1.正则表达式
[0-9] 任意一个数字字符
[^0-9] 任意一个非数字,取非
^[0-9] 表示以数字开头
[a-z] 任意一个小写字母
[a-zA-Z] 任意一个字母,正则表达式中区分大小写
. 表示任意一个字符
* 表示匹配*号前面的字符任意次,包含0次
.* 表示任意个任意字符
\+ 表示匹配+号前面的字符1次或多次,至少1次

\? 表示匹配?号前面的字符0次或1次
{n} 表示其前面字符出现的次数
\{n,m\} 表示匹配其前面的字符至少n次,最多m次
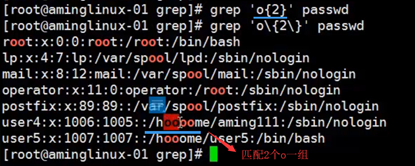
| 表示匹配|号左面或右面
2. grep/egrep命令
grep [-cinvABC] 'word' filename1 filename1…..
选项
-c count,统计匹配的行数
-n number,匹配的行显示在原文件中的行号
-v 取反,显示不匹配的行
-r 递归遍历子目录下的所有文件
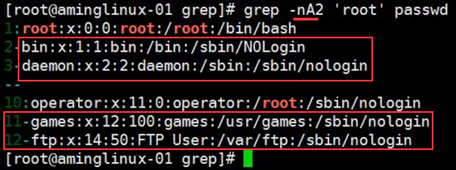
-A<n> 过滤显示出匹配行的上面的n行,不包括匹配行
-B<n> 过滤显示出匹配行的下面的n行,不包括匹配行
-C<n> context(上下文),过滤出匹配行的上面和下面n行,不包括匹配行
注意:grep -E 等价于 egrep
3. sed命令
1)选项
-n 取消默认输出,仅输出匹配的行
-r 类似grep的-E选项,特殊符号不需要脱义
-i sed命令处理文件,仅输出处理的结果,文件的内容不会更改保存;
-i选项,文件的内容会更改保存。
-e 多次处理匹配行
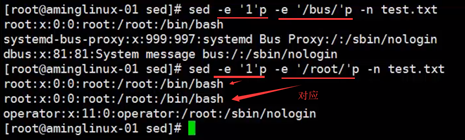
2)打印输出匹配行,类似grep,但匹配的关健字不带颜色显示
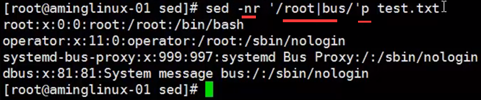
3)打印指定行
1)sed -n ‘2’p file 打印第2行
2)sed -n ‘2,5’p file 打印第2到第5行
sed -n ‘2,$’p file 打印第2到最后(尾)行
sed -n ‘1,$’p file 打印所有行
4)查找替换字符
针对字符

针对正则表达式

5)删除某些字符,即把某些字符替换成空

6)在行首新增字符

7)引用()内的内容;贪婪匹配
test.txt的内容,把第一个冒号前的内容和最后一个冒号后的内容调换
