1 什么是 RabbitMQ ?
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。 — 来自百度百科
名词解释 – Erlang语言
Erlang 是一种面向并发运行环境的通用编程语言,具有以下特征:
- 大规模并发处理与分布式计算能力
- 用于开发高可靠性、高质量的电信产品
- 适用于复杂的项目
2 RabbitMQ 的基础概念
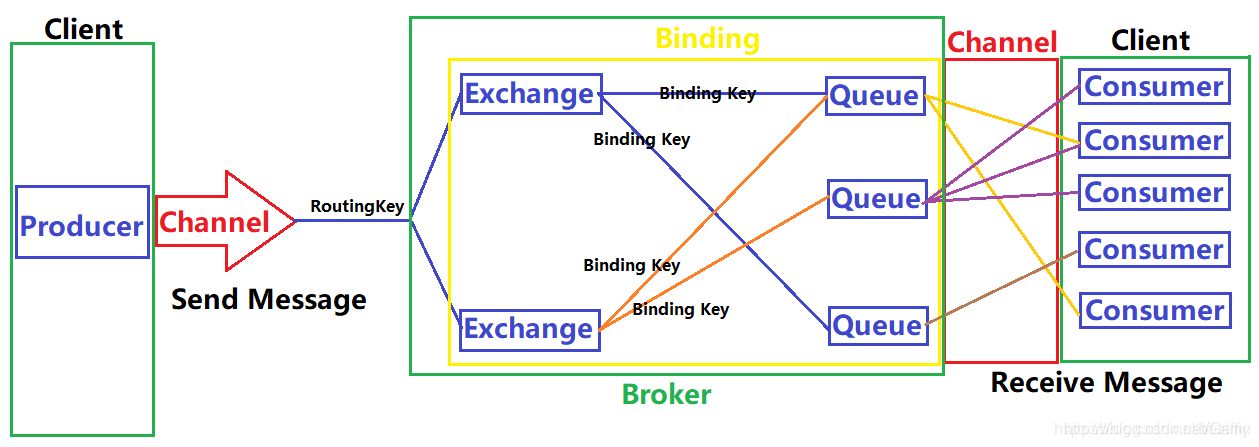
一般来说,我们提到消息队列的时候,生产者是与消息队列直接联系的,但 RabbitMQ 在此之上,多做了一层抽象,在生产者与消息队列之前插入了一个交换器(Exchange),从而实现了生产者与消息队列的解耦。
2.1 Producer 生产者
向消息队列发布消息的客户端应用程序。
2.2 Channel 信道
多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的 TCP 连接内的虚拟连接,复用 TCP 连接的通道。
2.3 Exchange 交换器
提供 Producer 到 Queue 之间的匹配,接收生产者发送的消息并将这些消息按照路由规则转发到消息队列。交换器用于转发消息,它不会存储消息 ,若没有 Queue 绑定到 Exchange 的话,它会直接丢弃掉 Producer 发送过来的消息。
2.4 Binding 绑定
Binding 用于建立 Exchange 和 Queue 之间的关联。
2.5 Queue 消息队列
保存消息,直到消息发送给消费者。注意一个消息可投入一个或多个队列。
2.6 Consumer 消费者
从消息队列取得消息的客户端应用程序。
2.7 Broker 服务器
RabbitMQ 服务器
3 消息调度策略
消息调度策略指的是在收到生产者发送的消息后,Exchange 根据什么规则将消息转发到队列中。
RabbitMQ 为我们提供了四种 Exchange,分别是 fanout,direct,topic,header,而 header 模式在实际使用中较少,在本博客中只会对前三种模式进行比较。
在介绍消息调度策略之前,我们先来个开胃菜,认识两个与消息调度策略有关的名词:Routing Key 与 Binding Key。
- Routing Key:路由键,用于标记消息的路由规则,决定了交换机的转发路径。
- Binding Key:绑定键,用于匹配 Routing Key,表示 Exchange 与 Queue 的绑定关系。
3.1 Fanout
Fanout 又被称为订阅/广播模式。该模式模式与 Binding Key 和 Routing Key 无关,Exchange 将接收到的消息分发给所有与该交换器绑定的消息队列。注意,Fanout 转发消息是最快的。
3.2 Direct
Direct 即是路由模式,也是 Exchange 的默认模式。唯有当 Routing Key 与 Binding Key 完全匹配的时候才将消息发送至消息队列。
事实上,RabbitMQ 默认提供了一个 Exchange,名字是空字符串,类型是 Direct,绑定到所有的Queue 上(每一个 Queue 和这个无名 Exchange 之间的 Binding Key 是 Queue 的名字)。所以,有时候我们感觉不需要 Exchange 也可以发送和接收消息,实际上是使用了 RabbitMQ 默认提供的 Exchange。
3.3 Topic
Topic 就是通配符模式。Routing Key 与 Binding Key 会根据正则表达式进行模糊匹配,若匹配成功则会将消息转发至消息队列。
4 消息确认机制(Message Acknowledgment)
我们现在假设一种情况,消费者刚刚收到消息队列发来的信息,却不幸宕机,导致了信息丢失,这该咋办呢?
其实,这种情况完全可以通过消费者在消费完消息后发送一个回执给 RabbitMQ 解决,这也被称为消息确认机制。RabbitMQ 在收到消费回执之后才将消息移除出消息队列,若没有收到信息回执并检测到消费者的 RabbitMQ 连接断开,那么 RabbitMQ 会将该消息发送给其他消费者进行处理。
需要注意的是,只要消费者的 RabbitMQ 连接没有断开,无论消费者处理消息时间有多长,都不会导致该消息被发送给其他消费者。
5 消息持久化(Message durability)
我们之前已经解释过了如何让消息在发送到消费者的处理过程中不丢失,但大家有没有想过一个问题,如果 rabbitMQ server 突然挂掉了,消息还是会丢失。。
为了让 RabbitMQ 服务重启也不会丢失消息,我们需要将 Queue 与 Message 都设置为可持久化的,这样可以保证绝大部分情况下消息不会丢失。
但是天有不测风云,还有另外一些特别的情况,比如 RabbitMQ 服务器已经接收到生产者的消息,但还没来得及持久化该消息,RabbitMQ 服务器就挂了。如果我们想要解决这种情况,就需要用到事务,这在我后面的博客将会介绍。
6 分发机制
一般来说,一个队列有多个消费者同时消费数据,此时有两种分发数据的方式,一种是轮询分发,另一种是公平分发,下面我们将分别介绍这两种分发机制。
6.1 轮询分发
轮询分发,Round-robin dispatching,也是 RabbitMQ 的默认消息分发机制。队列会给每一个消费者发送的数据数量是一模一样的,并不会因为两个消费者处理数据速度不同而发生改变。这样很容易导致部分消费者天天加班,而部分消费者无所事事的情况。
我们思考一下为什么会发生这种情况。当一个消息进入消息队列时,RabbitMQ 只负责将它分发到消费者那里,而不去检查这个消费者的 unacknowledged messages 的数量,只是简单地将第n个消息分发给第n(求余之后的n)个消费者那里就结束了。为了解决这个问题,我们其实可以换一种分发机制,没错,说的就是你,公平分发。
6.2 公平分发
公平分发,Fair dispatch,消费者设置每次从队列里只取一条数据,并且关闭自动回复机制,每次取完一条数据后,手动回复并继续取下一条数据。这样每个消费者都只有消费完一条消息才会收到下一条消息,十分的“公平”。
7 Prefetch count
在 Round-robin dispatching 模式下,消息队列的消息将会平摊给各个消费者,会出现有部分消费者很忙而部分消费者很闲的情况。这时我们可以通过设置 Prefetch count 来限制限制消息队列每次发送给每个消费者的消息数。举个栗子,当我们设置 Prefetch count = 1时,消息队列每次都会给消费者发送一条消息,当且仅当消费者消费完这条信息之后,消息队列才会给消费者发送下一条消息。
8 远程过程调用(RPC)
我们都知道,MQ 是基于异步的消息处理,生产者将消息发送到消息队列之后其实并不知道消费者是处理成功了还是失败了。但在实际中,我们可能也需要同步处理,需要同步等待服务端将消息处理完成后再进行下一步处理,这时就该 RPC 出场了。
那么 RabbitMQ 是如何实现 RPC 的呢?
首先,客户端在发送消息的时候会在消息的属性中设置两个值 replyTo 和 correlationId,随即服务端会收到消息并进行处理,在处理完成后,会生成一条应答消息到 replyTo 指定的 Queue,同时带上 correlationId。客户端之前已订阅 replyTo 指定的 Queue,从中收到服务器的应答消息后,根据其中的 correlationId 分析哪条请求被执行了,根据执行结果进行后续业务处理。
名词解释
- replyTo:一个 Queue 名称,用于告诉服务器处理完成后将通知我的消息发送到这个 Queue 中
- correlationId:此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个 id 了解哪条请求被成功执行了或执行失败
