数据准备1-写入txt
create_train_img_txt.sh
数据来源:github
#/usr/bin/env sh
DATA=/mnt/hgfs/E/data/mouth #数据目录,下面包含0,1两个文件夹,neutral or smile.60x60pixel
DATA_SAVE=. #创建文件保存目录
echo "Creating train.txt...."
rm -rf $DATA_SAVE/train.txt
find $DATA/0/*.jpg | cut -d '/' -f6- | sed "s/$/ 0/" >> $DATA_SAVE/train.txt
find $DATA/1/*.jpg | cut -d '/' -f6- | sed "s/$/ 1/" >> $DATA_SAVE/train.txt
echo "Done!"
find-将文件路径写入文件中
find /mnt/hgfs/E/data/mouth/0/*.jpg > 0.txt
find /mnt/hgfs/E/data/mouth/1 -name "*.jpg" > 1.txt
sed-逐行处理文件,"s/$/ 0/",s为搜索,在行后面追加空格+0cut-截取字节,字符,字块;-d为检查文件夹,/分隔标志,-fn-m分隔的索引
train.txt

数据准备2-写入lmdb
create_dataset_lmdb.sh
#!/usr/bin/env sh
# Create the mouth lmdb inputs
# N.B. set the path to the mouthtrain data dirs
set -e #抛出错误提示
CAFFE=/home/wl/software/caffe #caffe安装路径
EXAMPLE=. #lmdb文件保存路径
DATA=. #train.txt路径
TOOLS=$CAFFE/build/tools #一些caffe工具包路径,在caffe安装目录下
TRAIN_DATA_ROOT=/mnt/hgfs/E/data #图片根目录
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.
RESIZE=false
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_dataset_lmdb.sh to the path" \
"where the training data is stored."
exit 1
fi
echo "Creating train lmdb..."
rm -r mouth_train_lmdb
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT/ \
$DATA/train.txt \
$EXAMPLE/mouth_train_lmdb
echo "Creating val lmdb..."
-
$TRAIN_DATA_ROOT/后面有个/,不然路径拼接出错

编写训练网络
包括数据层,网络结构,loss层
train.prototxt
#train.prototxt
name "mouthNet"
#datalayer
layer{
name: "data"
type: "Data"
top: "data"
top: "label"
include{
phase: TRAIN
}
transform_param{
scale: 0.00390625
}
ata_param{
source: "mouth_train_lmdb"
batch_size: 1
backend: LMDB
}
}
#conv1
layer{
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param{
lr_mult: 1
decay_mult: 0
}
param{
lr_mult: 2
decay_mult: 0
}
convolution_param{
num_output: 20
kernel_size: 5
stride: 1
weight_filler{
type: "xavier"
}
bias_filler{
type: "constant"
}
}
}
#pool1
layer{
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param{
pool: MAX
kernel_size: 2
stride: 2
}
}
#conv2
layer{
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param{
lr_mult: 1
decay_mult: 0
}
param{
lr_mult: 2
decay_mult: 0
}
convolution_param{
num_output: 50
kernel_size: 5
stride: 1
weight_filler{
type: "xavier"
}
bias_filler{
type: "convolution_param"
}
}
}
#pool2
layer{
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param{
pool: MAX
kernel_size: 2
stride: 2
}
}
#ip1
layer{
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param{
lr_mult: 1
decay_mult: 0
}
param{
lr_mult: 2
decay_mult: 0
}
inner_product_param{
num_output: 500
weight_filler{
type: "xavier"
}
bias_filler{
type: "constant"
}
}
}
#relu1
layer{
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "relu1"
}
#ip2
layer{
name: "ip2"
type: "InnerProduct"
bottom: "relu1"
top: "ip2"
param{
lr_mult: 1
decay_mult: 0
}
param{
lr_mult: 2
decay_mult: 0
}
inner_product_param{
num_output:2
weight_filler{
type: "xavier"
}
bias_filler{
type: "constant"
}
}
}
#loss
layer{
name: "loss"
type: "SigmiodCrossEntroyLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
type: "Data", 数据层
includeTRAINorTEST,训练阶段加载还是测试阶段加载transform_para数据变换,scale表示数据缩放,0.00390625=1/255,表示归一化到0-1data_parasource数据集文件,batch_sizebatch size,bcekend指定数据db形式
type: "Conveolution"-卷积层
paramlr_mult:1decay_mult:0指定权重和偏置的学习率和权值衰减convolution_param指定num_outputkernel_sizestrideweight_fillerbias_filler
type: "Pooling"池化层
pooling_param指定pool池化类型,kernel_sizestride, 没有要学习的参数
type: "InnerProduct"-全连接层
w,b paramnum_output wight_filler bias_filler
type: "ReLU"-激活函数
- 没有参数学习和特殊操作
type: SigmiodCrossEntroyLoss-二分类的loss层
sigmoid函数后接交叉熵损失
编写训练
-solver.prototxt
# The train net protocol buffer definition
# this follows "ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION"
net: "train.prototxt"
# All parameters are from the cited paper above
base_lr: 0.001
momentum: 0.9
momentum2: 0.999
# since Adam dynamically changes the learning rate, we set the base learning
# rate to a fixed value
lr_policy: "fixed"
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 100
# snapshot intermediate results
snapshot: 50
snapshot_prefix: "mouth_"
# solver mode: CPU or GPU
type: "Adam"
solver_mode: CPU
训练
train.sh
#/usr/bin/env sh
echo "strating training......"
CAFFE=/home/wl/software
SOLVER=/home/wl/coding/hw
$CAFFE/caffe/build/tools/caffe train -solver=$SOLVER/solver.prototxt
echo "ending training......."
-
CAFFE=/home/wl/softwareSOLVER=/home/wl/coding/hw,赋值时=不能有空格,否则
train.sh: 5: train.sh: CAFFE: not found train.sh: 6: train.sh: SOLVER: not found train.sh: 8: train.sh: /caffe/build/tools/caffe: not found
ERROR1
F1107 22:11:16.345911 13254 data_transformer.cpp:465] Check failed: datum_channels > 0 (0 vs. 0)
*** Check failure stack trace: ***
@ 0x7f4324e585cd google::LogMessage::Fail()
@ 0x7f4324e5a433 google::LogMessage::SendToLog()
@ 0x7f4324e5815b google::LogMessage::Flush()
@ 0x7f4324e5ae1e google::LogMessageFatal::~LogMessageFatal()
@ 0x7f432550bcb7 caffe::DataTransformer<>::InferBlobShape()
@ 0x7f43254e8f1e caffe::DataLayer<>::DataLayerSetUp()
@ 0x7f432547bdd9 caffe::BaseDataLayer<>::LayerSetUp()
@ 0x7f432547c22f caffe::BasePrefetchingDataLayer<>::LayerSetUp()
@ 0x7f43253cd8ec caffe::Layer<>::SetUp()
@ 0x7f43253b8fda caffe::Net<>::Init()
@ 0x7f43253b7a30 caffe::Net<>::Net()
@ 0x7f432551473d caffe::Solver<>::InitTrainNet()
@ 0x7f4325513f6d caffe::Solver<>::Init()
@ 0x7f4325513a8d caffe::Solver<>::Solver()
@ 0x7f4325426d64 caffe::SGDSolver<>::SGDSolver()
@ 0x7f432542d51e caffe::AdamSolver<>::AdamSolver()
@ 0x7f432542e3c1 caffe::Creator_AdamSolver<>()
@ 0x423ec1 caffe::SolverRegistry<>::CreateSolver()
@ 0x41f6c9 train()
@ 0x421b1f main
@ 0x7f4323dc8830 __libc_start_main
@ 0x41e649 _start
@ (nil) (unknown)
Aborted (core dumped)
搜索这里
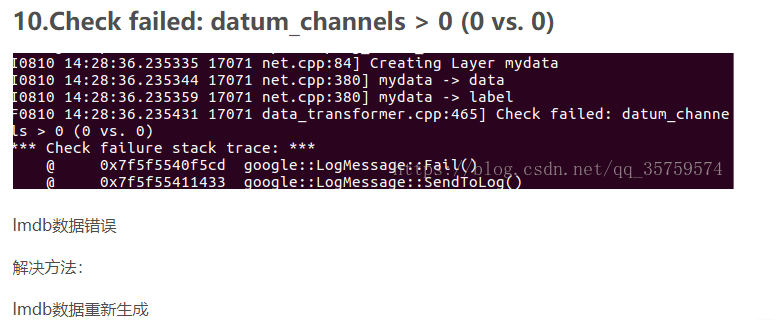
OK!
ERROR2
F1107 22:43:10.218010 13542 sigmoid_cross_entropy_loss_layer.cpp:41] Check failed: bottom[0]->count() == bottom[1]->count() (2 vs. 1) SIGMOID_CROSS_ENTROPY_LOSS layer inputs must have the same count.
我的网络最后一层输出确实是num_output: 2, 我以为这样可以…, 改为1,OK!
但时loss层type: "SoftmaxWithLoss",即可以运行
至此第一个caffe程序完成!
测试/验证
train.prototxt->train_val.prototxt
前面加上
#val data
layer{
name: "data"
type: "Data"
top: "data"
top: "label"
include{
phase: TEST
}
transform_param{
scale: 0.00390625
}
data_param{
sorce: "mouth_test_lmdb"
batch_size: 1
backend: LMDB
}
}
后面加上
#acc
layer{
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include{
phase: TEST
}
}
solver.prototxt->train_val_solver.prototxt
加上
#test
# covering the full testing images.
test_iter: 100
# Carry out testing every 50 training iterations.
test_interval: 50
执行train_val.sh训练&验证
ERROR1
Check failed: label_value < num_labels (1 vs. 1)
都说和标签是否从0开始有关,我猜应该和我最后输出num_output: 1有关,改为softmax试试…OK!
ERROR2
Check failed: datum_width == width (61 vs. 60)
数据集像素可能不是那么一致…
修改create_dataset_ladb.sh
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=60
RESIZE_WIDTH=60
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
OK!
inference
sudo apt install python-pip
pip install numpy
总是出错。。。
虚拟机太卡了,换win10写代码吧。
