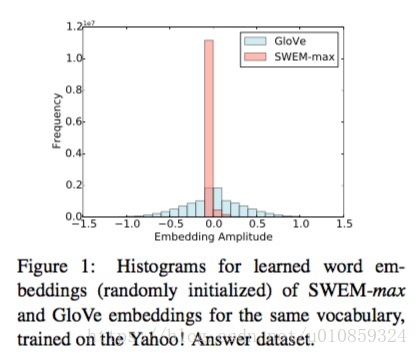
可以发现SWEM-max大多数取值为0。
4.2 文本匹配
SWEM取得了比CNN、LSTM更好的效果,这表明在进行自然语言的匹配时,大多数情况下词语级别的对齐就足够了。
4.2.1 语序的重要性。
语序什么情况下是重要的?作者做了一组实验,将训练集的句子内部的词序做shuffle,
模型效果如下,
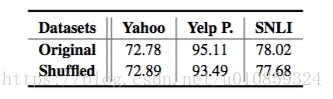
可以看到,对于Yahoo、SNLI两个数据集,LSTM模型的效果几乎不受shuffle的影响。而在Yelp P. 数据集(情感分析)上,语序是重要的。
4.3 SWEM-hier for sentiment analysis
参考文献:
Baseline Needs More Love:On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms