一.NLG文本生成任务
文本生成NLG,不同于文本理解NLU(例如分词、词向量、分类、实体提取),是重在文本生成的另一种关键技术(常用的有翻译、摘要、同义句生成等)。
传统的文本生成NLG任务主要是抽取式的,生成式的方法看起来到现在使用也没有那么普遍。现在,我记录的是textrank,一种使用比较广泛的抽取式关键句提取算法。
二、TextRank前世今生
要说TextRank(TextRank: Bringing Order into Texts),还得从它的爸爸PageRank说起。
PageRank(The PageRank Citation Ranking: Bringing Order to the Web),是上世纪90年代末提出的一种计算网页权重的算法。当时,互联网技术突飞猛进,各种网页网站爆炸式增长,业界急需一种相对比较准确的网页重要性计算方法,是人们能够从海量互联网世界中找出自己需要的信息。
百度百科如是介绍他的思想:PageRank通过网络浩瀚的超链接关系来确定一个页面的等级。Google把从A页面到B页面的链接解释为A页面给B页面投票,Google根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票目标的等级来决定新的等级。简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
具体说来就是,PageRank有两个基本思想,也可以说是假设,即数量假设:一个网页被越多的其他页面链接,就越重);质量假设:一个网页越是被高质量的网页链接,就越重要。
总的来说就是一句话,从全局角度考虑,获取重要的信息。
三、TextRank原理
首先不得不说的是原始论文的PageRank的公式,d是阻力系数,取0.85;In(Vi)是链入Vi页面的网页集合, Out(Vj)是链出Vi页面的网页集合:
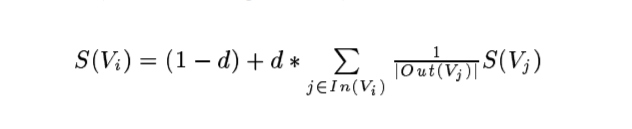
TextRank的公式是这样的,Wji表示两节点边的重要程度,入度和初度的意思同PageRank:
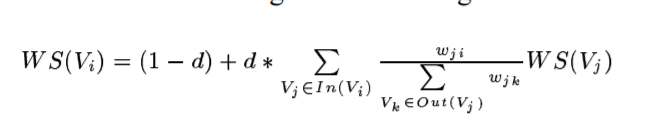
当然,虽然TextRank和PageRank的思想相近,但是它们还是有不同点的。一是边权重的构建不同,PageRank利用的是网页的连接关系,而TextRank利用的是词的共现信息(或者是两两句子的文本相似度);二是边关系的不同,PageRank是有向无权边,而TextRank的是无向有权边。
四、jieba,TextRank4ZH,gensim的TextRank实现比较(推荐TextRank4ZH)
1.jieba
defaultdict字典存储出入度,10 iters循环,只有关键词的textrank
2.TextRank4ZH
数据预处理为(不变-去停用词-或保留重要tag)句子的词共现构建numpy矩阵, networkx的pagerank作为textrank优化,使用了networkx和jieba外部包。支持关键词和关键句。
3.gensim
数据预处理比较多且针对英文(比如说关键词取3,这样中文较多的二字的词就取不到,不如TextRank4ZH的保留重要tag;再比如切句全是英文的分隔符.?!,不如TextRank4ZH的。?!......);相似度计算为BM25比词共现矩阵先进;gensim自己实现构建Graph、PageRank等不需要额外包;输入最小句子长度设置为10。
五、码源分析
主要参考jieba,TextRank4ZH,gensim,
Jieba的TextRank使用defaultdict字典存储句子的相邻词语之间的共现关系,代码如下:
g = UndirectWeightedGraph()
cm = defaultdict(int) # 这个字典, 不存在时候会返回空,而不像dict那样报错
words = tuple(self.tokenizer.cut(sentence))
for i, wp in enumerate(words): # textrank和pagerank一样,会有两个for循环
if self.pairfilter(wp):
for j in xrange(i + 1, i + self.span):
if j >= len(words):
break
if not self.pairfilter(words[j]):
continue
if allowPOS and withFlag:
cm[(wp, words[j])] += 1
else:
cm[(wp.word, words[j].word)] += 1 # 例如: dict[('我','喜欢')]=1
for terms, w in cm.items():
g.addEdge(terms[0], terms[1], w) # 保存(词1, 词1的下一个词[词2], 频次[词1词2的])
nodes_rank = g.rank()TextRank4ZH使用的是numpy保存共现句子间相邻词语的共现信息,然后再用了networkx.pagerank计算句子得分,据说这是优化,加快了计算速度等。代码如下:
,
sorted_sentences = []
_source = words
sentences_num = len(_source)
graph = np.zeros((sentences_num, sentences_num))
# 构建两两相似度矩阵
for x in xrange(sentences_num):
for y in xrange(x, sentences_num):
similarity = sim_func( _source[x], _source[y] )
graph[x, y] = similarity
graph[y, x] = similarity
nx_graph = nx.from_numpy_matrix(graph) # 调用pagerank实现
scores = nx.pagerank(nx_graph, **pagerank_config) # this is a dict
sorted_scores = sorted(scores.items(), key = lambda item: item[1], reverse=True)
# 切句
sentence_delimiters = ['?', '!', ';', '?', '!', '。', ';', '……', '…', '\n']
# 提取重要tag的中文词语
allow_speech_tags = ['an', 'i', 'j', 'l', 'n', 'nr', 'nrfg', 'ns', 'nt', 'nz', 't', 'v', 'vd', 'vn', 'eng']
gensim的textrank是gensim.summarization.summarizer.summarize。
##########先是分句和数据预处理(依次是: 小写, html, 标点符号, 多个空格, 数字时间等, 英文停用词,大于3的句子,提取英文单词词干[如复数])
###############################
DEFAULT_FILTERS = [
lambda x: x.lower(), strip_tags, strip_punctuation,
strip_multiple_whitespaces, strip_numeric,
remove_stopwords, strip_short, stem_text
]
# 1.切分句子, 非贪婪搜索, 以英文句号-感叹号-问号.!?加空格, 或者是换行符\n为标志,不适合中文
RE_SENTENCE = re.compile(r'(\S.+?[.!?])(?=\s+|$)|(\S.+?)(?=[\n]|$)', re.UNICODE)
# \w 的释义都是指包含大 小写字母数字和下划线
# \s 空格
# ^ 匹配字符串的开始
# $ 匹配字符串的结束
# 2.去除标点符号(punctuation),可以发现,有一些特殊字符和中文的
punctuation = """!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""
# 3.去除html标签
RE_TAGS = re.compile(r"<([^>]+)>", re.UNICODE)
# 4.空格,时间数字等, 时间等,例如"24.0hours"改为"24.0 hours"
# 5.大于len=3的单词, 感觉这点中文不适用,strip_short(s, minsize=2)比较合适
# 构建子典等
corpus = _build_corpus(sentences)
# 关键
most_important_docs = summarize_corpus(corpus, ratio=ratio if word_count is None else 1)
# page rank
def pagerank_weighted(graph, damping=0.85):
"""Get dictionary of `graph` nodes and its ranks.
Parameters
----------
graph : :class:`~gensim.summarization.graph.Graph`
Given graph.
damping : float
Damping parameter, optional
Returns
-------
dict
Nodes of `graph` as keys, its ranks as values.
"""
coeff_adjacency_matrix = build_adjacency_matrix(graph, coeff=damping)
probabilities = (1 - damping) / float(len(graph))
pagerank_matrix = coeff_adjacency_matrix.toarray()
# trying to minimize memory allocations
pagerank_matrix += probabilities
vec = principal_eigenvector(pagerank_matrix.T)
# Because pagerank_matrix is positive, vec is always real (i.e. not complex)
return process_results(graph, vec.real)
希望对你有所帮助!
