(1950年提出)人工智能是我们希望达成的目标,希望机器可以和人一样智能,而机器学习是实现人工智能的一种方式,而深度学习是机器学习中的一种方式,机器学习主要指的是基于机器学习中神经网络的各种模型。
下面介绍几种为了实现人工智能的方式:
hand-crafted rules人工智能:早期的人工智能,其本质就是通过许多if判断语句去实现,通俗的讲就是用大量的判断语句,如果接收到一些信号,就做出相应的指令。这样并不能完成比较复杂的任务,通过编写大量的if语句,没有真正的“智慧”,之前的早期人工智能,基本都是用这种技术,无法超越其创造者。
Machine learning :使机器有学习的能力,让其有云辨识的能力。即寻找出我们所需要的function。通俗的讲,我们希望机器拥有识别,学习的能力,可以理解为寻找一个模型,通过输入一些信号(样本),让机器去建立一个模型,得到结果。
比如:在图像识别中,我们先确定一大堆函数集(模型)提供给机器,并且提供给机器一大堆样本集(猫和狗的各种图片),告诉机器你看到什么样本(猫或者狗的图片)就要输出什么,看到猫的图片输出猫,看到狗的图片输出狗。最终让机器寻找模型,未来你给机器一个没有见过的样本(图片),它也可以识别出来。
Deep learning :机器学习的一个分支。

图1-1 人工智能与机器学习深度学习大致包含关系
在实际模型设计过程中,通过从函数集中选取合适的模型与训练集进行处理,得出模型的优劣,从而取得较为适应的模型,对该模型便可输入新的样本,得到输出。可以从下图进行理解,左边的部分称作学习器,学习器就是我们让机器寻找模型的过程,我们从很多很多函数集(模型)中通过让各种样本进行测试,得到很多不同函数的输出,然后通过这些输出去评价这个模型的优劣(这里的优劣指是否适合我们输入的数据,输出数据是否真的符合实际样本的数据,比如:输入了猫的图片,模型的输出是否是猫)。相比之下较优的模型拿出来可以用于实际。右边的部分是你可以作为应用的过程,即你可以用你的模型去使用,给它一个新的输入,它会给你一个新的输出。
在机器学习中,输入的样本通常会用于进行训练与测试,用于训练模型的叫训练集,用于测试模型优劣的叫测试集,样本的真实输入叫做样本的标签(比如一张猫的图片做样本,猫就是这个样本的标签)。
以上使用有标记的样本进行训练(即样本的输出是知道的,就是说输入是猫的图片,机器知道这张图片是猫),叫做有监督学习supervised learning。
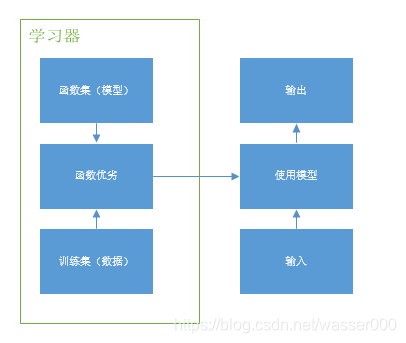
图1-2 机器学习大致框架
可以看下图,下图主要讲的是机器学习的一些不同的问题与包含。首先是回归,回归问题很好理解可以理解为给一组数(样本),寻找一个函数将这些样本的函数关系进行拟合,得到函数后可以进行一些预测或者分析,比如:已知某城市前几年的PM2.5的值,通过模型去预测未来几年的值。
分类问题指的是提供一组样本,进行分类,比如我们上文提到的识别猫或狗图片的问题,就是一个分类问题。分类问题包含了二分类问题(经常是判定是否问题,如提供很多邮件,去判定是否是垃圾邮件),还有多分类问题(如我们提供很多类别的新闻,将他们分类)。
分类问题中有很多模型,最简单的模型是线性模型。当然还包含了深度学习等很多模型。当然,分类问题不仅仅是做简单的分类,其实可以引申为很多问题,比如下棋。
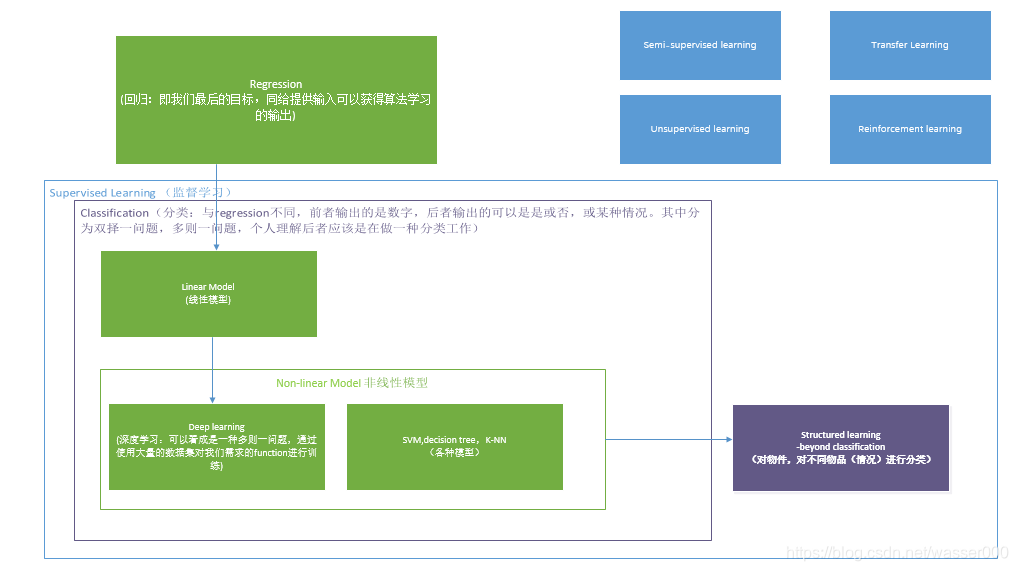
图1-3 机器学习整体框架
Semi-supervised learning:半监督学习,不进行标识的训练集对学习也会有帮助,提供的样本有一部分没有标记,同样会对模型训练有帮助。
Transfer Learning:迁移学习,提供了一些与问题不相干的样本,比如:猫狗图片识别中,样本中有一些不相干的训练集,比如一些风景照。这些不相干的样本对机器学习也有帮助。
Unsupervised learning:无监督学习,有大量样本,这些样本都没有标记。比如:把很多动物图片给机器,让机器创造一些新的动物图片。
Structured learning :结构化学习,让机器输入有结构性复杂的东西,比如在声音识别,输入语音信号,输出语音表达的含义;在文字翻译,输入文字,输出翻译文字;在人脸识别中,出入图片,输出识别出的人。
Reinforcement learning:强化学习,在决策中不会告诉机器好坏,只会告诉他评价的指标,即好坏或者评价分数。比如下围棋,不会告诉机器中间过程好坏,但是会告诉它最后胜负或者很多步后占的目数多少。
alpha go是使用监督学习与强化学习的结合。
上图中各种模型没有任何高下之分,只是不同情况下的适应。
这篇文章是我之前写的,后自己看发现可读性比较差,忽略了很多基比较弱或是没有接触的小伙伴,于是重新把全部文章重写一遍啦。虽然机器学习目前已经发展的很不错了,会用的人也非常的多,比我强的人也大有人在,但还是把这系列文章写完,也算是无愧于心了。
一些最初学习时的个人思考:在课程中提到的强化学习是给计算机做出的响应一个“好”或“坏”,来修正计算机之后的行为,为什么不能使用一个数值作为一个修正的条件呢?比如说我们期望最好的结果是0,在作出判决之后可以给计算机一个数(可正可负),对其进行修正,这样可以使用控制领域的一些理论(比如PID控制)来预测出模型的一些特性。同时,多种分支路线情况下,也可以给不同的值定义不同的含义,使有更多的选择,也可以做成多维的坐标进行更多维的求解。一点个人思考,天马行空,如果该想法已经实现或者实现很困难,暂且先赔个不是。
今天主要学习了李宏毅机器学习的第一节课,大概了解了机器学习的整个过程,使用训练集与函数库种的模型优劣分析筛选,得到较为合适的模型。同时,学到了机器学习种的大致分类,写了自己第一篇博客,很开心,希望自己可以更加努力学好机器学习,未来可以帮助更多的人。
