深度学习 | 训练网络trick——label smoothing(附代码)
在多分类训练任务中,输入图片经过神级网络的计算,会得到当前输入图片对应于各个类别的置信度分数,这些分数会被softmax进行归一化处理,最终得到当前输入图片属于每个类别的概率。

之后在使用交叉熵函数来计算损失值:

最终在训练网络时,最小化预测概率和标签真实概率的交叉熵,从而得到最优的预测概率分布。在此过程中,为了达到最好的拟合效果,最优的预测概率分布为:
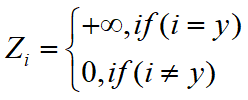
也就是说,网络会驱使自身往正确标签和错误标签差值大的方向学习,在训练数据不足以表征所以的样本特征的情况下,这就会导致网络过拟合。
2.label smoothing原理
label smoothing的提出就是为了解决上述问题。最早是在Inception v2中被提出,是一种正则化的策略。其通过"软化"传统的one-hot类型标签,使得在计算损失值时能够有效抑制过拟合现象。如下图所示,label smoothing相当于减少真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。

1.label smoothing将真实概率分布作如下改变:

其实更新后的分布就相当于往真实分布中加入了噪声,为了便于计算,该噪声服从简单的均匀分布。
2.与之对应,label smoothing将交叉熵损失函数作如下改变:
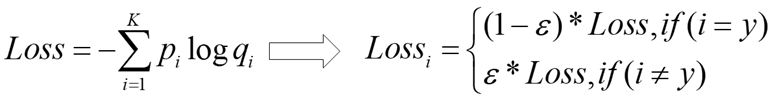
3.与之对应,label smoothing将最优的预测概率分布作如下改变:

阿尔法可以是任意实数,最终通过抑制正负样本输出差值,使得网络能有更好的泛化能力。
3.代码实现
1.修改caffe.proto添加字段
因为所有层的参数定义都存放在caffe.proto文件中,因此修改参数后需要将新的参数添加到该文件对应的层参数中,本例中就将参数添加到LossParameter中。
message LossParameter {
optional int32 ignore_label = 1;
enum NormalizationMode {
FULL = 0;
VALID = 1;
BATCH_SIZE = 2;
NONE = 3;
}
optional NormalizationMode normalization = 3 [default = VALID];
optional bool normalize = 2;
optional float label_smooth = 4;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.修改hpp文件
修改softmax_loss_layer.hpp,添加 bool has_label_smooth_; float label_smooth_;这两个参数的定义。
#ifndef CAFFE_SOFTMAX_WITH_LOSS_LAYER_HPP_
#define CAFFE_SOFTMAX_WITH_LOSS_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layers/loss_layer.hpp"
#include "caffe/layers/softmax_layer.hpp"
namespace caffe {
template <typename Dtype>
class SoftmaxWithLossLayer : public LossLayer<Dtype> {
public:
explicit SoftmaxWithLossLayer(const LayerParameter& param)
: LossLayer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>>& bottom,
const vector<Blob<Dtype>>& top);
virtual void Reshape(const vector<Blob<Dtype>>& bottom,
const vector<Blob<Dtype>>& top);
virtual inline const char* type() const { return “SoftmaxWithLoss”; }
virtual inline int ExactNumTopBlobs() const { return -1; }
virtual inline int MinTopBlobs() const { return 1; }
virtual inline int MaxTopBlobs() const { return 2; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>>& bottom,
const vector<Blob<Dtype>>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>>& bottom,
const vector<Blob<Dtype>>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>>& bottom);
virtual Dtype get_normalizer(
LossParameter_NormalizationMode normalization_mode, int valid_count);
/// The internal SoftmaxLayer used to map predictions to a distribution.
shared_ptr<Layer<Dtype> > softmax_layer_;
/// prob stores the output probability predictions from the SoftmaxLayer.
Blob<Dtype> prob_;
/// bottom vector holder used in call to the underlying SoftmaxLayer::Forward
vector<Blob<Dtype>> softmax_bottom_vec_;
/// top vector holder used in call to the underlying SoftmaxLayer::Forward
vector<Blob<Dtype>> softmax_top_vec_;
/// Whether to ignore instances with a certain label.
bool has_ignore_label_;
/// The label indicating that an instance should be ignored.
int ignore_label_;
/// How to normalize the output loss.
LossParameter_NormalizationMode normalization_;
int softmax_axis_, outer_num_, inner_num_;
bool has_label_smooth_;
float label_smooth_;
};
} // namespace caffe
#endif // CAFFE_SOFTMAX_WITH_LOSS_LAYER_HPP_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
3.修改cpp,cu文件
文件的主要修改点如下,完整代码:GitHub传送门
cpp文件:
has_label_smooth_ = this->layer_param_.loss_param().has_label_smooth();
if (has_label_smooth_ ){
label_smooth_ = this->layer_param_.loss_param().label_smooth();
}
- 1
- 2
- 3
- 4
int num_class = bottom[0]->shape(softmax_axis_) - 1;
if (has_label_smooth_ && (label_smooth_>0.F)){
for (int c=0;c<=num_class;c++){
float coeff = (c == label_value)?(1.F - label_smooth_):(label_smooth_ / float(num_class));
loss -= coeff * log(std::max(prob_data[i*dim + c*inner_num_ + j],Dtype(FLT_MIN)));;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
int num_class = bottom[0]->shape(softmax_axis_) - 1;
if (has_label_smooth_ && (label_smooth_>0.F)){
for (int c=0;c<=num_class;c++){
float coeff = (c == label_value)?(1.F - label_smooth_):(label_smooth_ / float(num_class));
bottom_diff[i*dim + c*inner_num_ + j] -= coeff;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
cu文件:
__global__ void SoftmaxLossForwardGPU()
- 1
int num_class = bottom[0]->shape(softmax_axis_) - 1;
SoftmaxLossForwardGPU<Dtype><<<CAFFE_GET_BLOCKS(nthreads),
CAFFE_CUDA_NUM_THREADS>>>(nthreads, prob_data, label, loss_data,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts, has_label_smooth_,label_smooth_,num_class);
if (has_label_smooth_ && (label_smooth_>0.F)){
for (int c=0;c<=num_class;c++){
float coeff = (c == label_value)?(1.F - label_smooth_):(label_smooth_ / float(num_class));
loss[index] -= coeff * log(max(prob_data[ndim + cspatial_dim + s],Dtype(FLT_MIN)));;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
__global__ void SoftmaxLossBackwardGPU()
- 1
int num_class = bottom[0]->shape(softmax_axis_) - 1;
SoftmaxLossBackwardGPU<Dtype><<<CAFFE_GET_BLOCKS(nthreads),
CAFFE_CUDA_NUM_THREADS>>>(nthreads, top_data, label, bottom_diff,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts, has_label_smooth_,label_smooth_,num_class);
if (has_label_smooth_ && (label_smooth_>0.F)){
for (int c=0;c<=num_class;c++){
float coeff = (c == label_value)?(1.F - label_smooth_):(label_smooth_ / float(num_class));
bottom_diff[ndim + cspatial_dim + s] -= coeff;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.编译
返回到caffe的根目录,使用make指令(下面几个都可以,任选一个),即可。
make
make -j
make -j16
make -j32 // 这里j后面的数字与电脑配置有关系,可以加速编译
- 1
- 2
- 3
- 4
5.使用
layer{
name:"loss"
type:"SoftmaxwithLoss"
bottom:"fc"
bottom:"label"
top:"loss"
loss_param{
label_smooth:0.1
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-258a4616f7.css" rel="stylesheet">
</div>
</article>