我们按如下方式设置了对数几率回归,
z=wTx+b,
a=y^=σ(z),
L(a,y)=−(1−y)log(1−y^)−ylog(y^).
在对数几率回归中,我们想要做的是修改参数w和b,以减少L。我们已经描述了在单个训练示例中实际计算损失的四个传播步骤,现在让我们谈谈如何反向计算导数。
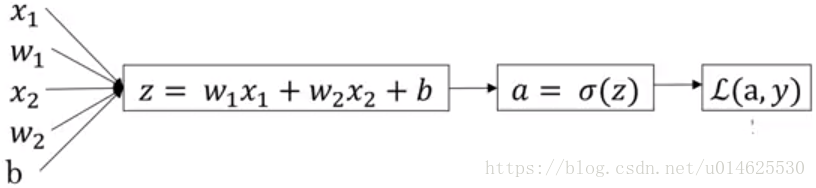
因为我们想做的是关于这种损失的计算导数,我们反向计算时要做的第一件事就是计算
∂L∂a=ya+1−y1−a
。
然后
∂L∂z=∂L∂a∂a∂z=a(1−a)(ya+1−y1−a)=a−y
。
最后计算关于w和b的微分
∂L∂w1=x1∂L∂z,
∂L∂w2=x2∂L∂z,
∂L∂b=∂L∂z.
因此对数几率回归梯度下降计算的方向是:
w1:=w1−α∂L∂w1,
w2:=w2−α∂L∂w2,
b:=b−α∂L∂b.
其中
α
是学习率。
上面是只有一个训练样本时的对数几率回归的梯度下降方向,
现在我们想要为m个训练样本的对数几率回归进行梯度下降操作。
整体的成本函数
J=1m∑mi=1L(a(i),y(i)),
然后
∂J∂wi=1m∑∂L(a(i),y(i))∂wi。
令
α
是学习率,然后梯度下降每次迭代的更新公式为:
w1:=w1−α∂J∂w1,
w2:=w2−α∂J∂w2,
b:=b−α∂J∂b.