网址:https://www.imooc.com/video/10688 (已经完成 还没复习)
接下来的计划:
1 https://www.imooc.com/learn/736(还没完成)
2 https://www.imooc.com/learn/1017(还没完成)
3 https://edu.hellobi.com/course/156 (还没完成)
4 资料: https://zhuanlan.zhihu.com/p/21479334(还没完成)
5 …… https://blog.csdn.net/Joovo/article/details/80027308
6 正则表达式补习及应用
简单爬虫(不需要登录的)
url管理器+
网页下载器 urllib2
网页解析器
架构实例: 百度百科的1000页面数据
自动从url出发,访问想要访问的url
简单爬虫架构:(运行流畅)
最开始: 调度器!
↓询问
爬虫调度端: (获取.还给调度器)
url管理器 (已有+暂未)
↓
传送给网页下载器 (字符串传输-->网页解析器)
↓解析器
↓应用(输出)
url管理器:防止重复/循环抓取
还会循环死锁...
所以,添加/获取的时候需要判断。
实现方式:内存,可以存在set()之中
也可以是关系数据库(mySQL)
缓存数据库(redis) (这里)
网页下载器:
urllib2(官方基础模块)
requests第三方的
#urllib2.urlopen(url)
方法1:
import urllib2
response= urllib2.urlopen('http://www.baidu.com'
print response.getcode()#状态码
#emmmmmm...我们引入了urllib2这个库,根据状态码看请求是否成功cont=response.read() #进行读取...
方法2:
传送数据:
添加data,header,传送给urllib2.request
继续urllib2.urlopen
完整代码:
import urllib2
request=urllib2.request(url)
request.add_data('a','1')
request.add_data('user-agent',")
还有一些,是使用了handler来传输的,同理有
opener=urllib2.build_opener(handler)
urllib2.install_opener(opener)
继续补充就行...

直接添加一个url或者添加一个request
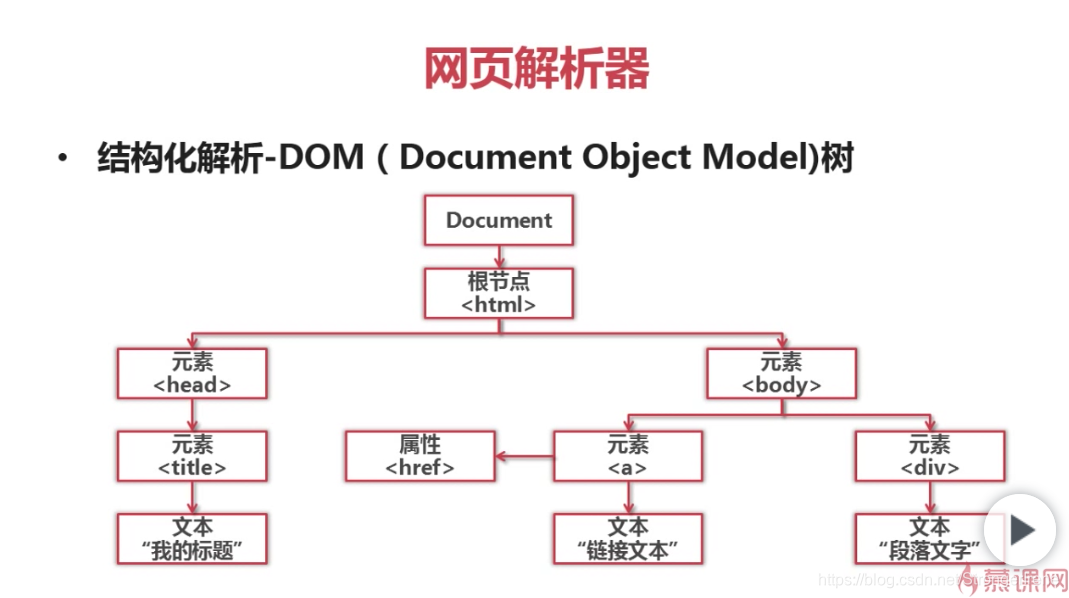
网页解析器:
从网页中提取有价值数据的工具。
定向爬虫—>html网页字符串 新的url+数据信息
[网页解析器的分类]
1.正则表达式 (模糊匹配) 若文档复杂就麻烦了
2.html.parser(自带)
3.beautiful soup 第三方 (可以使用↑↓ *3 结构化解析)
4.lxml 第三方插件;…
这样,先把文件下成Document Object Model树
以树的结构来解析
所以安装beautiful soup吧
其实还是没有的。
Mark
# python开发简单爬虫课程 5-2
# urllib2的三种方法!
import urllib2
import cookielib
import bs4
print bs4
response=urllib2.urlopen('http://www.baidu.com')#进行一个请求
print response.getcode()
print len(response.read())
# -----------↑获得状态码 ↓ 先创建一个request对象,再往这个对象里添加数据,获得结果~
request=urllib2.Request('http://www.baidu.com')
request.add_header('User-Agent','Mozilla/5.0')
# 直接添加头部 , 直接添加头部, 直接添加头部.... 这个作为参数,直接又给提交过去^
response=urllib2.urlopen(request)
# woooo 有点神奇哦 [request和response当然不一样!]
print response.getcode()
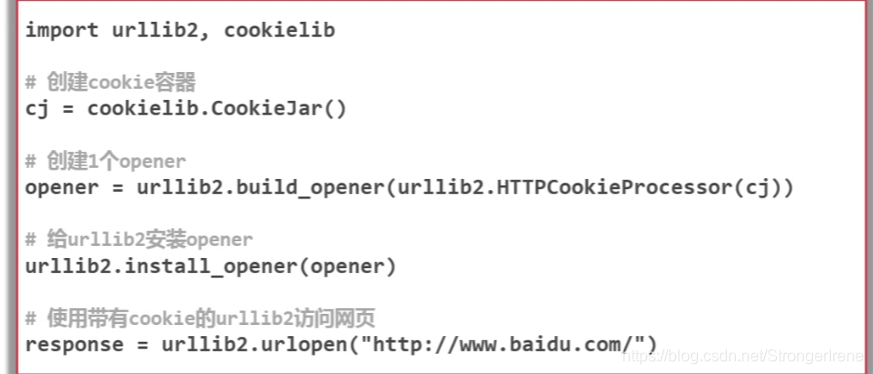
# -----添加cookie的处理
cj= cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response=urllib2.urlopen('http://www.baidu.com')
print response.getcode()
print cj # 直接打印一下cookie的内容....beautiful soup
可以按照结点的名称、属性、内容进行搜索。
可以利用:
<a herf='123.html' class='article_link> python </a>
名称是a 属性是href和class 内容是python
(1)先创建一个对象:
soup = BeautifulSoup{
htm_doc,# 字符串
'html.parser' # html解析器!!! 解析器!!!
from_encoding='utf-8' # html文档的编码!!
}(指定编码)
(2)
然后再find_all
(name,attrs树形,string名字)
string---(显示的文字)
class_ 是为了避免关键字冲突~
然后,我们当然还可以继续访问结点的信息啦~
node.name 获取找到的标签名称
node['href'] 获取a结点的href树形...
get_Text()可以获得链接文字
www.curmmy.com/software/BeautifulSoup/bs4/doc/#installing-beautiful-soup
稍微总结一下:
bs对象,包含的是,字符串,解析器,编码,然后就可以find了,find_all用法也是一样。然后就是前面的是标签名字 后面属性 然后string 显示的文字名字 下面开始就是代码
【正则表达式,是 】
A herf=re.complie(r”ill”)).
嗯嗯 是这样的 还不错哦 r是为了出现的时候写一个反斜线(只要写两个-->写一个)
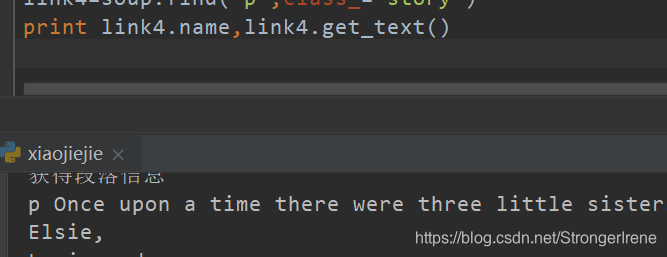
Name呢其实直接就是p了~~~
代码:(记得回顾哦)
import urllib2
import cookielib
import bs4
import re
from bs4 import BeautifulSoup
# 第二步 我们来看看其他的吧 [上一节的也有 要及时复习哦
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#
soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
print "获取所有的链接"
links=soup.find_all('a') # 标签名字为a的就可以!!!
for link in links:
print link.name,link['href'],link.get_text()
# 【!!这里!a.name 直接 就能拿到 没那么像是c++里面的i】
# link.name 不用links[link]
# .... 还是要多敲代码啊!!!!!!
print "获取特定链接"
link2=soup.find('a',href="http://example.com/tillie")
print link2.name,link2['href']
print "使用正则"
link3=soup.find('a',href=re.compile(r"ill"))
print link3.name
print "获得段落信息"
link4=soup.find('p',class_="story")
print link4.name,link4.get_text()
'''翻车总结:
'a' 要加引号
记不得用法...!
'''

六、如何进行爬虫开发?
确定、分析目标、编写代码
注意url格式(限定范围),数据格式(词条页面中!),网页编码(在头部看)
哇~ 网页编码在头部有,url格式在随便点个链接【它是不完整的,要加上前面。。。才能访问~】,数据格式分析相关网页。。。。
找到目标,入口页,我们需要获取的词条页面的
【url格式】
【数据格式】
标题和简介(数据格式)在标签里面的位置和n内容
【页面编码】
emmm,这里是分package和module的~
主,下载器,url管理器,解析器,ouput
主程序以一个url为入口点,爬取相关东西
-------------------
11.19爬虫复习
调度~~
url管理器+ 网页下载器 + 网页解析器
urllib2的方法哦,总结一下~
import urllib2, cookielib
response=urllib2.openurl("....)
response.add_header(".....)
我觉得关键就是response=urllib2.urlopen('......)鸭
soup=BeautifulSoup(html_doc,'html.parser',from-encoding='utf-8')
这是先创建了一个对象!!!!
【对象!! 创建了一个树,下面就可以进行搜索了~】
soup就可以用去解析了
link=soup.find_all('a)
for link in links
link.name link['href'] link.get_text()
定义好了这个craw方法,我们就开始爬它啦...
管理 下载解析输出
--------------------------------
发现爬不出来,回去找视频
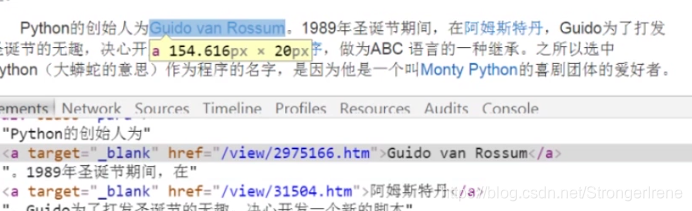
发现没有,教程里是view、现在是item了

而且! 发现,其实,这个就是百科后面套的地址,那么就可以来测试一下了。
emmmm.. 这个网页不存在,直接failed,那么~
后面也一样的,不过dd那里,div class那里都没改(继续看,看有关标题+有关下面简介的说明)
所以呢~ 最后我发现原来是我某个地方少写了一句话……
然后就是~ 百度百科现在只要
links= soup.find_all('a',href=re.compile(r"/item/"))就可以了 因为有小小的改版 最后运行的非常缓慢 好歹也算是可以了 感觉像是在写实验报告

还有 html变成了乱码.
ummm代码先贴一下qaq希望不要怪罪 版权在最上面有
自行对应
# coding:utf-8
# mark: 自动引入的方法 先放在最右边 然后左移 就可以自动引入了ovo
# mark: 快捷键就是 alt+enter!!!!! [alt+enter!!] eclipse是ctrl+ 1
# 一定要对齐, 不然就没有主函数了呀..
# ctrl alt l 一键格式化但是和格式热键冲突qaq
from baike_pc import html_downloader, html_parser, html_output, url_manager
class SpiderMain(object):
def __init__(self):
#self.new_urls = set()
#self.old_urls = set()
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_output.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
# 把根目录的url先加入之后,一旦有新的就把新的
# 把新的爬取,下载,解析,输出
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print ("url is %d : %s") % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
# 这一步就是解析了... 解析出了新的url和数据过来~
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 3000:
break
count = count + 1
except:
print "craw failed"
# 然后再对它们分别进行操作~~
self.outputer.output_html()
if __name__ == "__main__":
# 首先 入口url
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
管理器
# coding:utf-8 url管理器
class UrlManager(object):
# 爬取过的url列表 和等待爬取的url
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
else:
return
def add_new_urls(self, urls):
if urls is None or len(urls)==0:
return
# 否则
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls)!=0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url下载器
# coding:utf-8 html下载器
import urllib2
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response= urllib2.urlopen(url)
if response.getcode()!=200:
return None
# else:
return response.read()
# 下载器只要download就好了 一个解析器***
# coding:utf-8 解析器
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
# /view/123.htm
# r"/view/\d+\.htm"
new_urls=set()
links= soup.find_all('a',href=re.compile(r"/item/"))
for link in links:
new_url= link['href']
new_full_url=urlparse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data={}
# url
res_data['url']=page_url
# !!.. <dd class="lemmaWgt-lemmaTitle-title">
# <h1>Python</h1>
title_node=soup.find('dd',class_="lemmaWgt-lemmaTitle-title").find('h1')
res_data['title']= title_node.get_text()
summary_node=soup.find('div',class_="lemma-summary")
# <div class="lemma-summary"
# 这个当然也要记录下来了...
res_data['summary']= summary_node.get_text()
return res_data
def parse(self, page_url, html_cont):
# 从cont中拿到url和数据~
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont,"html.parser",from_encoding='utf-8')
new_urls=self._get_new_urls(page_url,soup)
new_data=self._get_new_data(page_url,soup)
return new_urls,new_data输出器
# coding:utf-8 输出器
class HtmlOutputer(object):
def __init__(self):
self.datas=[]
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open("output.html","w")
fout.write("<html>")
fout.write("<head>")
fout.write('<meta charset="UTF-8">')
fout.write("</head>")
fout.write("<body>")
fout.write("<table>")
# python 默认是ascii的编码 我们想要改变的话要encode成utf-8的
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['title'].encode('utf-8'))
fout.write("<td>%s</td>" % data['summary'].encode('utf-8'))
fout.write("</tr>")
fout.write("</body>")
fout.write("</table>")
fout.write("</html>")
fout.close()emmm... 我太菜了-.-
不想出去吃火锅//.... 没钱/