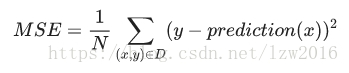版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lzw2016/article/details/82389701
线性回归模型
视频和文章中分别描述了两个例子:通过房屋面积来预测房价,通过虫鸣声来预测温度
通过虫鸣声来预测温度,如图
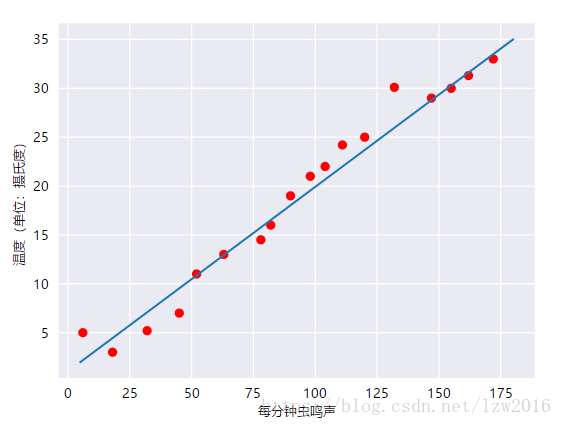
线性关系很简单,
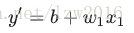
不难理解,这里的 y’ 使我们预测的值,b 是偏差,W1 是特征1的权重,X1 是特征1
对于多个特征 Xi 而言,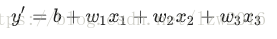
我们的目的就是得到理想的权重和偏差,使得预测标签尽可能趋近实际观察标签
,这就是接下来要说到的训练,损失
训练和损失
训练 模型就是通过大量的有标签样本来学习得出所有权重和偏差的理想值,并检查多个样本寻求构建损失最小的模型(这一过程称为经验风险最小化)
损失 是对于 单个样本 而言模型预测的准确程度,是一个数值。
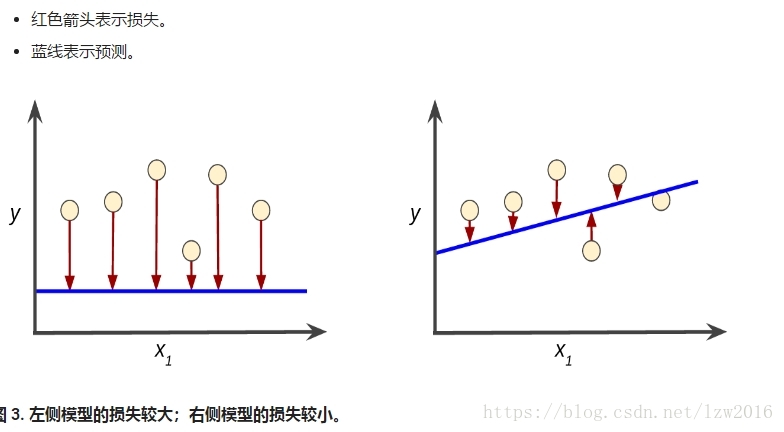
损失函数
- 平方损失(L2损失)
对单个样本而言,平方损失为
=(observation - prediction(x))^2
=(y - y')^2观察值减去预测值的平方
- 均方误差
对于数据集D(含有N个有标签样本(x,y)),N个样本的平方损失之和除以N