https://blog.csdn.net/stezio/article/details/87816785
论文笔记:Bag of Freebies for Training Object Detection Neural Networks
这篇论文看起来像是一种总结类文章,文中并没有提出新的结构模型之类,但是对于以前的一些做法进行了整合并应用于baseline中。也就是文中一再强调的“Bag of Freebies”,即在不改变模型结构并且不改变损失函数的情况下,不牺牲前向传播时间,将mAP提升近五个点。
论文主要贡献如下:
- 首次系统地评估了不同目标检测流程中应用的多种训练启发式方法,为未来的研究提供了有价值的实践指导。
- 提出了一种为训练目标检测网络而设计的视觉相干图像混合方法,而且证明该方法可以有效提升模型的泛化能力。
- 在不修改网络架构和损失函数的情况下,在现有模型的基础上实现了 5% 的绝对精度性能提升。而且这些提升都是「免费的午餐」,无需额外的推理成本。
- 扩展了目标检测数据增强领域的研究深度,显著增强了模型的泛化能力,减少了过拟合问题。这些实验还揭示了可以在不同网络架构中一致提高目标检测性能的良好技术。
接着一项项来说。
Visually Coherent Image Mixup for Object Detection
这里用到了mixup方法(Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond empirical risk minimization[J]. arXiv preprint arXiv:1710.09412, 2017.),详细解释见
https://www.zhihu.com/question/67472285
这里也有一些我觉得比较惊艳的解释:
https://spaces.ac.cn/archives/5693
mixup方法被证明在分类网络中减少对抗干扰方面非常成功。

本文用了较高的混合比(mixup ratio),理由是:通过增加混合比例由此产生的帧中的目标更有活力,也更符合自然表现,类似于低 FPS 电影中常见的过渡帧。
在目标检测训练过程中,通过采用保留几何形状并对齐的方式以避免在初始步骤中扭曲图像。
高混合比图例如下:

mixup原文中的混合比从beta distribution中提取出来(a=0.2,b=0.2)。然而在这篇论文中,选取a>=1,b>=1的beta distribution,因为这种分布视觉相干性更强。

考虑到上述原因,选取alpha 更大的 beta distribution。如上图所示,alpha–>0时,根据概率密度图示,采样将会非常接近0或1,mixup也会趋向于ERM(Empirical Risk Minimization)。
在目标检测中,采用mixup,得到了较为不错的效果:

Classification Head Label Smoothing
即公式:
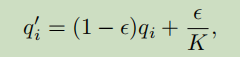
K为类别数,这也不是第一次见到了,旨在让模型更加“modest”,效果会在后面表格给出。
Data Pre-processing
本文将数据增强分为两类,几何形变和颜色抖动。
本文指出,分类任务鼓励几何形变以提升准确率,然而检测任务中需要谨慎因为检测网络对这类形变较为敏感。
在数据增强方面,本文提出一个比较有意思的说法,即:多阶段方法与一阶段相比较,多了大量的裁剪等空间变化操作,因此不需要太多的几何增强。而几何增强对于缺少空间形变一阶段网络尤为重要。这一点后面给出了实验证明。
Training Scheduler Revamping
作者指出,warm up策略对于在训练初期存在大量源自负样本的梯度,并且对大多数预测采用初始化sigmoid分类分数为0.5,偏置为0的目标检测算法尤为重要,比如YOLOv3。
有一种余弦学习率调整方案
Loshchilov I, Hutter F. Sgdr: Stochastic gradient descent with warm restarts[J]. arXiv preprint arXiv:1608.03983, 2016.

上图所示,cosine schedule结合warmup能够得到更好的validation mAP。作者认为cosine学习率能够更高频率地调整学习过程并且减轻平稳期现象。
Synchronized Batch Normalization
作者指出BN在多GPU实现时会减小batch-size,并且会在计算时各自有不同的统计数据。因此采用Synchronized Batch Normalization(Peng C, Xiao T, Li Z, et al. Megdet: A large mini-batch object detector[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6181-6189.)。
Random shapes training for single-stage object detection networks
这里没有什么可以说的,直接采用了YOLOv3中的做法,只是进行实验并重新评估了一下。
在使用了作者强调的“Bag of Freebies”之后,实验结果如下:

可以看到,如作者之前的说明,数据增强对于一阶段的网络尤为重要,而对于二阶段网络则相对没有那么重要。除此之外,上述方法也在“不增加前向传播的时间”的同时起到了提升准确率的效果。上述结果是在使用对应的方法累加之后所得。

mixup在预训练主干网络和目标检测任务中使用时能够达到1+1>2的效果:

</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-258a4616f7.css" rel="stylesheet">
</div>
</article>
这篇论文看起来像是一种总结类文章,文中并没有提出新的结构模型之类,但是对于以前的一些做法进行了整合并应用于baseline中。也就是文中一再强调的“Bag of Freebies”,即在不改变模型结构并且不改变损失函数的情况下,不牺牲前向传播时间,将mAP提升近五个点。
论文主要贡献如下:
- 首次系统地评估了不同目标检测流程中应用的多种训练启发式方法,为未来的研究提供了有价值的实践指导。
- 提出了一种为训练目标检测网络而设计的视觉相干图像混合方法,而且证明该方法可以有效提升模型的泛化能力。
- 在不修改网络架构和损失函数的情况下,在现有模型的基础上实现了 5% 的绝对精度性能提升。而且这些提升都是「免费的午餐」,无需额外的推理成本。
- 扩展了目标检测数据增强领域的研究深度,显著增强了模型的泛化能力,减少了过拟合问题。这些实验还揭示了可以在不同网络架构中一致提高目标检测性能的良好技术。
接着一项项来说。
Visually Coherent Image Mixup for Object Detection
这里用到了mixup方法(Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond empirical risk minimization[J]. arXiv preprint arXiv:1710.09412, 2017.),详细解释见
https://www.zhihu.com/question/67472285
这里也有一些我觉得比较惊艳的解释:
https://spaces.ac.cn/archives/5693
mixup方法被证明在分类网络中减少对抗干扰方面非常成功。
本文用了较高的混合比(mixup ratio),理由是:通过增加混合比例由此产生的帧中的目标更有活力,也更符合自然表现,类似于低 FPS 电影中常见的过渡帧。
在目标检测训练过程中,通过采用保留几何形状并对齐的方式以避免在初始步骤中扭曲图像。
高混合比图例如下:
mixup原文中的混合比从beta distribution中提取出来(a=0.2,b=0.2)。然而在这篇论文中,选取a>=1,b>=1的beta distribution,因为这种分布视觉相干性更强。
考虑到上述原因,选取alpha 更大的 beta distribution。如上图所示,alpha–>0时,根据概率密度图示,采样将会非常接近0或1,mixup也会趋向于ERM(Empirical Risk Minimization)。
在目标检测中,采用mixup,得到了较为不错的效果:
Classification Head Label Smoothing
即公式:
K为类别数,这也不是第一次见到了,旨在让模型更加“modest”,效果会在后面表格给出。
Data Pre-processing
本文将数据增强分为两类,几何形变和颜色抖动。
本文指出,分类任务鼓励几何形变以提升准确率,然而检测任务中需要谨慎因为检测网络对这类形变较为敏感。
在数据增强方面,本文提出一个比较有意思的说法,即:多阶段方法与一阶段相比较,多了大量的裁剪等空间变化操作,因此不需要太多的几何增强。而几何增强对于缺少空间形变一阶段网络尤为重要。这一点后面给出了实验证明。
Training Scheduler Revamping
作者指出,warm up策略对于在训练初期存在大量源自负样本的梯度,并且对大多数预测采用初始化sigmoid分类分数为0.5,偏置为0的目标检测算法尤为重要,比如YOLOv3。
有一种余弦学习率调整方案
Loshchilov I, Hutter F. Sgdr: Stochastic gradient descent with warm restarts[J]. arXiv preprint arXiv:1608.03983, 2016.
上图所示,cosine schedule结合warmup能够得到更好的validation mAP。作者认为cosine学习率能够更高频率地调整学习过程并且减轻平稳期现象。
Synchronized Batch Normalization
作者指出BN在多GPU实现时会减小batch-size,并且会在计算时各自有不同的统计数据。因此采用Synchronized Batch Normalization(Peng C, Xiao T, Li Z, et al. Megdet: A large mini-batch object detector[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6181-6189.)。
Random shapes training for single-stage object detection networks
这里没有什么可以说的,直接采用了YOLOv3中的做法,只是进行实验并重新评估了一下。
在使用了作者强调的“Bag of Freebies”之后,实验结果如下:
可以看到,如作者之前的说明,数据增强对于一阶段的网络尤为重要,而对于二阶段网络则相对没有那么重要。除此之外,上述方法也在“不增加前向传播的时间”的同时起到了提升准确率的效果。上述结果是在使用对应的方法累加之后所得。
mixup在预训练主干网络和目标检测任务中使用时能够达到1+1>2的效果:
</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-258a4616f7.css" rel="stylesheet">
</div>
</article>