激活函数的作用
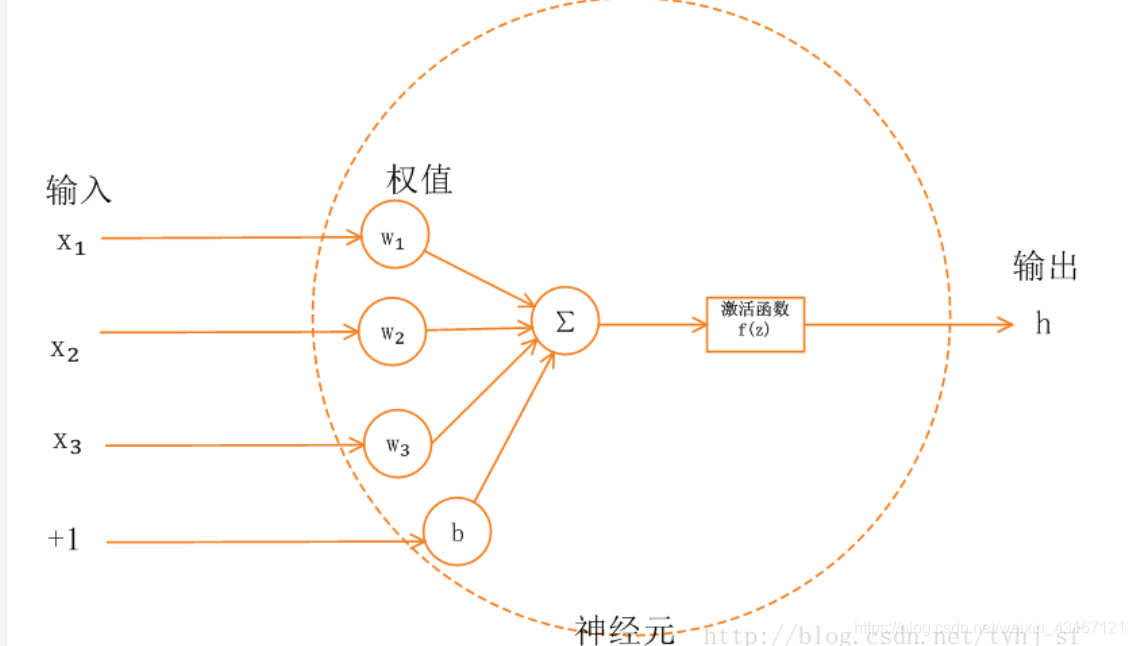
可以想象,如果没有激活函数,下一层的输入总是上一层的输出,无论多少层网络,都是线性函数,线性函数的逼近能力是非常有限的,无法拟合现实中这些没有规律的非线性复杂函数。举个例子:
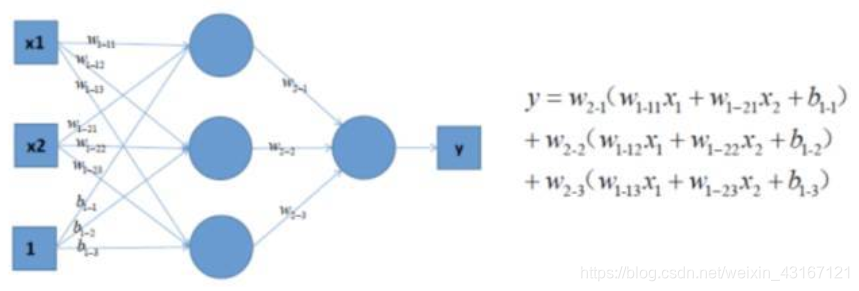

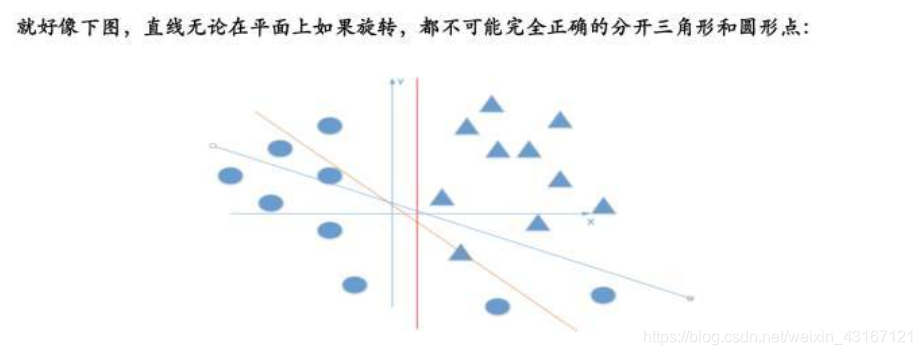
个人理解为把有规律线性函数用激活函数扭曲,层数越深扭曲次数越多,经过深层网络的扭曲之后,鬼知道是个什么函数,剩下的交给反向传播自己训练去把。
各种激活函数
1.Sigmoid激活函数:
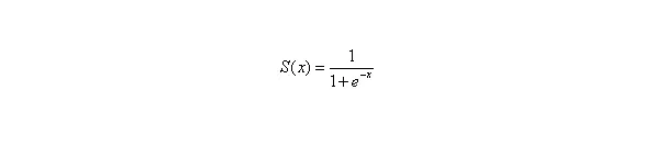
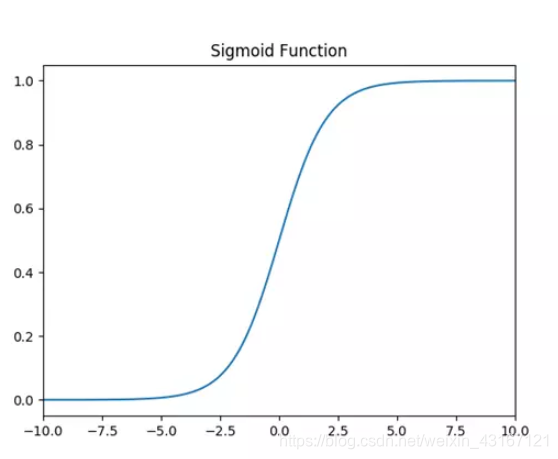
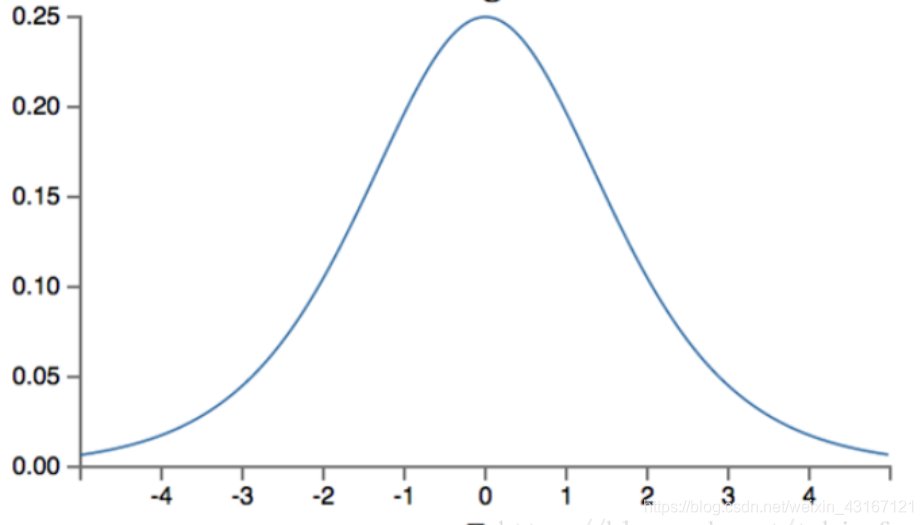
缺点:1.在深度神经网络中梯度反向传递时导致梯度消失,Sigmoid函数的导数如下:
每传递一层梯度值都会减小为原来的0.25倍,如果神经网络隐层特别多,那么梯度在穿过多层后将变得非常小接近于0,即出现梯度消失现象;

2.tanh激活函数
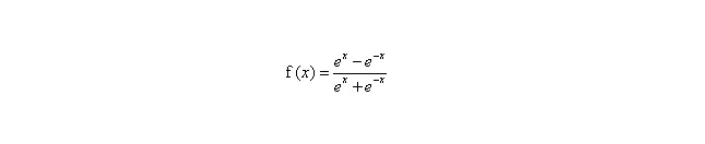
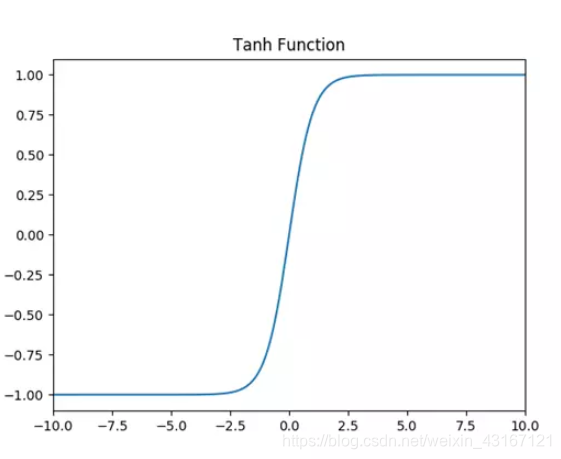
求导图像:
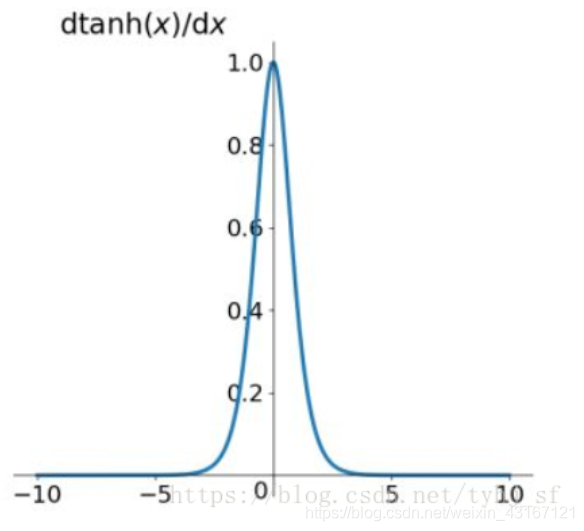
它解决了Sigmoid函数的不是0均值输出问题,然而,梯度消失的问题和幂运算的问题仍然存在。梯度消失问题相对于sigmoid要有所缓解。
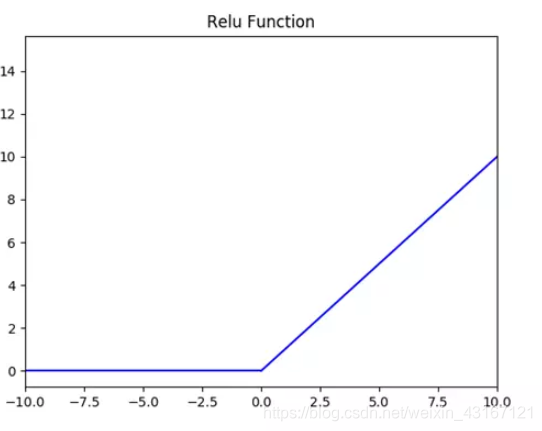
3.Relu激活函数
f(x) = x if x>0
0 if x<=0
求导如图:
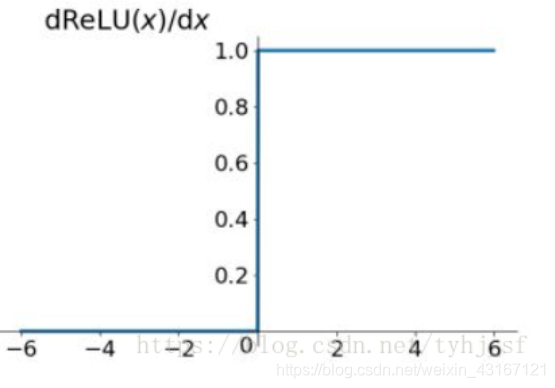
ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
1) 解决了梯度消失问题 (在正区间)
2)计算速度非常快,只需要判断输入是否大于0
3)收敛速度远快于sigmoid和tanh
ReLU也有几个需要特别注意的问题:
1)ReLU的输出不是0均值
2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见(w都是负的) (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
对于(2)解释:
假设有一个神经网络的输入W遵循某种分布,对于一组固定的参数(样本),w的分布也就是ReLU的输入的分布。假设ReLU输入是一个低方差中心在+0.1的高斯分布。
在这个场景下:
大多数ReLU的输入是正数,因此
大多数输入经过ReLU函数能得到一个正值(ReLU is open),因此
大多数输入能够反向传播通过ReLU得到一个梯度,因此
ReLU的输入(w)一般都能得到更新通过随机反向传播(SGD)
现在,假设在随机反向传播的过程中,有一个巨大的梯度经过ReLU,由于ReLU是打开的,将会有一个巨大的梯度传给输入(w)。这会引起输入w巨大的变化,也就是说输入w的分布会发生变化,假设输入w的分布现在变成了一个低方差的,中心在-0.1高斯分布。
在这个场景下:
大多数ReLU的输入是负数,因此
大多数输入经过ReLU函数能得到一个0(ReLU is close),因此
大多数输入不能反向传播通过ReLU得到一个梯度,因此
ReLU的输入w一般都得不到更新通过随机反向传播(SGD)
发生了什么?只是ReLU函数的输入的分布函数发生了很小的改变(-0.2的改变),导致了ReLU函数行为质的改变。我们越过了0这个边界,ReLU函数几乎永久的关闭了。更重要的是ReLU函数一旦关闭,参数w就得不到更新,这就是所谓的‘dying ReLU’
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
4.Leaky Relu激活函数

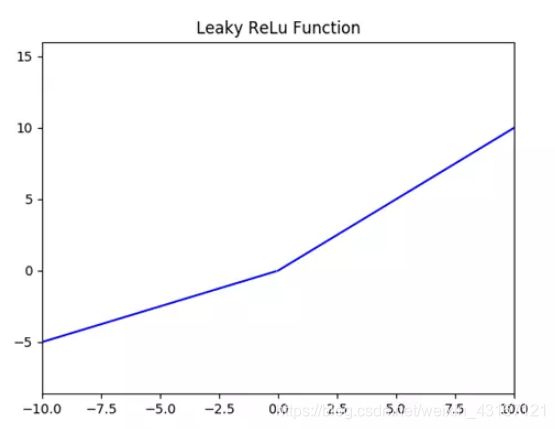
理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
5.PRelu激活函数 (参数化修正线性单元)
和leaky relu类似 , 只不过在x<0时,a这个系数不是固定不变的,是根据数据来定的,是可学习的。


6.R-relu激活函数(参数化修正线性单元)

负值的斜率在训练中是随机的,在之后的测试中就变成了固定的了。RReLU的亮点在于,在训练环节中,aji是从一个均匀的分布U(I,u)中随机抽取的数值。
7.elu激活函数
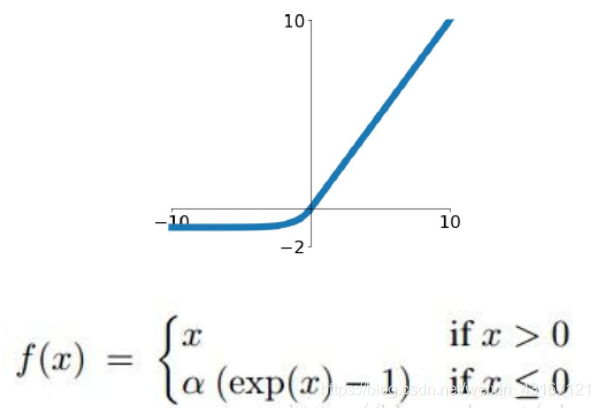
可以看做是介于relu和LeakyReLU之间的一个东西。不会有Dead ReLU问题,输出的均值接近0。当然,这个函数也需要计算exp,从而计算量上更大一些。
还有些不常见的等到遇到再补充把。
参考链接:
https://www.jianshu.com/p/d49905dee072
https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/tyhj_sf/article/details/79932893
https://blog.csdn.net/m0_37870649/article/details/79782143
https://blog.csdn.net/disiwei1012/article/details/79204243