LinkedHashMap继承于HashMap,同样实现了Map接口,与HashMap不同的是,LinkedHashMap的插入取出是有序的,并且可以控制。先看一下数据结构
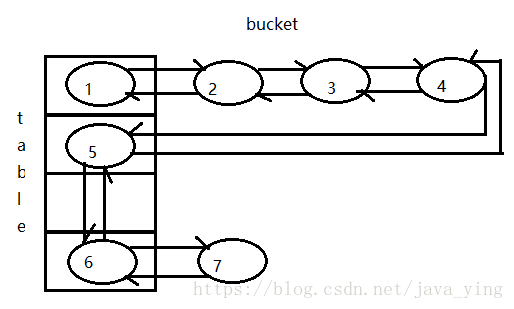
其中数字是表示结点插入的顺序,可以看到的是LinkedHashMap用链表将每个元素串起来,数据结构为 数组+单链表+红黑树+双链表。
先看LinkedHashMap的几个属性,因为继承了HashMap,所以HashMap中的非private属性的字段都可以直接进行访问
transient LinkedHashMap.Entry<K,V> head;//链表头结点
transient LinkedHashMap.Entry<K,V> head;//链表尾结点
final boolean accessOrder; //访问顺序
构造函数:
public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; }
public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; }
public LinkedHashMap() { super(); accessOrder = false; }
public LinkedHashMap(Map<? extends K, ? extends V> m) { super(); accessOrder = false;
//调用的是父类的方法 putMapEntries(m, false); }
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
accessOrder参数为true表示可以控制访问顺序,默认都是false的,只有在参数中传入才可为true。
其他函数:
newNode()
//当哈希桶中的结点类型是HashMap.code时,调用这个方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//根据传入参数生成对应的Entry结点
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//把这个结点插入双向链表的结尾 linkNodeLast(p); return p; }
这个方法会在调用put()方法时被调用。每次都将新结点插入到链表末尾,维护了插入的顺序。其中这个Entry<k,v>是继承自HashMap.Node<k,v>,增加了首尾的指针功能
static class Entry<K,V> extends HashMap.Node<K,V> {
//首尾指针
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
newTreeNode()
//当哈希桶中结点为HashMap.TreeNode时调用这个方法
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
//根据传入参数生成新的treeNode结点
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
//把这个结点插入到双向链表的末尾 linkNodeLast(p); return p; }
afterNodeAccess()
void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last;
//如果accessOrde参数为true并且访问的结点是不hi尾结点
if (accessOrder && (last = tail) != e) {
//记录p的前后结点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p的后结点制空
p.after = null;
//如果p的前结点为空,a为头结点
if (b == null)
head = a;
//p的前结点不为空,b的后结点为a else b.after = a;
//p的后结点不为空,a的前结点为b
if (a != null)
a.before = b;
//p的后结点为空,后结点为最后一个结点 else last = b;
//如果最后一个结点为空,头结点为p
if (last == null)
head = p;
//如果最后一个结点不为空 p链入最后一个结点后面 else { p.before = last; last.after = p; }
//尾结点为p
tail = p;
++modCount;
}
}
这里有点乱 慢慢理一理就清楚了哈,这个函数会在很多函数中被调用,LinkedHashMap重写了HashMap中的此函数。如果访问顺序为true并且访问的对象不是尾结点,假设访问的结点为2,如图
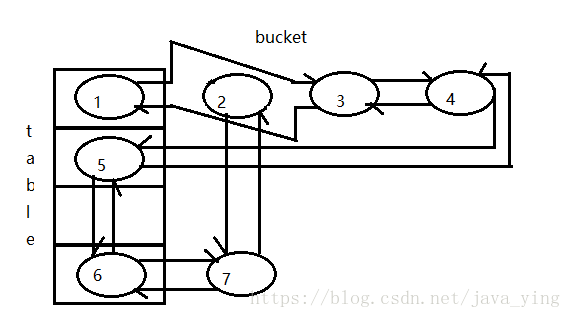
将结点3放到了链表的尾部
这篇主要解释了LinkedHashMap为什么是有序的以及按照指定顺序的存储方法。在HashMap的基础上看LinkedHashMap压力还是很小的。我会继续努力的,也欢迎指正问题~~