摘要
近年来,循环神经网络语言模型(RNNLMs)在包括语音识别在内的一系列应用中越来越流行。然而,RNNLMs的训练计算开销巨大,这就限制了可使用的数据量和网络大小。为了充分利用RNNLMs的能力,要求有效的训练实现。本文介绍了CUED-RNNLM,一个开源工具包,它能支持高效的基于GPU的RNNLMs训练。与现有的使用基于class的输出目标不同,它支持大规模词级别输出目标的RNNLM训练。并包含了对HTK和Kaldi格式lattices的N-best和lattice-based重打分的支持。本文展示了一个使用该工具包训练和评估RNNLMs的例子,其用于一个使用AMI语料库的基于Kaldi的语音识别系统。所有必要的资源都可在网上获取,包括源码、文档和recipe。
索引词:语言模型,循环神经网络,语音识别,GPU,开源工具包
1. 介绍
语言模型在许多语音和语言处理应用中是关键性的组件,例如语音识别、机器翻译。由于n-gram语言模型的优异性能和高效实现,其作为统治性的语言建模方法已经有数十年了。然而关于n-gram语言模型有两个众所周知的问题 。第一个问题是数据稀疏性,鲁棒性参数估计需要复杂的平滑技术。第二个问题在于n阶马尔科夫假设,预测的词概率值依赖于前n-1个词,这样更长距离上下文依赖就被忽略了。
循环神经网络语言模型(RNNLMs)将每个词映射到一个紧凑的连续向量空间,该空间使用相对小的参数集合并使用循环连接来建模长距离上下文依赖。这样RNNLMs就为n-gram的两个关键问题提供了解决方案。并且,RNNLMs在语音识别任务中相对于n-gram语言模型表现出了重大的提升,这导致了其大范围的应用。
然而,训练RNNLMs对计算量要求苛刻,处理大量数据时缓慢的训练速度限制了RNNLMs的使用。在我们之前的工作中,通过使用一种新的句子拼接串模式并行算法,RNNLMs在GPU上被高效地训练,取得了相比Mikolov在CPU上运行的RNNLM工具包27倍的重大加速。为了减小词到class映射的性能敏感度,提高串模式训练的效率,采用了带全输出层的RNNLMs(FRNNLM),而不是广泛使用的基于class的RNNLM(CRNNLM)。
输出层的softmax归一化严重影响FRNNLM的评估速度,特别是当建模大词汇表时,或许包含数十万个词的情况。为了解决这个问题,提出了两个改进的RNNLM训练准则:方差正则化和噪声对比估计。两种方法都允许使用一个常量的历史独立的归一化项,因而在CPU上相当提升了RNNLM的评估速度。
本文介绍了CUED-RNNLM工具包,包含了以上基于GPU的RNNLM训练和改进的训练准则的高效实现。文章剩余部分组织如下。第2部分是对RNNLMs的简要回顾。第3部分讨论了3个现有的训练神经网络语言模型的开源工具包。CUED-RNNLM工具包的高效训练、评估和实现对应地展示在第4、5、6部分。构建于AMI语料库的Kaldi语音识别系统之上的实验展示在第7部分。第8部分作出结论并讨论未来工作。
2. 循环神经网络语言模型
RNNLMs使用前一个词
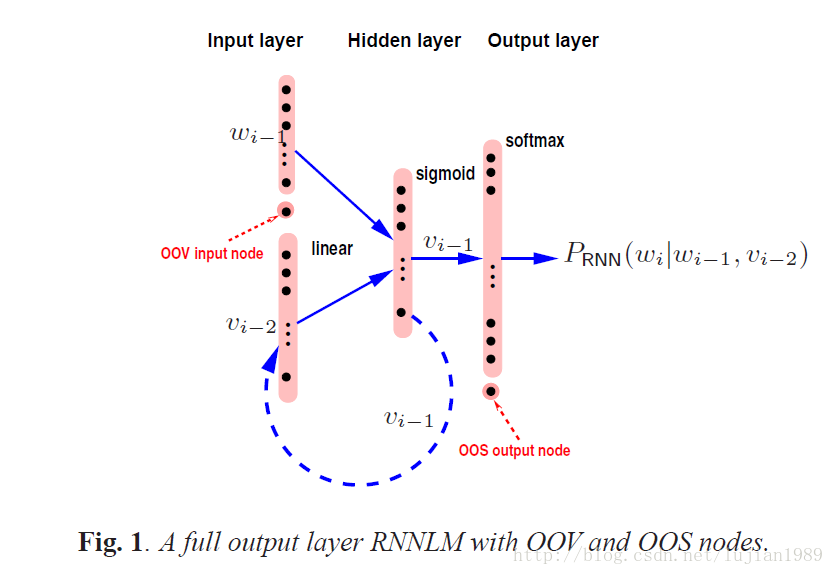
一个带有非聚类完整输出层的示例RNNLM结构如图1所示。RNNLMs可以使用随时间反向传播(BPTT)算法来训练,其误差通过循环连接传递回去特定的时间步长,比如4或5。为了减小计算消耗,一个候选列表(shortlist)可用于限制输出层至最常用词。为了减小RNNLMs训练中至候选列表词的偏差以及提高鲁棒性,一个额外节点被添加至输出层,以建模候选列表外(OOS)词的概率质量。
带完整输出层的RNNLMs训练计算开销巨大。一个流行的解决方法是使用基于class的RNNLMs。输出层词典中的单词被映射到classes。由于class的数量和每个class中词的数量显著小于输出层词典,基于class的RNNLMs能够在CPU上高效训练。然而,基于class的RNNLMs的使用不仅引进了词分类时的性能敏感性,也很难将不规则大小class特定权重矩阵的训练并行化以便进一步加速。在我们之前的工作中,采用了带完整输出层的RNNLMs,在GPU上以串(或minibatch)模式有效训练,能并行处理多路训练句子。拼接句子串技术用来最小化句子长度变化引入的串流之间的同步开销。拼接句子串的想法在图2中描述。多个句子被拼接进N个串流之一(N为串的规模)。在训练过程中,一个N维的输入词向量通过在每个流中取一个词而构成。目标词向量通过在每个流中取下一个词而构成。
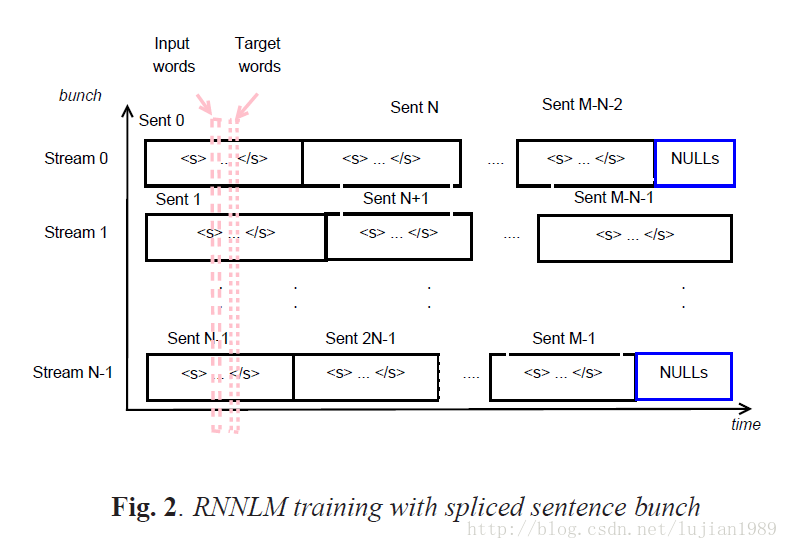
在最先进的语音识别系统中,RNNLMs通常与n-gram语言模型进行线性插值,以取得良好的上下文覆盖和强泛化能力。差值权重
3. NNLM/RNNLM训练工具包
目前有许多实现了循环神经网络的工具包,比如Theano、Torch、TensorFlow、Chainer和CNTK。对于语言建模,还有若干专用于神经网络语言模型训练的开源工具包。当前展示3个流行的工具包。
CSLM是前馈神经网络语言模型的一个有效实现。它包含CPU和GPU版本,允许通过高效并行算法和重采样技术处理大量训练数据。
RNNLM可能是第一个专为语言建模设计的RNNLM工具包。它允许基于class的RNNLMs使用少量数据在CPU上高效训练。当隐藏层大小增加时训练速度急剧降低。RNNLM工具包也提供各类函数的recipes,包括困惑度评估、N-best重打分和文本生成。CUED-RNNLM工具包最初基于RNNLM工具包,提供类似的调试信息和模型格式。
RWTHLM提供基于长短时记忆(LSTM)RNNLMs的实现以及基于class的输出层。该工具包的特色是基于CPU的RNNLM训练的更有效实现。然而,随着隐藏层大小增加训练速度下降的类似问题仍然存在。
在本文中,我们描述了CUED-RNNLM,全输出层RNNLM高效训练的基于GPU的实现。CUED-RNNLM工具包以C++实现,在BSD许可下自由获取,版权来自于RNNLM工具包。
4. CUED-RNNLM中的训练
CUED-RNNLM包含FRNNLM训练、评估以及通过采样进行文本生成。训练和采样使用GPU,模型评估在CPU上进行。
4.1 交叉熵(CE)训练
RNNLM训练的常用目标函数基于交叉熵(CE),
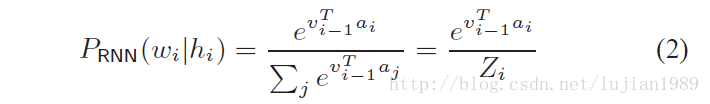
对于以上问题我们的解决方法是在RNNLM训练过程中学习一个常量的历史独立的softmax归一化项。如果归一化项
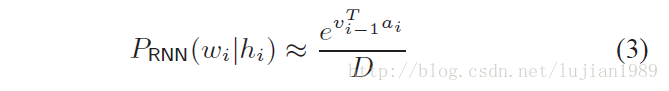
使用这一理念,CUED-RNNLM实现了两个改进的训练准则:方差正则化(VR)和噪声对比估计(NCE)。
4.2 方差正则化(VR)
方差正则化(VR)显式添加正则化项的方差至标准的CE目标函数。相关的目标函数如下:
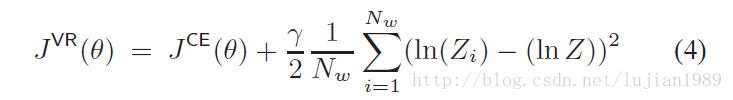
其中
4.3 噪声对比估计(NCE)
在NCE训练时,训练语料库中的每个词假定通过两种不同的分布生成。一个是数据分布,也就是RNNLM,另一个是噪声分布,通常使用一元模型。目标函数是为了在训练数据和一组随机生成的噪声样本上区分这两种分布。如下式所示:
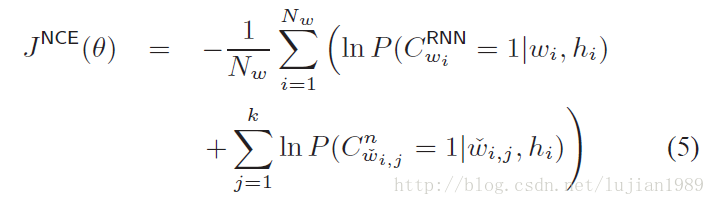
其中,
在NCE训练过程中,归一化项
5. CUED-RNNLM中的模型评估
测试集的困惑度(PPL)和词错误率(WER)用来评估语音识别任务中语言模型的性能。CUED-RNNLM工具包提供函数来计算困惑度、N-best重打分和lattice重打分。
5.1 困惑度计算
困惑度能够使用RNNLMs单独计算,或者与n-gram语言模型线性插值。通过CPU来计算使用归一化概率的全输出RNNLMs的实际困惑度效率很低,加入GPU困惑度计算是未来的工作。
5.2 N-best重打分
N-best列表能通过诸如SRILM工具包,由词lattices生成。然后,由RNNLM计算的带语言模型打分的句子级log似然被推算出,N-best列表重新排列。注意当使用VR或NCE训练的RNNLMs时,式3中的未归一化概率能够使用。
5.3 Lattice重打分
同样支持使用RNNLMs的lattice重打分。使用CUED-RNNLM训练的模型可通过HTK3.5的lattice处理工具HLRescore的一个扩展来使用。这一lattice重打分扩展也能够作为HTK3.4.1的补丁获得。通过一个转换工具,也能支持Kaldi格式的lattices。
6. 其他特色
RNNLM可通过采样来生成大量文本。然后在生成的文本上训练一个n-gram语言模型,并与一个基线语言模型进行插值。所得语言模型能作为初始RNNLM的近似,直接用于初步解码和/或lattice重打分。
在CUED-RNNLM中还有一些其他特色。支持含多个隐藏层的RNNLM。当前,只有第一个隐藏层允许有循环连接。额外的值能添加至输入层,例如主题特征。同时实现了RNNLM的句子独立/依赖模式训练。在句子独立模式的RNNLM训练中,输入层的历史向量
在许多应用中,训练数据来自不同的源。在RNNLM训练中训练数据的顺序显著影响性能。为了在领域内测试数据上获得优异性能,建议在RNNLM训练时首先将领域外数据输入网络,在更重要的领域内训练数据处理之前。因此,训练时训练数据不是随机打乱的。建议对于每个数据源,将句子顺序随机化作为前置处理步骤,同时保持数据源之间的顺序。
工具包除了标准的NVIDIA CUDA库用于基于GPU的计算之外,不依赖其他第三方库。调试信息和输出类似于RNNLM工具包。命令参数的详细描述可在网上的工具包文档中查找。
7. 实验
实验基于AMI会议语料库,评估在语音识别上下文中不同类型RNNLM的性能。在用于声学模型训练的全部78小时语音中,包含了大约1M声学转写的词(包括句子开头和结尾)。另外有8个会议独立于训练集,作为开发和测试集。
一个以序列训练为特色的Kaldi声学模型训练recipe应用至深度神经网络(DNN)训练中。将FMLLR转换的MFCC特征作为输入,4000个聚类状态(senones)作为聚类目标。训练的DNN有6个隐藏层,每层有2048个隐藏节点。
Fisher语料库的13M词汇的第一部分也用来进一步提高语言建模性能。使用了49k词汇的解码词典。33k的RNNLM输入词典构建于解码词典和LM训练数据中所有词汇的交集。22k最常用词选取作为输出词典。BPTT算法用于之前5词误差反向传播的RNNLM训练。本文所有RNNLM使用了一个隐藏层。平均训练10个迭代至收敛。当前部分所有语言模型在(AMI+Fisher)联合的14M词汇训练集上训练。使用AMI转写的1M词汇的实验结果可在网上的文档中找到。
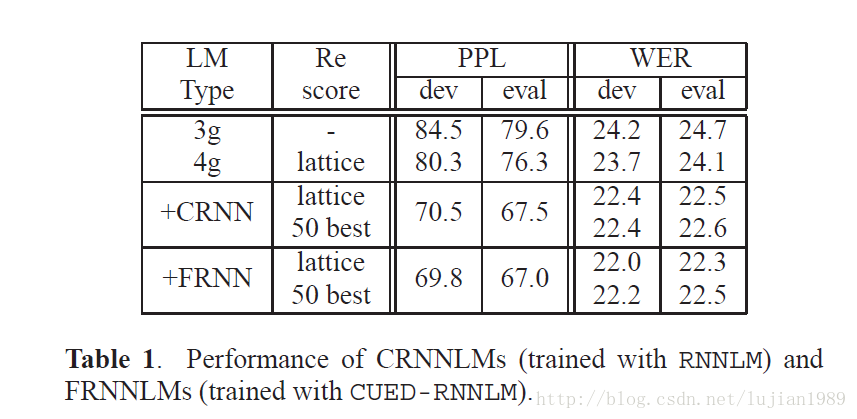
第一个实验是评估RNNLMs的性能。一个剪枝的3-gram语言模型用于初步解码,随后是未剪枝的4-gram语言模型用于lattice重打分。在RNNLM训练过程中,AMI语料库(1M)置于Fisher数据(13M)之后。带512个隐藏节点的RNNLMs使用交叉熵准则训练。表1展示了通过RNNLM和CUED-RNNLM工具包训练的RNNLMs的性能。RNNLMs相对于基线的4-gram语言模型在困惑度和词错率(WER)上有了显著提升。CUED-RNNLM训练的完整输出层RNNLM稍微胜于RNNLm训练的基于class的模型。重打分lattices和50-best列表给出了可比较的1-best(Viterbi)性能。通过RNNLM重打分lattices的混淆网络解码,取得了额外的词错率绝对减少0.2%,而通过重打分50-best列表的混淆网络解码则没有提升。
下一个实验研究使用50-best重打分时不同准则训练的FRNNLMs性能。Fisher和AMI语料库在连接放进一个训练数据文件前被单独打乱。打乱数据能使词错率稍微下降(注:数据打乱对于CRNNLMs没有提升)。VR和NCE训练的RNNLMs性能在表2中展示。使用CE、VR及NCE各自训练的RNNLMs给出了可比较的性能。为了取得稳定的收敛,基于NCE的训练相比CE基线需要多两个迭代。
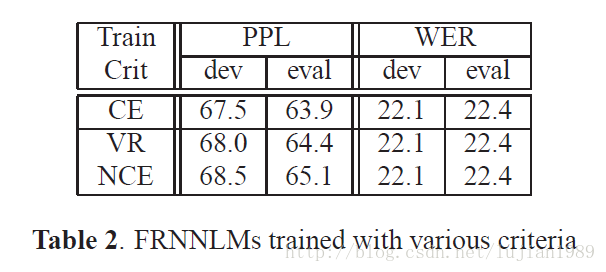
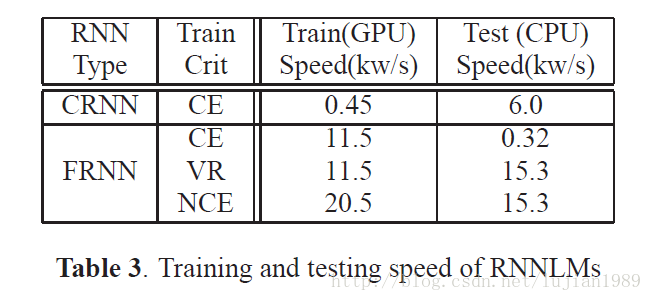
表3展示了RNNLMs的训练和评估速度。使用一台带双Intel Xeon E5-2680 2.5GHz处理器的电脑,单进程进行基于CPU的CRNNLM训练和评估。使用NVIDIA GeForce GTX TITAN GPU训练FRNNLMs。正如期望一样,在GPU上的FRNNLM训练比在CPU上训练的CRNNLM快得多,且NCE训练提供了进一步的速度提升。在测试阶段,使用VR和NCE准则训练的FRNNLMs也比CRNNLMs要快2.5倍以上。
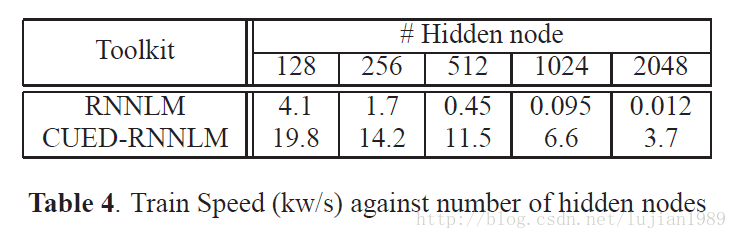
训练速度严重依赖隐藏层大小。表4比较了一系列隐藏节点数时,使用RNNLM和CUED-RNNLM的训练速度。可以看到较小隐藏层时CRNNLMs是高效的。然而当隐藏层大小提高时,训练速度急剧下降。当隐藏层大小从128提高到2048节点,CRNNLM每秒处理的词数量下降至1/340,即12个词。相比之下,FRNNLMs的训练速度对于隐藏层大小的提升不那么敏感。这表现了CUED-RNNLM对于网络大小较好的伸缩性。
8. 结论和未来工作
我们介绍了CUED-RNNLM工具包,其提供了基于GPU训练RNNLMs的高效实现。全输出层RNNLMs使用方差正则化或噪声对比估计在GPU上训练,然后在CPU上高效评估。还有若干特色计划在将来添加进来。包括基于RNNLM的长短时记忆(LSTM),以及支持更多灵活的RNNLM模型结构。关于该工具包的所有资源可以从http://mi.eng.cam.ac.uk/projects/cued-rnnlm/下载