布隆过滤器原理:
涉及因子:
m:存储比特位的数组长度(数组长度越长,元素越小,则误判几率越低)注意:m必须>n,不然当只有一个哈希函数的时候都一定会出现hash冲突
n:需要存储转换的元素的个数
K: 把元素M映射在数组上哪一位为1的哈希函数的个数。 K要 <= m/n
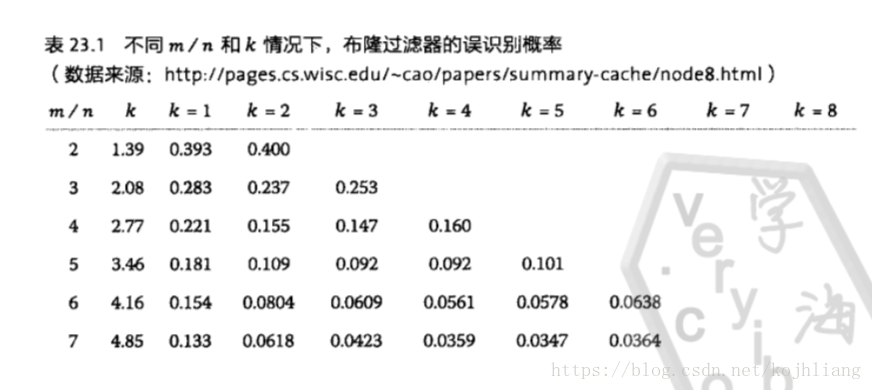
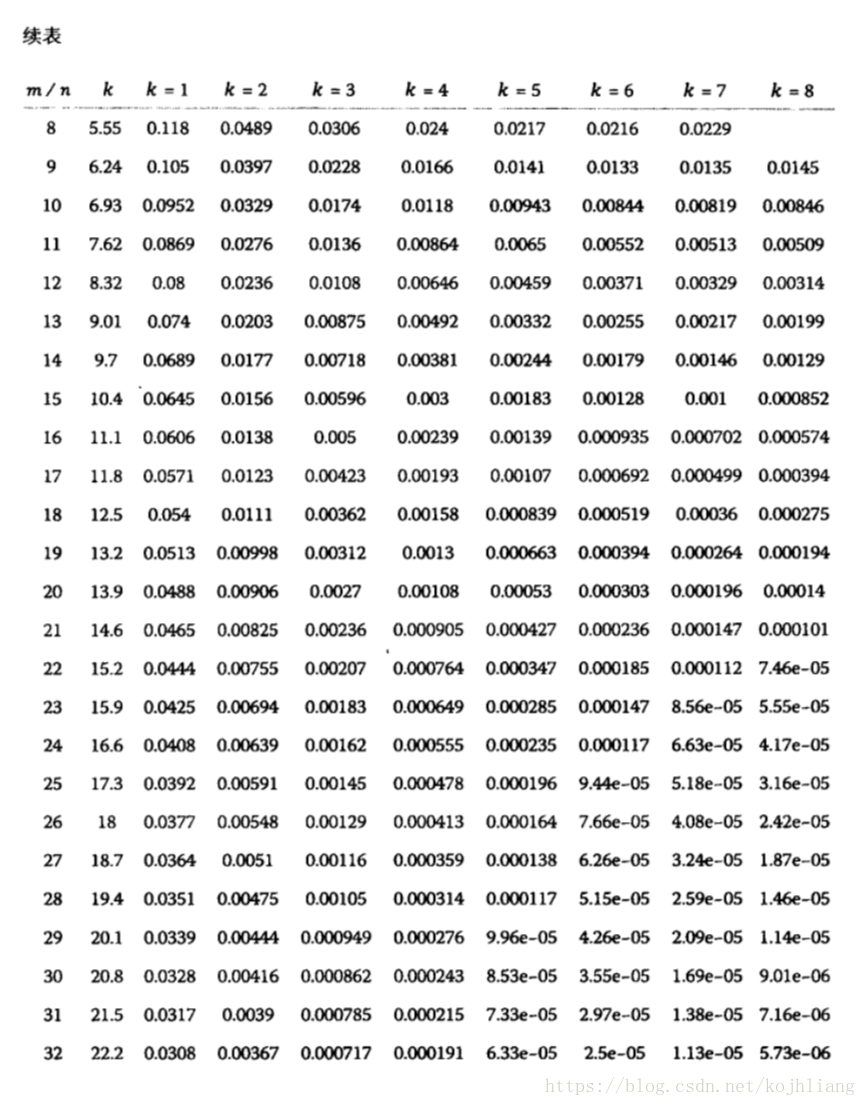
假设只需要过滤三个地址,则n为3,m/n=16,k=8,则误判率为万分之5左右)
先来思考一下本质,如果要精确匹配这三个地址,只需要把收到的每笔交易都和这三个地址对比,就知道是否是匹配的交易,但是这样会泄漏用户隐私。因此,通过布隆过滤器来增大交易能匹配成功的概率,从而无法准确得知用户钱包是哪些地址。再思考一种情况,如果只是为了增大哈希碰撞概率,把在n值不变情况下,把m设置小一点,通过一次的hash函数映射即可达到效果,为什么需要多个hash函数计算呢?因为如果只用一个hash函数,假设n/m=32,误判的概率才为0.03%,这样对于大量交易来讲,这样能匹配到的地址还是会很多的,如果想降低误判率,又不想占用太多的空间,可以通过增加hash函数来实现,这就是以计算时间来换取空间的方法。通过要达到误判的概率为0.03%,m/n=8,哈希函数个数为3个,就能够实现了。这样会比上一种情况减少24n的比特位空间。
1.建立一个m=48的比特位数组,关键地址为a1,a2和a3这三个,哈希函数个数为8个。
2.先把这个三个关键地址通过这个8个哈希函数映射到这个长度为48的比特位数组里。
3.对于收到的每一笔交易,把交易里的地址计算这个8个哈希函数映射到这个长度为48的比特位数组的位置。
这里有两种情况:
一种情况是提取的这个地址计算8个哈希函数映射到的位置都为1,那么证明这个地址大概率匹配正确,因此会把包含该地址的相关信息传给spv节点。
另一种情况是这个地址计算8个哈希函数映射到的位置上的值有>=1个是为0的,那么立刻可以证明这个地址是不匹配的,因此不会把包含该地址的相关信息传给spv节点。