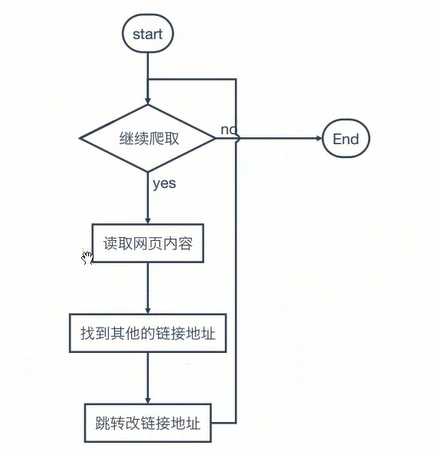
1.爬虫流程图
2.简单爬虫整个网页的内容
--python2
import urllib2 response = urllib2.urlopen("http://www.baidu.com") html = response.read() print(html)
3.中文乱码处理
# coding:utf-8 import re # import requests import sys import codecs #python2 import urllib2 #设置编码 reload(sys) sys.setdefaultencoding('utf-8') #获得系统编码格式 type = sys.getfilesystemencoding() # response = urllib2.urlopen("http://www.baidu.com") req=urllib2.Request("http://www.baidu.com") response=urllib2.urlopen(req) html = response.read().decode('utf-8').encode(type) print(html)
4. 伪装请求【伪装成浏览器】User-Agent头
# coding:utf-8 import sys import urllib2 # 设置编码 reload(sys) sys.setdefaultencoding('utf-8') # 获得系统编码格式 type = sys.getfilesystemencoding() url = "http://www.baidu.com" user_agent = "Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;" headers={ 'User-Agent':user_agent } req=urllib2.Request(url,headers=headers) response = urllib2.urlopen(req) html=response.read().decode("utf-8").encode(type) print(html)
5. 解析网页内容
5.1 正则 import re
创建正则表达式对象:pattern = re.comple(' \d+\.\d+ ', re.S)
默认匹配没一行
re.S 整个文档
import re pattern = re.compile("\d+\.\d+") s1="1.234 dsa frwr 4235.324 432423" rs = pattern.findall(s1) print(rs)
r"dsa\dsf\sd" 将转义字符当做普通字符处理
5.2 DOM解析