一、线性回归的决定系数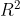 (也称为判定系数,拟合优度)
(也称为判定系数,拟合优度)
相关系数是R哈~~~就是决定系数的开方!
正如题所说决定系数是来衡量回归的好坏,换句话说就是回归拟合的曲线它的拟合优度!也就是得分啦~~
决定系数它是表征回归方程在多大程度上解释了因变量的变化,或者说方程对观测值的拟合程度如何。
计算公式为:

决定系数越大表拟合优度越好!
Python中可直接调用score()方法来计算决定系数值。
score(self, x_test, y_test, sample_weight=None)
二、分类问题中的评判标准
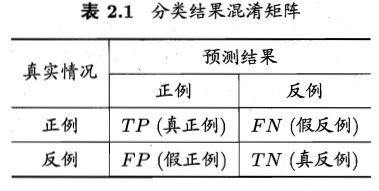
以二分类问题为例进行说明。分类结果的混淆矩阵如下图所示。
准确率、精确率:
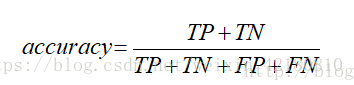
精准率,查全率:

召回率、查全率:
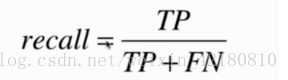
调和平均数f1_score:
P-R曲线
将查准率P作为纵轴,查全率R作为横轴,在坐标轴上绘制出这些P-R数组,再连成曲线,即可得到相应的P-R曲线图。
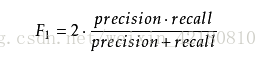
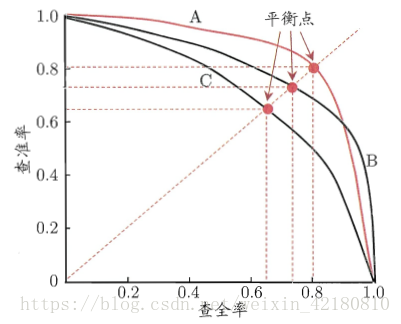
从图上所示,不同的算法,对应着不同的P-R曲线。如图所示,我们有A,B,C三条曲线。通常,我们认为如果一条曲线甲,能够被另一条曲线乙包住,则认为乙的性能优于甲。在上图所示,就是曲线B的性能要高于曲线C。但是A和B发生了交叉,所以不能判断出A、B之间哪个算法更优。 比较两个分类器好坏时,显然是查得又准又全的比较好,也就是的PR曲线越往坐标(1,1)的位置靠近越好。因此,在图上标记了“平衡点(Break-Even Point,简称BEPBEP)”。它是“查准率=查全率”时的取值,同时也是我们衡量算法优劣的一个参考。
ROC曲线 (受试者操作特征(Receiver Operating Characteristic),roc曲线上每个点反映着对同一信号刺激的感受性)
对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络,得到诸如0.5,0,8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的为0类,大于等于0.4的为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1,0.2等等。取不同的阈值,得到的最后的分类情况也就不同。
如下面这幅图: 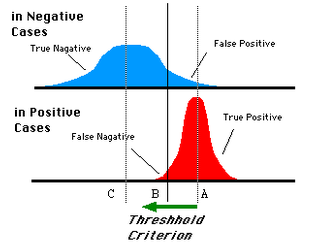
蓝色表示原始为负类分类得到的统计图,红色为正类得到的统计图。那么我们取一条直线,直线左边分为负类,右边分为正,这条直线也就是我们所取的阈值。
阈值不同,可以得到不同的结果,但是由分类器决定的统计图始终是不变的。这时候就需要一个独立于阈值,只与分类器有关的评价指标,来衡量特定分类器的好坏。
还有在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识别率为90%。但这显然是没有意义的。
如上就是ROC曲线的动机。
ROC空间将假正例率(False Positive Rate, 简称FPR)定义为 X轴,真正例率(True Positive Rate, 简称TPR)定义为 Y 轴。这两个值由上面四个值计算得到,公式如下:
TPR:在所有实际为正例的样本中,被正确地判断为正例之比率。
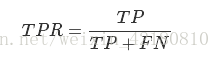
FPR:在所有实际为反例的样本中,被错误地判断为正例之比率。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间。 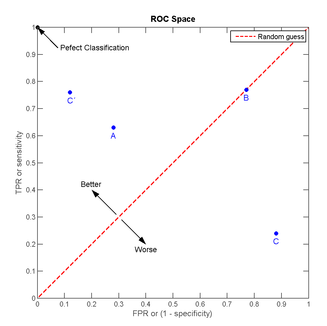
我们可以看出,左上角的点(TPR=1,FPR=0)(TPR=1,FPR=0),为完美分类。曲线距离左上角越近,证明分类器效果越好。点A(TPR>FPR)表明判断大体是正确的。中线上的点B(TPR=FPR)表明判定一半对一半错(这种最垃圾~~);下半平面的点C(TPR<FPR)说明判定大体错误。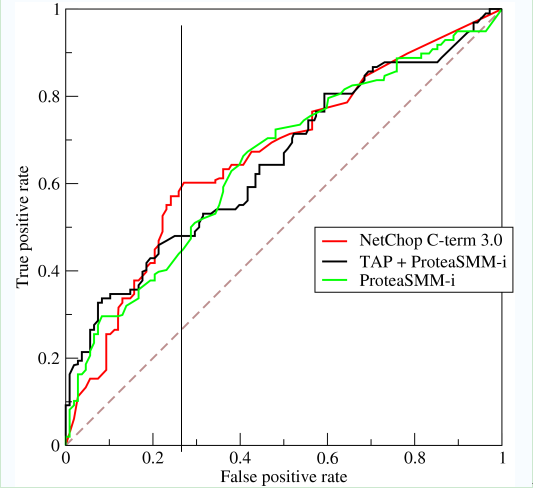
如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化它。
AUC(Area Under ROC Curve)
auc其实就是ROC曲线围成的面积!!
在两个分类器的ROC曲线交叉的情况下,无法判断哪个分类器性能更好,这时可以计算ROC曲线下面积AUC,作为性能度量,面积越大则越好。
为什么使用Roc和Auc评价分类器
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比:
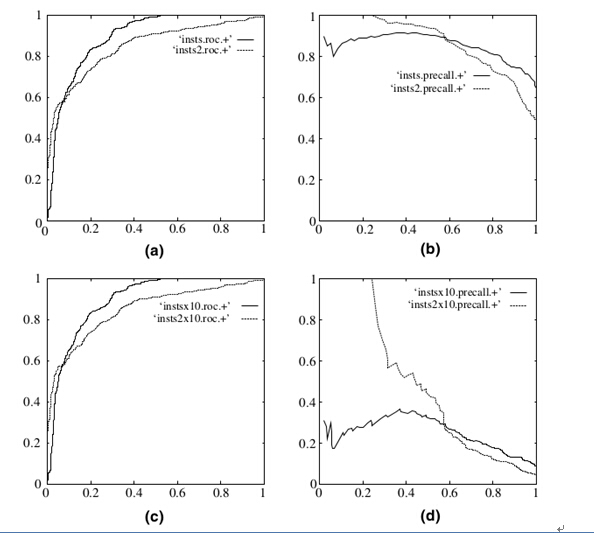
在上图中,(a)和(c)为Roc曲线,(b)和(d)为P-R曲线。
(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
以上的Python代码实现大家可以参考这位的博客:https://www.jianshu.com/p/28ef55b779ca