
1、无监督学习聚类:
按照相似度对数据进行聚簇(cluster)划分,N个样本映射到K个簇中,每个簇至少有一个样本,一个样本只能属于一个簇,先给定一个初始划分,迭代改变样本和簇的关系,聚类的副产品可以做异常值检测
2、相似度指标有:
多维空间向量点之间的距离(闵可夫斯基距离公式):
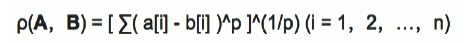
当p为2时即欧式距离(二维空间距离公式):
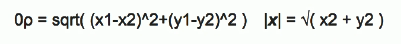
当p为1时即曼哈顿距离(Block Distance)
三维空间距离公式:
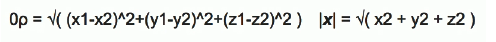
当p趋近于无穷大时即切比雪夫距离(由于维度无穷多,所有维度差值最大的维度距离差可以近似距离)
Jaccard相关系数(Jaccard similarity coefficient)比较有限样本集之间的相似度:
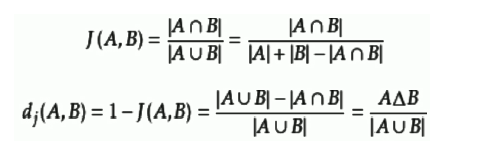

余弦相似度:余弦值区间为[-1,1],余弦值接近-1相似度越小接近0向量正交接近1相似度越大,一般用于文档相似度聚类
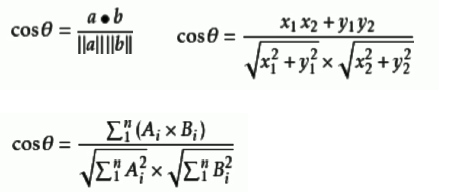
Pearson相关系数(线性相关性):
两个变量之间的协方差和标准差的商,Xi与Yi为0时即为余弦相似度公式
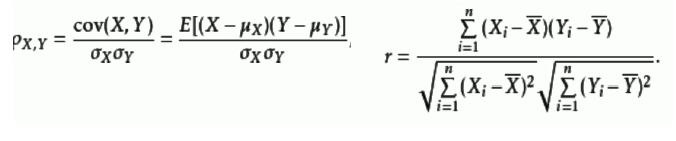
3、K-Means聚类平均数算法:
选择K个初始簇中心(随机或者先验知识即经验),迭代计算样本与每个聚类中心的距离和所属聚类的样本均值即簇中心点直到簇中心点不发生变化认为模型收敛
划分:
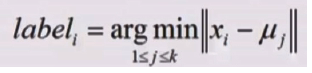
4、K-Mediods聚类中位数算法:
对K-Means聚类算法的改进以中位数作为簇中心点
5、二分K-Means算法:
两个簇样本数量少簇中心近损失函数MSE小合并为一个簇,簇中心离其他簇中心远样本数量大损失函数MSE大分为多个簇

6、K-Means++:
对K-Means聚类算法的改进,初始化中心点均有随机,使用肘部法找到最合适的K即簇的数量

K均值假设符合高斯混合分布,高斯混合分布不是线性回归凹函数,有多个极小值,可以用淬火法或遗传算法计算全局最优解,K-Means算法是根据样本到簇中心点的距离进行聚类所以算法更适合对近似圆形规则的样本进行聚类。
# !/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors
from sklearn.cluster import KMeans # 引入K-Means模块
# 引入小批量K-Means模块(计算簇中心不使用所有样本随机部分样本求簇中心,计算速度快,数据量大可以使用)
from sklearn.cluster import MiniBatchKMeans
def expand(a, b):
d = (b - a) * 0.1
return a-d, b+d
if __name__ == "__main__":
# 创建 400 个样本
N = 400
# 4 个类别
centers = 4
# 生成N个样本n_features个维度centers个簇中心的聚类模拟数据
# n_features = 2 ,即 x1 , x2 ,两个维度特征
data, y = ds.make_blobs(N, n_features=2, centers=centers, random_state=2)
# 生成样本数据方差为cluster_std(即数据分散程度)的聚类模拟数据,方差小的数据要密一些
data2, y2 = ds.make_blobs(N, n_features=2, centers=centers, cluster_std=(1, 2.5, 0.5, 2), random_state=2)
# 获取簇样本数量不一致的聚类模拟数据
data3 = np.vstack((data[y == 0][:], data[y == 1][:50], data[y == 2][:20], data[y == 3][:5]))
y3 = np.array([0] * 100 + [1] * 50 + [2] * 20 + [3] * 5)
# 获取簇中心即K为n_clusters初始化使用init的k-means对象
cls = KMeans(n_clusters=4, init='k-means++')
# 训练模型并获取预测值
y_hat = cls.fit_predict(data)
y2_hat = cls.fit_predict(data2)
y3_hat = cls.fit_predict(data3)
m = np.array(((1, 1), (1, 3)))
# 对矩阵进行旋转
data_r = data.dot(m)
y_r_hat = cls.fit_predict(data_r)
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
cm = matplotlib.colors.ListedColormap(list('rgbm'))
plt.figure(figsize=(9, 10), facecolor='w')
plt.subplot(421)
plt.title(u'原始数据')
# 绘制散点图
plt.scatter(data[:, 0], data[:, 1], c=y, s=30, cmap=cm, edgecolors='none')
x1_min, x2_min = np.min(data, axis=0)
x1_max, x2_max = np.max(data, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(422)
plt.title(u'KMeans++聚类')
plt.scatter(data[:, 0], data[:, 1], c=y_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(423)
plt.title(u'旋转后数据')
plt.scatter(data_r[:, 0], data_r[:, 1], c=y, s=30, cmap=cm, edgecolors='none')
x1_min, x2_min = np.min(data_r, axis=0)
x1_max, x2_max = np.max(data_r, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(424)
plt.title(u'旋转后KMeans++聚类')
plt.scatter(data_r[:, 0], data_r[:, 1], c=y_r_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(425)
plt.title(u'方差不相等数据')
plt.scatter(data2[:, 0], data2[:, 1], c=y2, s=30, cmap=cm, edgecolors='none')
x1_min, x2_min = np.min(data2, axis=0)
x1_max, x2_max = np.max(data2, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(426)
plt.title(u'方差不相等KMeans++聚类')
plt.scatter(data2[:, 0], data2[:, 1], c=y2_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(427)
plt.title(u'数量不相等数据')
plt.scatter(data3[:, 0], data3[:, 1], s=30, c=y3, cmap=cm, edgecolors='none')
x1_min, x2_min = np.min(data3, axis=0)
x1_max, x2_max = np.max(data3, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.subplot(428)
plt.title(u'数量不相等KMeans++聚类')
plt.scatter(data3[:, 0], data3[:, 1], c=y3_hat, s=30, cmap=cm, edgecolors='none')
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.tight_layout(2, rect=(0, 0, 1, 0.97))
plt.suptitle(u'数据分布对KMeans聚类的影响', fontsize=18)
# https://github.com/matplotlib/matplotlib/issues/829
# plt.subplots_adjust(top=0.92)
plt.show()
# plt.savefig('cluster_kmeans')

7、Canopy聚类算法:
簇中心点分布均匀、K值不需要指定、样本可以属于多个簇类和一次迭代,一般用于在K-Means算法之前获取先验知识即K的个数和簇中心分布位置
Canopy算法流程图:

Canopy算法首先选择两个距离阈值:T1和T2,其中T1 > T2
(1)原始状态下的数据还没有分类,所以从集合中取出一点P,将P作为第一个类,我们也将类称为Canopy。


(2)继续从集合中取点,比如P,计算P到已经产生的所有Canopy的距离,如果到某个Canopy的距离小于T1,则将P加入到该Canopy;如果P到所有Canopy中心的距离都大于T1,则将P作为一个新Canopy,如下图中的Q就是一个新的Canopy。
(3)如果P到该Canopy距离小于T2,则表示P和该Canopy已经足够近,此时将P从从集合中删除,避免重复加入到其他Canopy。

(4)对集合中的点继续执行上述操作直到集合为空,算法结束,聚类完成。
8、聚类算法评估指标:
Given Label:
同一性(Homogeneity):一个簇中只包含一个类别样本
完整性(Completeness):同类别样本归属到同一个簇中
同一性与完整性TradeOff互相制约,两者加权平均的评估指标V-Measure:
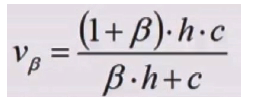
# !/usr/bin/python
# -*- coding:utf-8 -*-
from sklearn import metrics # 引入评估模块
"""
同一性(Homogeneity):一个簇中只包含一个类别样本
完整性(Completeness):同类别样本归属到同一个簇中
"""
if __name__ == "__main__":
y = [0, 0, 0, 1, 1, 1]
# y_hat 是聚类的结果,有 0,1,2 三个类别,三个类别里分别有两个点
y_hat = [0, 0, 1, 1, 2, 2]
h = metrics.homogeneity_score(y, y_hat) # 获取同一性评估指标
c = metrics.completeness_score(y, y_hat) #获取完整性评估指标
print(u'同一性(Homogeneity):', h)
print(u'完整性(Completeness):', c)
# 这是聚类算法的评估指标,此时参数β取1
# 同一性与完整性两者加权的评估指标V-Measure: Vβ = [(1+β)*h*c] / [β*h + c]
v2 = 2 * c * h / (c + h)
# v 直接从包里获取公式,结果与 v2 相同
v = metrics.v_measure_score(y, y_hat) # 获取V-Measure评估指标
print(u'V-Measure:', v2, v)
# 与上面的算法一致,y_hat与上面取值不同
# 允许不同值
y = [0, 0, 0, 1, 1, 1]
y_hat = [0, 0, 1, 3, 3, 3]
h = metrics.homogeneity_score(y, y_hat)
c = metrics.completeness_score(y, y_hat)
v = metrics.v_measure_score(y, y_hat)
print(u'同一性(Homogeneity):', h)
print(u'完整性(Completeness):', c)
print(u'V-Measure:', v)
# 与上面的算法一致,y_hat与上面取值不同
# 允许不同值
y = [0, 0, 0, 1, 1, 1]
y_hat = [1, 1, 1, 0, 0, 0]
h = metrics.homogeneity_score(y, y_hat)
c = metrics.completeness_score(y, y_hat)
v = metrics.v_measure_score(y, y_hat)
print(u'同一性(Homogeneity):', h)
print(u'完整性(Completeness):', c)
print(u'V-Measure:', v)
# 与上面的算法一致,y_hat与上面取值不同
y = [0, 0, 1, 1]
y_hat = [0, 1, 0, 1]
ari = metrics.adjusted_rand_score(y, y_hat)
print(ari)
y = [0, 0, 0, 1, 1, 1]
y_hat = [0, 0, 1, 1, 2, 2]
ari = metrics.adjusted_rand_score(y, y_hat)
print(ari)

9、轮廓系数:
度量样本与同簇其他样本的相似性:同簇中每个样本到同簇内其他样本的平均距离
度量样本与其他簇的不相似性:簇中每个样本到不同簇内所有样本的平均距离,与不同簇之间的最小平均距离
样本聚类合理Si接近1应该分到其他簇中Si接近-1在簇分界上Si接近0
10、层次聚类
(适用于有层级关系的数据样本):
分裂的层次聚类(DIANA):将原始数据集不断的迭代分裂,计算每个子数据集中的相似性,根据相似性继续迭代分裂,将数据集分裂成多个类别
凝聚的层次聚类(AGNES):将数据集的每个样本不断迭代向上聚类后按层聚类直到聚成一个数据集
11、密度聚类:
统计样本周边的密度,将密度给定一个阈值,不断的将样本添加到最近的簇中,可以进行对不规则数据样本的聚类即不类似圆形(适合K-Means算法)的数据,密度聚类计算复杂度大,可以通过索引来降低计算时间降低查找速度
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)密度聚类算法:
给定对象半径内的区域为对象领域,区域内样本个数超过阈值的对象为核心对象,核心对象到区域内的其他样本为核心密度可达,其他样本迭代规划对象半径区域,核心密度可达通过样本区域传递到其他样本为密度可达,一个样本密度可达的两个样本成为密度相连,最大密度相连构成的集合为簇,一个样本既不是核心对象也不能被别的样本密度可达为噪声。
DBSCAN密度聚类算法的步骤:

DBSCAN的主要优点有:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点有:
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
# !/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as ds
import matplotlib.colors
from sklearn.cluster import DBSCAN # 导入密度聚类模块
from sklearn.preprocessing import StandardScaler
def expand(a, b):
d = (b - a) * 0.1
return a-d, b+d
if __name__ == "__main__":
N = 1000 # N 为样本点的个数
centers = [[1, 2], [-1, -1], [1, -1], [-1, 1]] # centers 为 4 个中心点
# n_features=2 ,二维 x1 ,x2 ,cluster_std=[0.5, 0.25, 0.7, 0.5] 为 4 个正态分布的方差,random_state=0 给定数据输入的方式
data, y = ds.make_blobs(N, n_features=2, centers=centers, cluster_std=[0.5, 0.25, 0.7, 0.5], random_state=0)
data = StandardScaler().fit_transform(data) # StandardScaler() 做归一化(对数据进行相应的算法)用的
# 数据的参数:(epsilon, min_sample),设置超参数
params = ((0.2, 5), (0.2, 10), (0.2, 15), (0.3, 5), (0.3, 10), (0.3, 15))
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12, 8), facecolor='w')
plt.suptitle(u'DBSCAN聚类', fontsize=20)
for i in range(6): # 遍历超参数
eps, min_samples = params[i]
model = DBSCAN(eps=eps, min_samples=min_samples) # 获取DBSCAN聚类模型
model.fit(data)
y_hat = model.labels_
core_indices = np.zeros_like(y_hat, dtype=bool)
core_indices[model.core_sample_indices_] = True
y_unique = np.unique(y_hat)
n_clusters = y_unique.size - (1 if -1 in y_hat else 0)
print(y_unique, '聚类簇的个数为:', n_clusters)
plt.subplot(2, 3, i+1)
clrs = plt.cm.Spectral(np.linspace(0, 0.8, y_unique.size))
print(clrs)
for k, clr in zip(y_unique, clrs):
cur = (y_hat == k)
if k == -1:
plt.scatter(data[cur, 0], data[cur, 1], s=20, c='k')
continue
plt.scatter(data[cur, 0], data[cur, 1], s=30, c=clr, edgecolors='k')
plt.scatter(data[cur & core_indices][:, 0], data[cur & core_indices][:, 1], s=60, c=clr, marker='o', edgecolors='k')
x1_min, x2_min = np.min(data, axis=0)
x1_max, x2_max = np.max(data, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.title(u'epsilon = %.1f m = %d,聚类数目:%d' % (eps, min_samples, n_clusters), fontsize=16)
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()

12、谱和谱聚类:
谱:Y=A*X,矩阵X乘以A等于对矩阵X做了空间线性变换,那么Y=map(X),A是map这个线性算子,它的所有特征值的全体,称之为方阵的谱,方阵的谱半径为最大的特征值
谱聚类是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,以达到对样本数据进行聚类的目的
谱聚类解决区域重叠问题,密度聚类与K-Means聚类不适合对区域重叠的数据进行聚类
样本数据集可以构建成全连接图,并且两两样本之间可以求相似度,两两样本之间构建邻接矩阵来表示图,邻接矩阵W上面的值是用高斯相似度计算
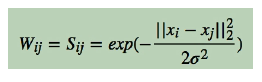
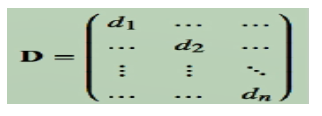
W矩阵按行或列加和得对角阵D
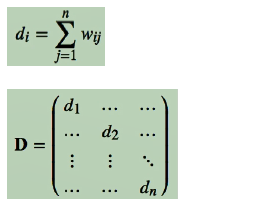
L=D-W,L矩阵为Laplace矩阵
向量v与变换A满足Av=λv,向量v是变换A的一个特征向量,λ是相应的特征值
L矩阵是N*N的,N是样本个数,实数形成的对数矩阵,求特征值和特征向量
所有特征向量根据排序默认从小到大,逆序之后获取特征向量最大的几个列向量实现降维,用这些列向量表示新的对应每个样本的重要特征,然后用K-Means聚类算法对样本进行聚类即Laplace矩阵做主成分分析PCA(主成分分析技术,又称主分量分析,利用降维的思想将多指标转化为少数几个综合指标)进行做K均值聚类
算法描述

import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors
from sklearn.cluster import spectral_clustering
from sklearn.metrics import euclidean_distances
def expand(a, b):
d = (b - a) * 0.1
return a-d, b+d
if __name__ == "__main__":
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
t = np.arange(0, 2*np.pi, 0.1)
data1 = np.vstack((np.cos(t), np.sin(t))).T
data2 = np.vstack((2*np.cos(t), 2*np.sin(t))).T
data3 = np.vstack((3*np.cos(t), 3*np.sin(t))).T
data = np.vstack((data1, data2, data3))
n_clusters = 3
m = euclidean_distances(data, squared=True)
sigma = np.median(m)
plt.figure(figsize=(12, 8), facecolor='w')
plt.suptitle(u'谱聚类', fontsize=20)
clrs = plt.cm.Spectral(np.linspace(0, 0.8, n_clusters))
for i, s in enumerate(np.logspace(-2, 0, 6)):
print(s)
af = np.exp(-m ** 2 / (s ** 2)) + 1e-6
y_hat = spectral_clustering(af, n_clusters=n_clusters, assign_labels='kmeans', random_state=1)
plt.subplot(2, 3, i+1)
for k, clr in enumerate(clrs):
cur = (y_hat == k)
plt.scatter(data[cur, 0], data[cur, 1], s=40, c=clr, edgecolors='k')
x1_min, x2_min = np.min(data, axis=0)
x1_max, x2_max = np.max(data, axis=0)
x1_min, x1_max = expand(x1_min, x1_max)
x2_min, x2_max = expand(x2_min, x2_max)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
plt.grid(True)
plt.title(u'sigma = %.2f' % s, fontsize=16)
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
