1.监督学习
在这个系列里面我们主要针对的是监督学习。
我们不会关注无监督学习。
1.1 具体定义
什么是监督学习呢?假设我有一批数据,我们给这批数据贴上了正向标签,然后你再拿这批去训练出一个模型,这个模型能够完成一些操作,比如分类,比如回归的这个过程就叫做监督学习。
所以监督学习需要完成的两个任务是
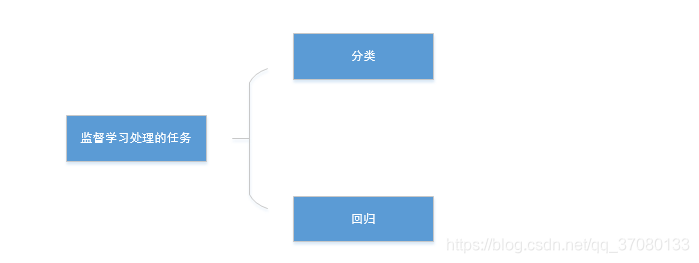
它的特征是:
给的训练集要拥有明确的正向标签,所谓的正向标签就是,这个样本是正确的!
1.1.1 什么是回归
所谓回归就是我们希望得到一个函数h(x),使得 以某个x作为输入时,得到的这个y值是一个合理的y值。
怎么定义它的合理呢?就是预先会有一堆数据给你,比如这样的
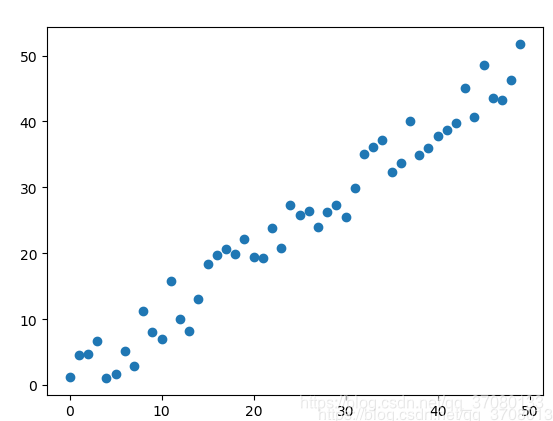
其中横轴是输入,纵轴是输出,我现在做一个假设,我们在下面圆叉的地方是我们的这个测试输入
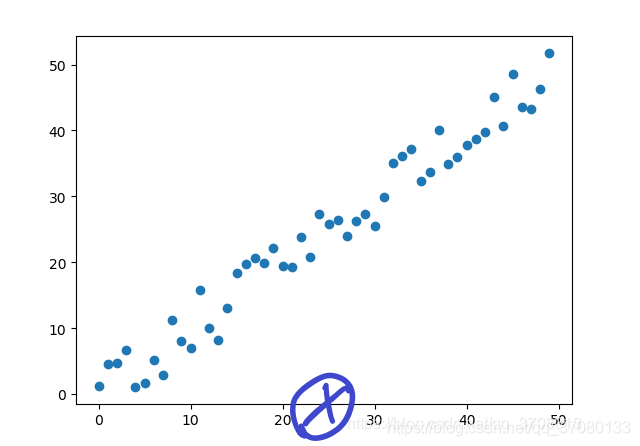
然后我们会生成5个点,你看哪个点合理?
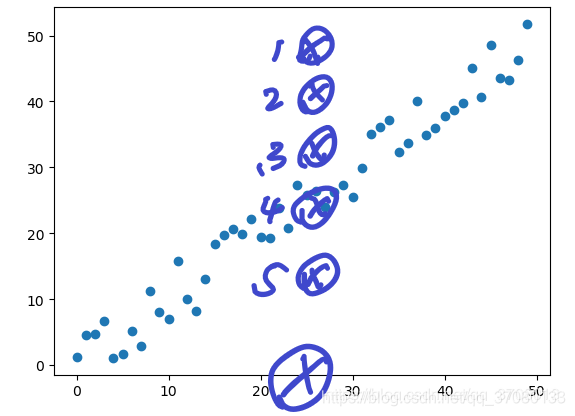
肯定是第四个点啦!
所以回归问题就是:能够拟合出一个函数h(x)使得h(x) = point_4.y
拟合...注意,拟合!!!!!!!!!!!!!!!!!!!!!!
1.1.2 什么是分类?
这个要解释?
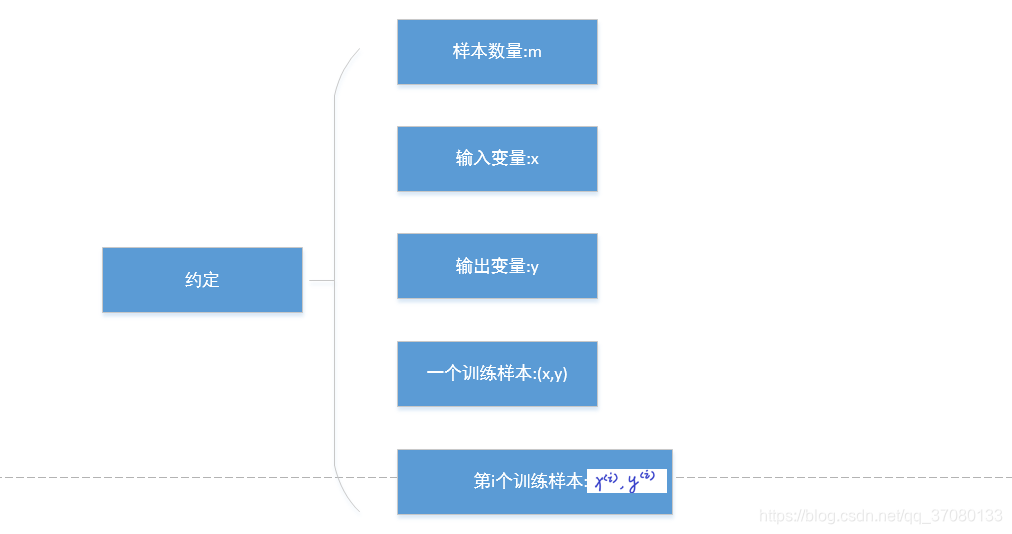
1.2 一些重要的约定
我们会定义一些字符用于在这个系列表述一些比较重要的东西
1.3 一个简单的训练过程
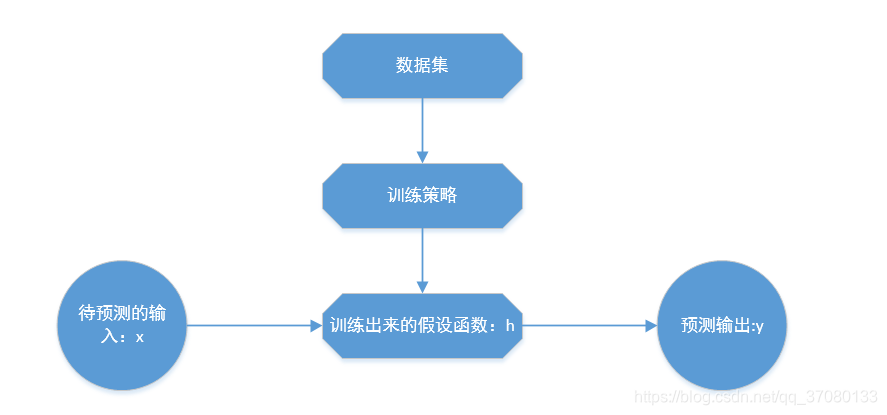
1.4 一个简单的训练案例
房市的售价预测模型
我们给定了一批训练集,里面包含房子的一个特征,房子面积x和房子的售价y
(x,y),这一批数据集有50个,并且是通过线性表示的
这是通过python生成出来的一批样本。
1.4.1 数据准备
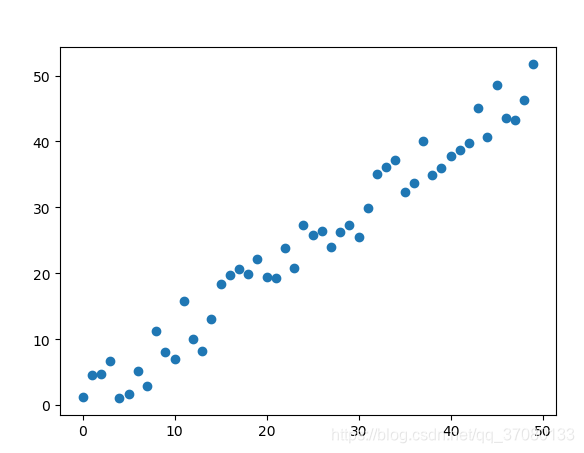
原始数据如下:使用json存储
[{"area": 0, "value": 1.1584905546564361},{"area": 1, "value": 4.540991715689879},{"area": 2, "value": 4.754697283011618},{"area": 3, "value": 6.660210295567435},{"area": 4, "value": 1.0904391950422854},{"area": 5, "value": 1.6154300683826914},{"area": 6, "value": 5.227357915040728},{"area": 7, "value": 2.872373150927947},{"area": 8, "value": 11.156881338921341},{"area": 9, "value": 7.985328833754833},{"area": 10, "value": 6.9943387823118215},{"area": 11, "value": 15.738835984473123},{"area": 12, "value": 10.02478446243436},{"area": 13, "value": 8.140167681857683},{"area": 14, "value": 13.083543333386551},{"area": 15, "value": 18.41149439612761},{"area": 16, "value": 19.66321023280224},{"area": 17, "value": 20.609052914757697},{"area": 18, "value": 19.83136583396592},{"area": 19, "value": 22.171694419225982},{"area": 20, "value": 19.438280864145565},{"area": 21, "value": 19.230005694712773},{"area": 22, "value": 23.797405550886452},{"area": 23, "value": 20.765385774284486},{"area": 24, "value": 27.275973513489397},{"area": 25, "value": 25.777818760769513},{"area": 26, "value": 26.432014434758873},{"area": 27, "value": 23.985110688243616},{"area": 28, "value": 26.18903808991948},{"area": 29, "value": 27.338362064940924},{"area": 30, "value": 25.563782905759453},{"area": 31, "value": 29.88715038217415},{"area": 32, "value": 34.99156284964707},{"area": 33, "value": 36.17777531370665},{"area": 34, "value": 37.141267302833874},{"area": 35, "value": 32.24752271912516},{"area": 36, "value": 33.65991853958367},{"area": 37, "value": 40.05867524793477},{"area": 38, "value": 34.97291410076436},{"area": 39, "value": 36.01552453174358},{"area": 40, "value": 37.78603885361476},{"area": 41, "value": 38.622061036237604},{"area": 42, "value": 39.79376527852082},{"area": 43, "value": 45.10961534551415},{"area": 44, "value": 40.68768969961324},{"area": 45, "value": 48.572856074599486},{"area": 46, "value": 43.53630224569426},{"area": 47, "value": 43.31289552681677},{"area": 48, "value": 46.29502242111438},{"area": 49, "value": 51.74805322964467}]生成的代码一并给你们了
import numpy as np
import matplotlib.pyplot as plt
import json
import os
def funcLine(x):
return x*10+np.random();
randomArray= np.random.random(size=50) - 0.5
randomArray= randomArray*10
funcArray = []
funcArray_xLabel = []
writeContent = "["
for i in range(50):
funcArray.append(i+randomArray[i])
funcArray_xLabel.append(i)
dict1 = {"area": i, "value": i+randomArray[i]}
v1 = json.dumps(dict1)
writeContent = writeContent+v1+","
pass
writeContent = writeContent[:writeContent.__len__()-1]+']'
funcArray = np.array(funcArray)
plt.figure(0)
# plt.plot(funcArray)
plt.scatter(funcArray_xLabel,funcArray,marker='o')
print(funcArray)
print(writeContent)
file1 = open('data1.txt','w')
file1.write(writeContent)
file1.close()1.4.2 假设函数h
回顾1.3的过程,我们发现,学习的最终目的就是要获得这个假设函数。
这个问题,是一个回归的问题
我们为啥把他看成一个回归问题而不是分类问题呢?
因为我们最终希望得到的是一个连续的结果,也就是我们的输出结果是一条连续的线
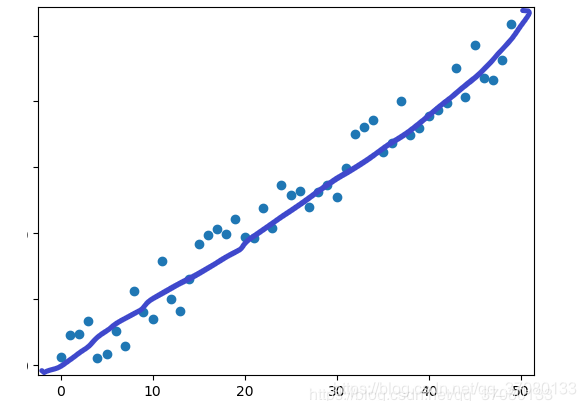
而不是0,1两种类别,所以这是一个回归问题
现在我们来求这个假设函数

从图上,我们可以看到这是一个典型的线性回归问题,所以,寻求这个
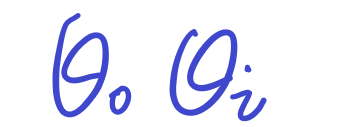
就是我们的目标.
那么,我们怎么评价我们找到的这俩值是合理的呢?
这里我们直接使用了简单的欧式距离作为代价函数
1.4.3 代价函数
在1.1.1里面我们提到了这个图
凭啥我们觉得4点比较合理?
这是因为我们认为这个点离这一系列的数据的这种趋势的距离最短。所以我们使用距离去描述
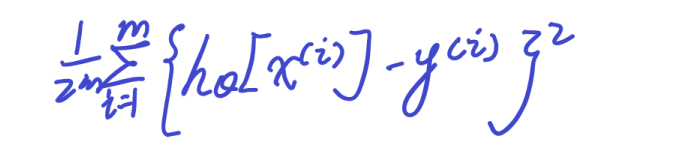
我们希望这个函数的值最小,那么怎么使得这个函数值最小呢,那就通过调整th_0和th_i

这个函数就叫做代价函数,我们描述为:
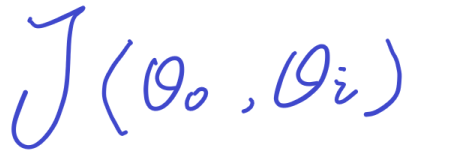
其表达式为:
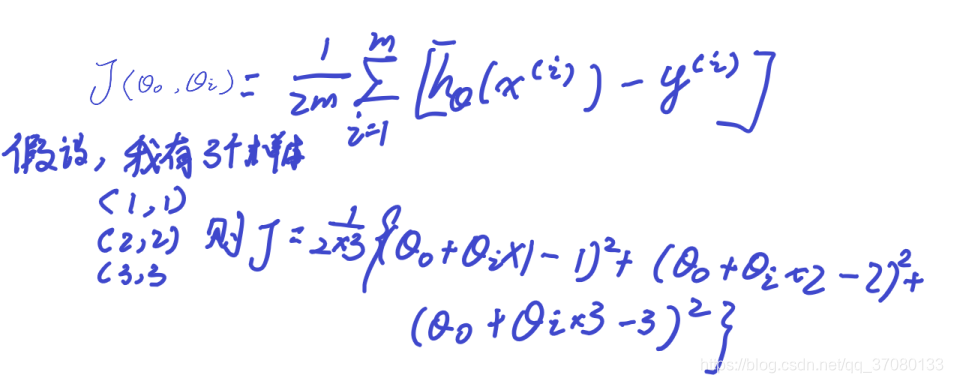
在下一章,我们将会详细介绍这个代价函数
本系列是吴恩达的学习笔记,so~~~我只是记录者,建议你们去看他的视频哟~~
