文章题目:Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition(CVPR2018)
http://openaccess.thecvf.com/content_cvpr_2018/papers/Sun_Optical_Flow_Guided_CVPR_2018_paper.pdf
摘要部分:开头一句话指出motion representation在人体动作识别中起着至关重要的作用,然后就直接切入自己的模型的简介,本文引入了一个新的紧凑的motion representation,叫做optical flow guided feature(OFF)。OFF是从optical flow的定义中发源而来的,并且和optical flow正交。之后又介绍了一些其他OFF的特征,最后简介了一下实验情况。
既然是叫optical flow guided feature,又和optical flow正交,那么就要先介绍一下optical flow。传统的optical flow当中有一个很著名的限制,叫做brightness constant constraint
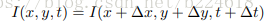
这里面I表示像素值,x,y,t分别是空间两个维度和时间一个维度,△x,y,t表示的是很小的变化量。而对于feature level,也就是从原始像素值中用函数得到的feature,也有类似的表述

也就是不仅亮度在时空上具有连续性,对于坐标值的小改变是不变的,由亮度值计算出来的feature也是具有这种稳定性的。用p=(x,y,t)来表示一个位置,那么将上式可改写为
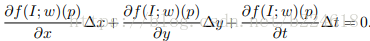
如果两边都除以△t,那么就得到
这里面的vx和vy两个东西物理意义暂不明确,被称作volecity of feature point at p,feature点的速度,而对于x,y,t求的偏导数也就是对空间和时间求的梯度。当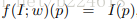
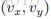


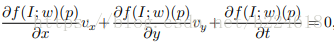

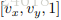
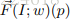
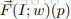
网络结构的概览可以用下图表述
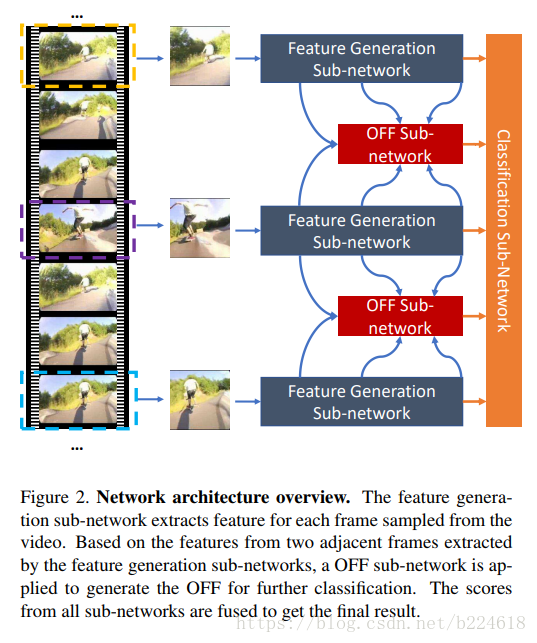
整个网络有三个子网络,,三个子网络各有各的用处。分别是feature generation sub-network,OFF sub-network,classification sub-network。feature generation sub-network就用普通的CNN网络抓取出一些基础的feature,然后OFF sub-network再从中抓取出OFF feature,接着,这些feature会输入到一些堆叠在一起的residual block之中进一步获得更加精细的feature,这两个sub-network输出的feature再输入到classification sub-network得到最终的分类结果,更加精细的网络结构图可以见下图
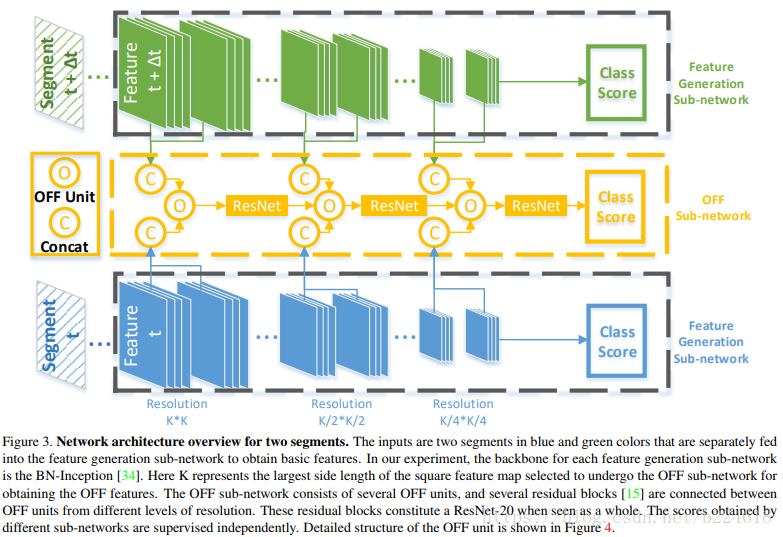
首先,基础的feature 
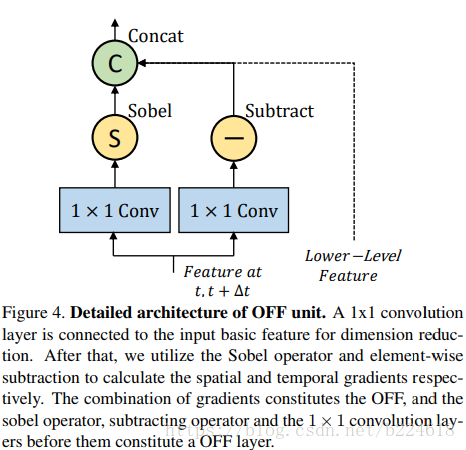
首先输入的feature map的每一个位置都会使用一个1×1的卷积核将feature的channel数变成所需的固定大小,本文中是无论输入多少都变成128维的。之后用sobel算子计算空间维度上的梯度,用相邻帧对应位置像素值相减获得时间维度的梯度,这些梯度都计算完了就是得到了OFF了,将他们连接在一起并且连接上上一个level输出的lower level OFF feature,之后输入到residual network中,sobel算子其实很简单,如下所示

这个是分别生成x和y方向的梯度数据,也就是一个固定权重的kernel,用来计算像素值的差值。
在连接不同OFF unit的residual block中,OFF的dimension还会进一步减小,节约计算资源。residual block使用的是ResNet-20,不使用batchnorm,作者声称是为了避免过拟合。此外,OFF unit其实是可以加到一般的CNN layer中来辅助模型的。
最后是classification sub-network,classification sub-network将不同来源(指的应该是figure3中的三个score,但是有一点很疑惑,就是t和t+△t不都是原video吗?这两个的输出score有啥区别呢)feature拿来,分别使用inner-product classifier得到相应的classification score,对于所有sampled frames得到的classification score(这里说的又像是从video中提出的每一帧feature map都要计算一个相应的classification score)通过取平均值的方式合并在一起。这里其实不是很清楚最终的分类结果到底是怎么输出的,之后作者又介绍了,采取和TSN一样的设置,video中不是每一个frame都参与计算的,是要抽样的,抽取出来的每一个frame对应一个segment(一般来讲segment不一定是frame),每一个segment都会输出一个class score,对于OFF sub-network的各个segment的输出score通过average pooling来得到一个sub-network level的score,为了获得video-level的score,还需要考虑feature generation sub-network的输出score,也可以采取同样的average pooling的方法进行处理。此外,本文的feature generation sub-network和OFF sub-network是分开训练的,第一阶段是用已有的手段训练feature generation sub-network,第二阶段是固定feature generation sub-network,然后训练OFF sub-network。
总结一下,本文提出的representation名字叫做optical flow guided feature,但是实际计算的是时空的梯度,好像只是介绍了一下这个feature和feature level optical flow正交,之后就再也没用到过optical flow。此外,我觉得这个对时空计算梯度,计算差值的思想其实是本文的关键,因为处理video的问题,需要抓取的就是变化的信息,有一篇skeleton based action recognition的论文中也采取了类似的手段,计算了相邻两帧的关节坐标值的差值作为motion data,然后再进行feature extraction。