1. pip install gym
可以看到,增强学习和监督学习的区别主要有以下两点:
1. 增强学习是试错学习(Trail-and-error),由于没有直接的指导信息,智能体要以不断与环境进行交互,通过试错的方式来获得最佳策略。
2. 延迟回报,增强学习的指导信息很少,而且往往是在事后(最后一个状态)才给出的,这就导致了一个问题,就是获得正回报或者负回报以后,如何将回报分配给前面的状态。
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value function,又叫效用函数)来表明当前状态下策略π的长期影响。
价值函数:第二行有错误多写了一个γ.
当一个策略取定,就是说Si,ai 这个数组取定.那么拟合下面这个等比函数.
其中ri表示未来第i步回报,
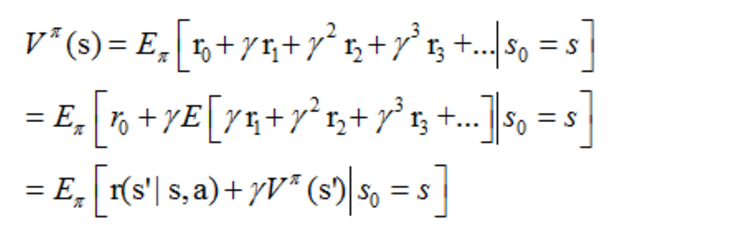
PageRank算法简介
http://blog.jobbole.com/71431/
1.基本方法是矩阵不停的乘法,一直到收敛
2.利用加个概率来更改迭代公式即可解决终止点问题和陷阱问题.
重新学机器学习:
https://blog.csdn.net/supercally/article/details/54754787
https://blog.csdn.net/Young_Gy/article/details/73485518