Coursera课程《Using Databases with Python》 密歇根大学 Charles Severance
Week1 Object Oriented Python
Unicode Characters and Strings
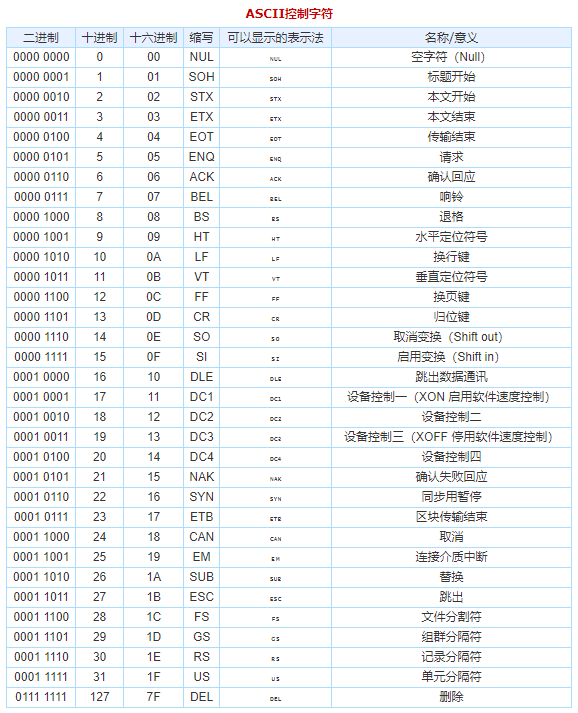
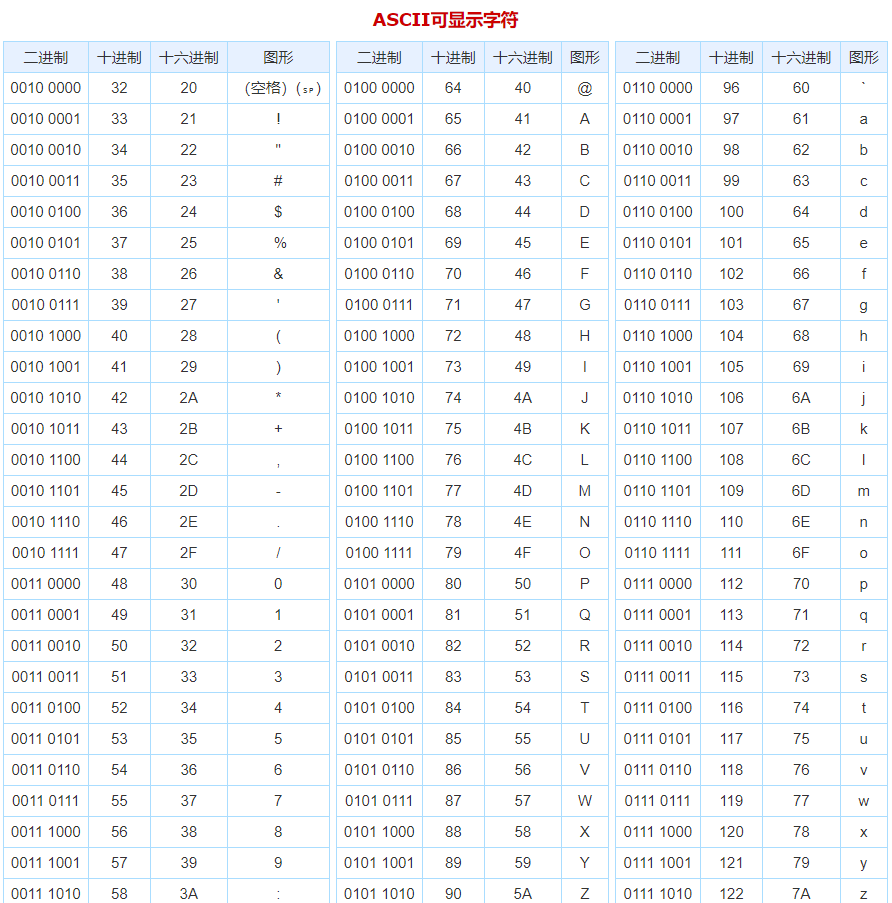
每个字符都被数字0到256之间的数字所表示,以此来存储在8比特的内存里。这个码我们成为ASCII码。
下表来自ASCII码对照表

Multi-Byte Characters
为了显示更广范围的字符,电脑不得不处理大于1byte的字符。
- UTF-16 2bytes
- UTF-32 4bytes
- UTF-8 1-4bytes
重点说下UTF-8编码方式现在非常流行,我们在代码里输入输出中文、日文等字符都要使用这种编码方式。所以不管是要跨操作系统还是跨什么什么,都强推使用UTF-8的编码方式。
在Python3,所有的字符串都是Unicode。
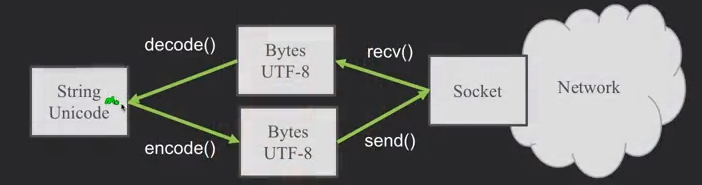
Python Strings to Bytes
while True:
data = mysock.recv(512) #这里是bytes
if (len(data) < 1):
break
mystring = data.decode() #这里变成了unicode
print(mystring)An HTTP Request in Python
import socket
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect(('data.pr4e.org', 80))
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\n\n'.encode() # 转换成bytes
mysock.send(cmd)
while True:
data = mysock.recv(512)
if (len(data) < 1):
break
print(data.decode())
mysock.close()也就是下图这个原理。