该论文提出了一种半监督学习的生成对抗哈希算法(即SSGAH):
-
文中分别定义了生成模型、判别模型与深度哈希模型共同实现算法框架的搭建
-
采用了Triplet Loss作为损失函数
-
利用无类标样本参与训练,即利用半监督学习方法进行训练网络
-
文中提出了半监督损失函数、对抗损失函数来学习二进制哈希码,尽可能的让语义相似的二进制码距离更近
文中所提出的算法框架如下图所示:
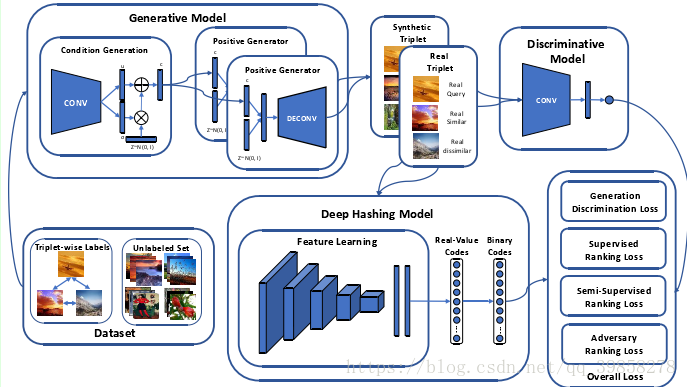
由于在解决图像检索相关问题中,未标记的数据往往非常充裕,然而已经标注的数据却及其稀少且获取成本太高,倘若只利用少量的已标注数据训练网络,得到的效果会非常差,并且浪费了大量的未标记数据资源,故本文使用半监督学习方法,共同训练网络。
标记数据表示如下:
未标记数据表示如下:
生成模块产生的三元组表示如下:
真实类标数据三元组表示如下:
算法框架中的判别模块用来区分生成模块生成的伪数据构成的三元组和真实类别数据构成的三元组。
算法中的生成模块采用卷积网络对已知数据集学习特征分布,利用学习到的特征的均值方差分布进行高斯分布数据生成并反卷积得到伪图像的生成。
-
优化损失函数:
在生成对抗模型中,最重要的关键部分就是损失函数的选择,通过最大最小化损失函数来进行对抗学习,本文中首先通过对已有数据集图片进行提取得到的向量,与高斯噪声向量进行连接作为输入输入至正反例生成器中,产生伪数据三元组,与真实数据三元组一起进行对抗学习,损失函数如下所示,其中Dkl为正则项,KL分解:
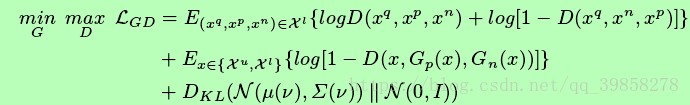
深度哈希网络通过如下函数将sigmoid层输出转化为二进制码:
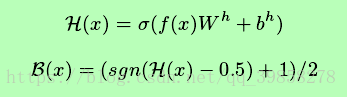
由于大部分数据是未被标记的数据,为了利用上这些数据,本文采用半监督学习方法,其中监督学习损失函数如下所示:
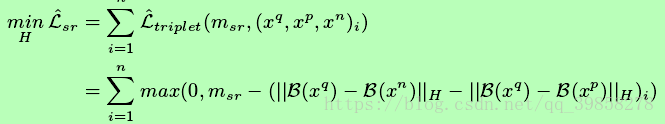
半监督学习损失函数如下所示:
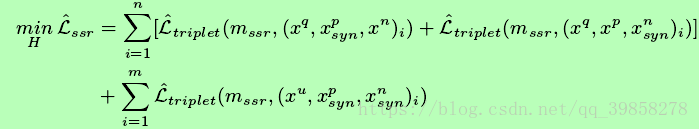
对抗学习损失函数如下所示:

总损失函数如下所示:
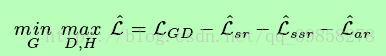
由于海明距离的计算是不可微的,二进制映射函数是不连续的,故用欧氏距离取代海明距离,得到的松弛损失函数与总损失函数如下所示:
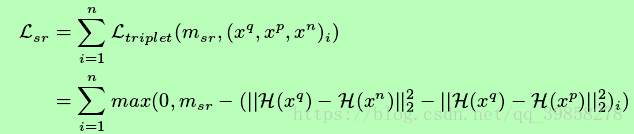
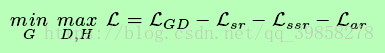
-
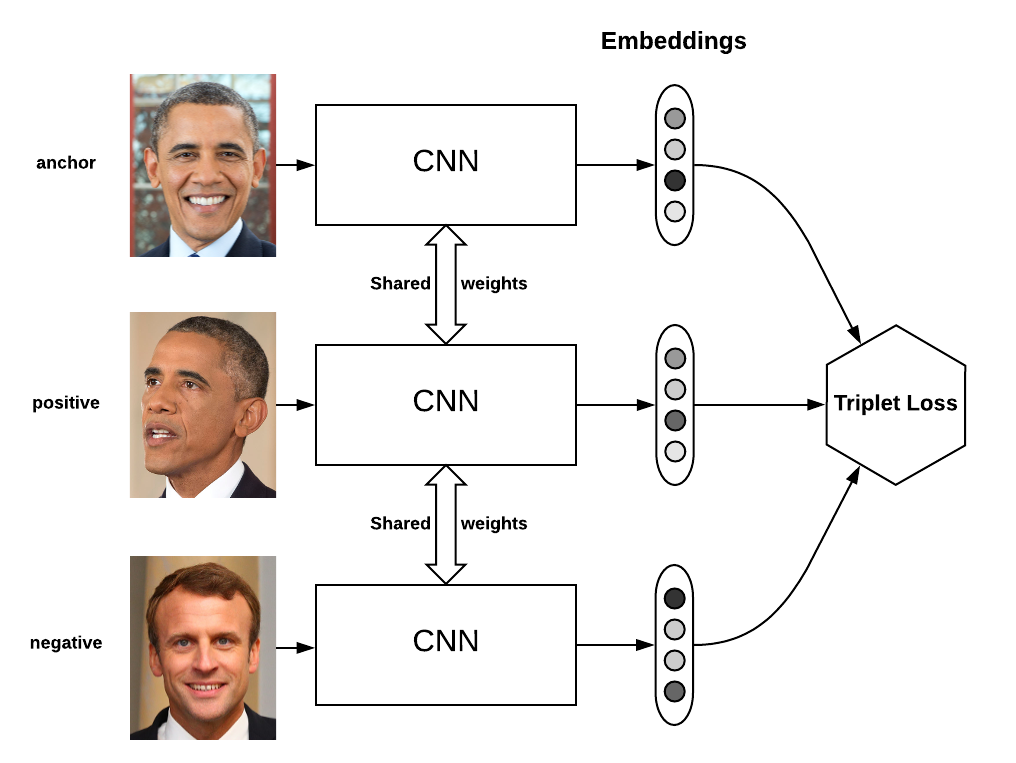
Triplet Loss:
三元组损失函数使具有相同标签的样本在嵌入空间中尽量接近,使具有不同标签的样本在嵌入空间中尽量远离,示意图如下所示:
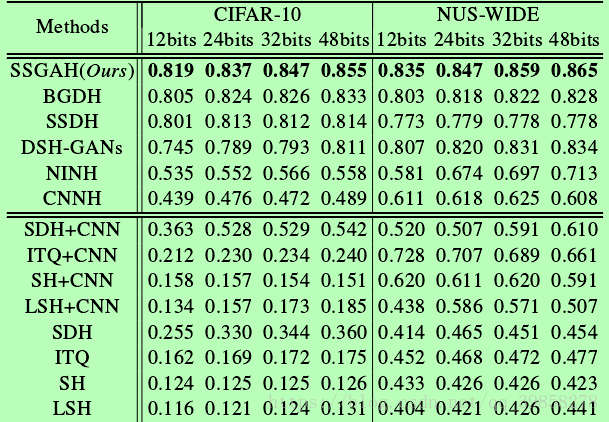
以上是本文的算法思想,之后本文在cifar-10数据集与NUS-WIDE数据集上进行了测试分析,结果如下所示:
在已出现图片上测试结果:
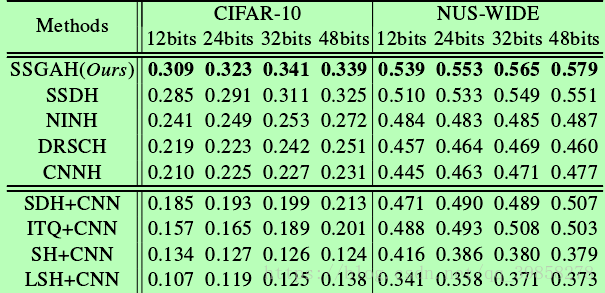
在未出现图片上测试结果:
图中绿色图片为本文算法输出的图片,蓝色是不加对抗损失的结果,红色是不加对抗损失与数据集特征分布生成模块的结果(其中第一行为输入图片,第二行是生成的正例图片,第三行是生成的反例图片):
