目录
文件描述符的分配规则
最小分配原则
通过代码理解:
//这是一个演示文件描述符分配的demo
//1:文件描述符是一个数字,并且这个数字是一个结构体的下标
//分规则:寻找最小的未使用下标
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<errno.h>
//#include<sys/types.h>
//#include<sys/stat.h>
int main()
{
int fd = -1;
fd = open("./test",O_RDONLY | O_CREAT);
if(fd < 0)
{
perror("open");
return -1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}
输出为:fd:3
关闭0/2
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<errno.h>
int main()
{
int fd = -1;
fd = open("./test",O_RDONLY | O_CREAT);
if(fd < 0)
{
perror("open");
return -1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}
结果为 fd:0
文件描述符分配规则:在file_struct数组中,找到当前没有被使用的最小的一个下标,作为新的文件描述符
重定向原理
将原本描述符所对应的下标文件描述符修改成另一个文件的描述符,这样的话描述符没有变,
但是真正通过描述符操作的这个文件已经改变了
如果关闭1:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<errno.h>
int main()
{
close(1);
int fd = open("tmp",O_WRONLY | O_CREAT,0644);
if(fd < 0)
{
perror("open");
return -1;
}
printf("fd:%d\n",fd);
fflush(stdout);
return 0;
}

本来应该输出到显示器上的内容,输出到了文件tmp上。其中fd = 1
这种现象的本质叫做输出的重定向。常见的重定向有>,>>,<
函数名: dup2
功能: 复制文件描述符
用法: int dup2(int oldfd,int newfd);
printf()是c库的IO函数,一般往stdout输出,但是stdout在底层访问文件的时候还是找fd:1,
但是fd:1的下标所标示的内容已经变成了myfile的地址,不再是显示器文件的地址,所以
任何消息都会往文件中写入,进而完成输出重定向
总结:本质上就是改变描述符(下标)所对应的文件描述符
FILE
因为IO相关的函数系统调用的接口对应,并且库函数封装系统调用
所以本质上访问文件都是通过fd访问的,所以c库中的FILE结构体内部,必定封装了fd
#include<stdio.h>
#include<string.h>
int main()
{
const char *msg1 = "printf\n";
const char *msg2 = "fwrite\n";
const char *msg3 = "write\n";
printf("%s",msg1);
fwrite(msg2,strlen(msg2),1,stdout);
write(1,msg3,strlen(msg3));
fork();
return 0;
}
运行结果:

为什么对进程实现输出重定向结果会改变呢?
printf和fwrite都输出两遍(库函数),而write只输出了一次(系统调用)
肯定与fork有关
- 一般c库文件写入函数时是全缓冲的,而写入显示器是行缓冲的
- printf和fwrite库函数会自带缓冲区,当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲
- 我们放在缓冲区的数据就不会被立刻刷新
- 但是在进程退出的时候会统一刷新,写入文件中
- fork时父子数据会发生写时拷贝,所以当父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据
- write没有变化,所以没有所谓的缓冲
总结
printf和fwrite库函数都会自带缓冲区,而write系统调用没有缓冲区
我们这里所说的都是用户级缓冲区,库函数有,而系统调用没有,库函数是系统调用的上层
是对系统调用的封装,足以说明该缓冲区是二次加上的,因为又是c,所以由c标准库提供
理解文件系统
ls -l:(stat命令也可以)

除了看见文件名还有相关数据:
- 模式
- 硬链接数
- 文件所有者
- 组
- 大小
- 最后修改时间
- 文件名
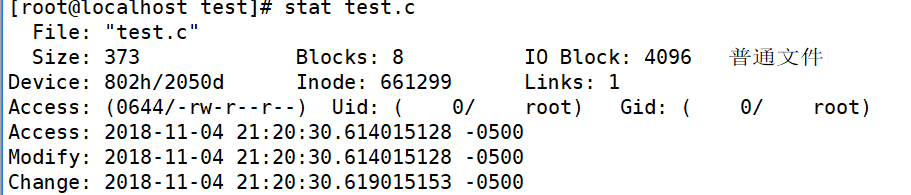
A:最后访问时间
M:文件内容最后修改时间
C:属性最后修改时间
inode是什么
- 文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
- 操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
- 文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
inode内容
inode包含文件的元信息,具体来说有以下内容:
-
文件的字节数
-
文件拥有者的User ID
-
文件的Group ID
-
文件的读、写、执行权限
-
文件的时间戳,共有三个:ctime指inode创建时间,mtime指文件内容上一次修改的时间,atime指文件最后一次访问的时间。
-
链接数,即有多少文件名指向这个inode
-
文件数据block的位置

目录项:目录下的文件名和文件inode节点号
查找一个文件流程:打开目录文件,读取其中目录项信息,通过文件名来找到文件的inode节点号
在通过inode节点号找到文件系统在inode区域中的inode节点,再通过inode节点中储存的文件数据储存位置
找到文件在数据区域储存的数据
创建一个新文件操作
- 储存属性:内核先找一个空闲的节点,把文件信息记录到其中
- 数据储存:可以将信息分块记录在不同磁盘块中
- 记录分配情况:内核在inode的磁盘分布区间记录存放块位置顺序
- 添加文件名到目录:内核将入口添加到目录,文件名和inode之间对应关系将文件名和文件的内容及书写连接起来
硬链接
我们在磁盘上找到的文件并不是文加名,而是indoe,其实在linux中可以让多个文件名对应一个inode
硬链接更像是一个文件的别名,他有自己的目录项,但是并没有单独的inode节点和数据区,它的inode节点和数据区是和源文件是相同的,一个文件,每多一个硬链接,那么它的inode节点中有一个链接数属性,都会+1,代表这个inode节点对应了好多个文件名,可以通过任何一个文件目录项访问到相同的inode节点。
那么我们删除一个文件时候,实际上是先将inode节点中的链接数-1操作,党政链接数为0时,就认为这个文件真的要被删除了,这时候才会释放inode节点和数据区

- Q和P链接状态完全相同,它们被称为指向文件的硬链接,内核记录了这个连接数,inode787455的硬链接数为2
- 我们删除文件时干了两件事,1:在目录中将对应的记录删除2:将硬链接数-1,如果为0对应的磁盘释放
软链接
硬链接是通过inode引用另外一个文件,软链接是通过名字引用另外一个文件
软链接是一个独立的文件,有自己的目录项,inode节点,数据区
可以看做是一个快捷方式,通过这个软链接可以找到另一个为位置的其他文件
软链接文件是linux的特殊类型文件(符号链接文件 |)这个文件中所保存的数 据就是指向另一个文件的路径名,这个软链接文件就是通过这个路径名来定位所指向的文件

文件具备所有权限,并且文件类型是l(link:链接(符号链接文件:软链接))
软硬链接区别:
- 软链接可以针对目录创建,硬链接不可以
- 软链接是一个新的文件,而硬链接是源文件的一个别名(与源文件使用相同的inode)
- 软链接可以跨分区建立(记录路径可以找见),硬链接不可以(不同分区inode节点指向不同地方)
- 删除源文件后,软链接找不到源文件,硬链接无影响(inode链接数-1)
动态库和静态库
- gcc默认链接方式:动态链接 ---动态库
- 动态库:程序运行时才去链接动态库的代码,多个程序可以共享使用库的代码
- 静态链接需要加上 -static ---静态库
- 静态库:编译时把代码链接到可执行文件中。程序运行的时候将不再需要静态库
- 原则上都是将所写的文件打包成一个文件供别人使用
如何生成自己的动态库和静态库
- 程序编译过程:预处理---编译---汇编---链接
- 生成一个库其实就是将所有的代码打包起来,最终得到一个库文件
- 生成动态库:gcc
- 生成静态库:ar
- 需要先将源码文件编译成自己的目标文件(动态库可以gcc直接从源码生成),也就是从c ---.o
- 最终这些.o文件链接在一起生成动态库还是静态库或者可执行文件,取决于链接过程!
- 如果要生成的是一个库文件,那么这些代码中不能有main函数
如果要生成的是一个可执行程序,那么这些代码中有切只能有一个main函数 - 静态库:将所有的.o文件打包到一起生成
- 生成命令:ar -cr lib文件名.a 文件名.a(-c 创建 -r 模块替换)
- 动态库生成:--share是生成动态库的gcc链接选项,没有这个将认为生成可执行程序将所有.o文件打包
- 生成命令: gcc --share 文件名.o -o lib文件名.so
- 要生成一个动态库,gcc编译器告诉我们,在编译阶段,将一个.c--- .o需要加上一个编译选项
-fPIC:产生位置无关代码
使用 -fPIC 选项,会生成 PIC 代码。.so 要求为 PIC,以达到动态链接的目的,否则,无法实现动态链接
(动态库映射到虚拟地址空间时对应的位置是不确定的,因此不能生成绝对路径的地址) - 动态库是一个运行时库,需要在程序运行时也加载到内存中,并这个加载的过程是操作系统干的,回去指定位置加载动态库,因为我们需要将动态库放到指定的位置才可以运行程序
如何链接一个库生成可执行程序
gcc main.c -o main -L./ -ltest
-Lpath 用于指定库的查找路径
-lname 用于指定链接的库名称(去掉前后缀)