一. Image Classification Challenges :
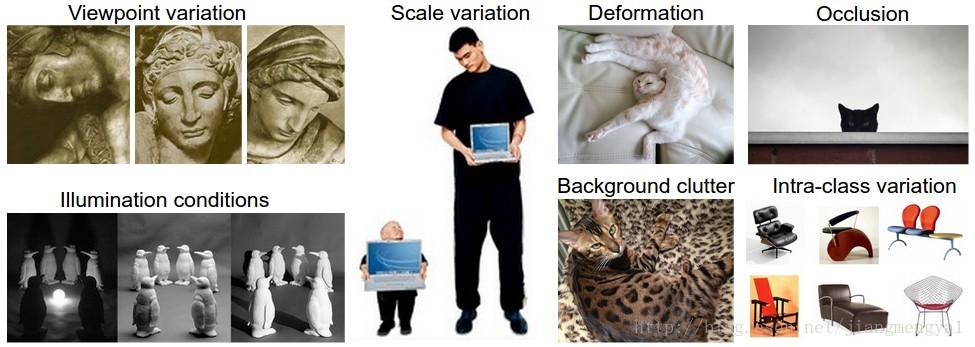
1. Viewpoint variation
2. Scale variation
3. Deformation
Many objects of interest are not rigid bodies and can be deformed in extreme ways.
4. Occlusion
The objects of interest can be occluded. Sometimes only a small portion of an object could be visible.
5. Illumination Conditions
6. Background Clutter
The objects of interest may blend into their environment, making them hard to identify.
7. Intra-class Variation
The classes of interest can often be relatively broad, such as chair. There are many different types of those objects, each with their own appearance.
二. Nearest Neighbor Classifier
This classifier has nothing to do with Convolutional Neural Networks and it is very used in practice , but it will allow us to get an idea about the basic approach to an image classification problem.
One popular toy image classification dataset is the CIFAR-10 dataset. This dataset consists 60,000 tiny images that are 32 pixels high and wide. Each image is labeled with one of 10 classes.

Suppose now we are given the CIFAR-10 training set of 50,000 images , and we wish to label the remaining 10,000. The Nearest Neighbor classifier will take a test image, compare it to every single one of the training images , and predict the label of the closest training image.
In the image above and on the right you can see an example result of such a procedure for 10 example test images. Notice that in only 3 out of 10 examples an image of the same class is retrieved, while in the other 7 examples this is not the case. For example, in the 8th row the nearest training image to the horse head is a red car, persumably due to the strong black background. As a result, this image of a horse would in this case be mislabeled as a car .
Given two images and representing them as vectors , a reasonable choice for comparing them might be the L1 distance :
This classifier only achieves 38.6% on CIFAR-10. That is more impressive than guessing it at random , but nowhere near human performance or near state-of-art Convolutional Neural Networks that achieve about 95%.
三. K - Nearest Neighbor Classifier
The idea is very simple : instead of finding the single closest image in the training set , we will find the top K closest images, and have them vote on the label of the test image.
Using 2-dimensional points and 3-classes , the colored regions show the decision boundaries induced by the classifier with an L2 distance. Note that in the case of a NN classifier, outlier datapoints create small islands of likely incorrect predictions, while the 5-NN classifier smooths over these irregularities, likely leading to better generalization on the test data. Also note that the gray regions in the 5-NN image are caused by ties in the votes among the nearest neighbors.
四. Data Set splits
Split your training set into training set and a validation set. Use validation set to tune all hyperparameters. At the end run a single time on the test set and report performance.
In 5-fold cross-validation, we would split the training data into 5 equal folds, use 4 of them for training, and 1 for validation. We would then iterate over which fold is the validation fold, evaluate the performance, and finally average the performance across the different folds.
Typical number of folds you can see in practice would be 3-fold, 5-fold, or 10-fold cross-validation.
五. Summary

As shown above, an original image and three other images next to it that are all equally far away from it based on L2 pixel distance. Clearly, the pixel-wise distance does not corresponsed at all to perceptual or semantic similarity.
The Nearest Neighbor Classifier is rarely appropriate for use in practical image classification setting .
Original Link : http://cs231n.github.io/classification/