最近在学习自然语言处理,在建立基础标签库时,遇到一个需要提取语料中的英文单词的工作,做好了现在来和大家分享下。
实现效果:读取文件内容,把其中的英文单词提取出,并统计词频。提取时,原本不是连在一起的单词可以分开独立提取,例如:我的PPT和WORD,可以提取出PPT,WORD两个单词。
基本思想:如果直接用正则表达式把其他非字母字符都过滤掉,那么剩下的英文单词就会连在一起了,所以,在处理时,应该保留下分隔英文单词的字符。首先文本可能会存在乱七八杂的符号,先把这些符号过滤掉(包括数字也可以过滤掉,看自己需要),然后剩下的就是英文和中文啦,这时候再把英文按中文分开提取就好啦。
举个栗子:我要处理的文本内容是:我的#……¥@PPT和#@WORD
第一步:过滤乱七八糟符号后(用正则表达式就好啦),变为:我的PPT和WORD
第二步:把中文换为*号(同样用正则表达式就好啦),变为:**PPT*WORD
最后:按*号分开提取(用StringTokenizer),变为:PPT WORD
也就是这样的逻辑:
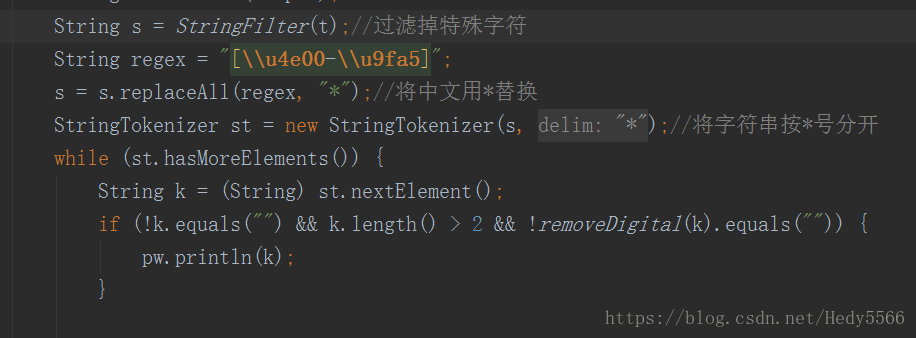
--------------------------------------------------------图片用来看,代码用来粘---------------------------------------------------------------------------
String s = StringFilter(t);//过滤掉特殊字符
String regex = "[\\u4e00-\\u9fa5]";
s = s.replaceAll(regex, "*");//将中文用*替换
StringTokenizer st = new StringTokenizer(s, "*");//将字符串按*号分开
while (st.hasMoreElements()) {
String k = (String) st.nextElement();
if (!k.equals("") && k.length() > 2 && !removeDigital(k).equals("")) {
pw.println(k);
}
}
主要使用的就是正则表达式,如下:
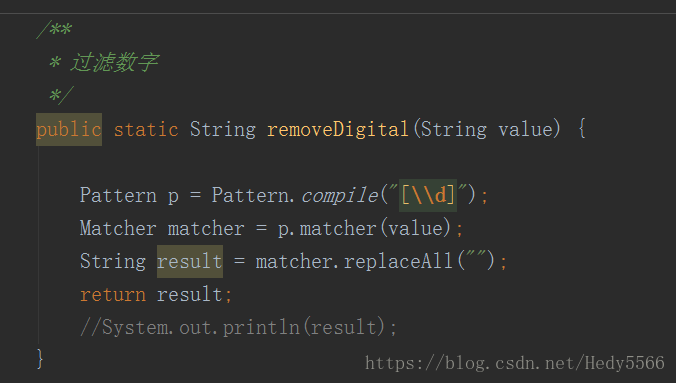
public static String removeDigital(String value) {
Pattern p = Pattern.compile("[\\d]");
Matcher matcher = p.matcher(value);
String result = matcher.replaceAll("");
return result;
//System.out.println(result);
}
public static String StringFilter(String str) {
// 清除掉以下特殊字符
String regEx = "[^(a-zA-Z0-9\\u4e00-\\u9fa5)()() ())($]";
return str.replaceAll(regEx, " ");
}
下面附上常见的统计词频和排序的方法啦:
/**
* 统计出现的词的个数
*/
public static void FileCharacter(String fileName) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(new File(fileName)));
Map<String, Integer> map = new HashMap<String, Integer>();//用于统计各个单词的个数,排序
String line;
while (null != (line = br.readLine())) {
//将字符串用空格分隔
String[] ss = line.split("\\s+");
for (String s : ss) {
if (map.containsKey(s)) {
map.put(s, map.get(s) + 1);
} else {
map.put(s, 1);
}
}
}
Set<String> keys = map.keySet();
sort(map,"");
}
public static void sort(Map<String, Integer> map, String sql) throws IOException {
List<Map.Entry<String, Integer>> infoIds = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(infoIds, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return (o2.getValue() - o1.getValue());
}
}); //排序
PrintWriter p = new PrintWriter(new OutputStreamWriter(
new FileOutputStream("该自己写路径了"), "utf-8"), true);
for (int i = 0; i < infoIds.size(); i++) { //输出
Map.Entry<String, Integer> id = infoIds.get(i);
String k = id.getKey();
if (!k.equals("") && k.length() > 2 && !removeDigital(k).equals("")) {
p.print(id.getKey() + ":" + id.getValue());
p.print("\n");
}
}
p.close();
}
}