python中文件操作的小知识: 如何打印一个文件同时输出行号
方法:枚举enumerate
fp = open('test.txt','r',encoding='utf-8')
print(fp)
#如何输出行号
for i,c in enumerate(fp,1): ## 接收两个参数,第一个为遍历内容,第二个为起始行号,默认为0
print(i,c)

文章目录
一、常见的反爬措施以及应对措施
爬虫与反爬虫的斗争一直都存在着,双方时刻都可能上演一番大战。下面是一些我总结的反爬虫与爬虫应对措施
反爬虫与反爬策略:
1. 通过Headers反爬虫
(1)通过user-agent客户端标识来判断是否是爬虫
- 简介:一般通过是否有user-agent(客户端版本信息)可以轻易判断是不是爬虫
- 解决的办法:封装请求头添加use-agent。
(2)防盗链
- 简介:防盗链主要是针对客户端请求过程中所携带的一些关键信息来验证请求的合法性,而防盗链又有很多种,比如Referer防盗链、时间戳防盗链等等,这里讲的是Referer防盗链。Referer用于告知服务器该请求是从哪个页面链接过来的。
- 解决办法:封装请求头headers添加Referer字段以及相应的值。
2. 通过访问频率来判断
-
简介:对于一些网站来说,如果某个IP在单位时间里的访问频率过高,会限制访问
-
解决的办法:设置爬取间隔(涉及到等待)
- (1)最蠢的强制等待time.sleep
a = random.randint(5) time.sleep(a) - (2)隐式等待(等待你规定的时间,如10秒)
driver.implicitly_wait(10) - (3)显示等待(设置等待间隔)
wait = WebDriverWait( driver,#浏览器驱动对象 10,最大等待时长 0.5,扫描间隔 )
- (1)最蠢的强制等待time.sleep
3. 封ip
- 简介:如果某个IP在单位时间里的访问次数超过了某个阈值,那么服务器就会ban掉这个IP。
- 解决办法:使用代理IP。网上有很多免费代理和付费代理可供选择,免费代理比如:西刺代理、快代理等等,付费代理比如:代理云、阿布云等等。除此之外,我们还可以建一个属于自己的代理池以供使用
4. 在html中动手脚
- 简介:比如JS加密啊JS混淆啊,真是搞得人头大。不过我们这里先说那些在html中动手脚的,比如加一些无意义的字符之类的,这样即使我们能爬下来,得到的数据也是没法使用的。
- 案例:

- 解决办法:使用lxml解析,解析完之后再对数据做一下清洗(个人认为lxml还是比较好用的)
4. 页面内容无法直接获取数据,页面都是js代码动态页面反爬虫(ajax)
- 简介:页面只有无用的头部和尾部信息,具体信息都被放在js中了
- 案例:

- 解决办法:selenium+phantomjs可以获取页面数据
5. 蜜罐技术
-
简介:蜜罐这个词,最早是来自于网络攻防中。一方会故意设置一个或者几个服务器,故意留下漏洞,让另一方轻易的入侵进来。这些被故意设置的服务器,就叫做蜜罐。里面可能安装了监控软件,用来监控入侵者。同时,蜜罐还可以拖延入侵者的时间。在反爬虫的机制中,也有一种蜜罐技术。网页上会故意留下一些人类看不到或者绝对不会点击的链接。由于爬虫会从源代码中获取内容,所以爬虫可能会访问这样的链接。这个时候,只要网站发现了有IP访问这个链接,立刻永久封禁该IP + User-Agent + Mac地址等等可以用于识别访问者身份的所有信息。这个时候,访问者即便是把IP换了,也没有办法访问这个网站了。给爬虫造成了非常大的访问障碍。
-
解决办法:定向爬虫的爬行轨迹是由我们来决定的,爬虫会访问哪些网址我们都是知道的。因此即使网站有蜜罐,定向爬虫也不一定会中招。
6. 随机化网页源码
- 简介:用display:none来随机化网页源码,有网站还会随机类和id的名字,然后再加点随机的tr和td,这样的话就增大了我们解析的难度。比如全网代理IP:
- 案例:

- 解决办法:可以看到每个IP都是包含在一个class为“ip”的td里的,所以我们可以先定位到这个td,然后进行下一步解析。虽然这个td里面包含了很多的span标签和p标签,而且也每个标签的位置也没有什么规律,不过还是有办法解析的。方法就是把这个td里的所有文字提取出来,然后把那些前后重复的部分去除掉,最后拼接到一起就可以了
生动的总结图:
二、动态Html页面的处理方法
1. 常见的一些页面技术
(1)js(JavaScript)
html使我们页面的骨架,css是页面装饰,js是页面的灵魂。
JavaScript 是网络上最常用也是支持者最多的客户端脚本语言。它可以收集 用户的跟踪数据,不需要重载页面直接提交表单,在页面嵌入多媒体文件,甚至运行网页游戏。
我们可以在网页源代码的标签里看到。
比如:
<script type="text/javascript" src="http://statics.huxiu.com/w/mini/static_2015/js/sea.js?v=201601150944" ></script>
豆瓣就是这样的例子:
(2)jquery
jquery是一个js库,可以是js代码更加简化。
jQuery 是一个十分常见的库,70% 最流行的网站(约 200 万)和约 30% 的其他网站(约 2 亿)都在使用。一个网站使用 jQuery 的特征,就是源代码里包含了 jQuery 入口。
比如:
<script type="text/javascript" src="http://statics.huxiu.com/w/mini/static_2015/js/jquery-1.11.1.min.js?V =201512181512"></script>
注意:如果你在一个网站上看到了 jQuery,那么采集这个网站数据的时候要格外小心。jQuery 可 以动态地创建 HTML 内容,只有在 JavaScript 代码执行之后才会显示。如果你用传统的方法采集页面内容,就只能获得 JavaScript 代码执行之前页面上的内容。
(3)ajax:web页面的异步请求
我们与网站服务器通信的唯一方式,就是发出 http 请求获取新页面。如果提交表单之后,或从服务器获取信息之后,网站的页面不需要重新刷新,那么你访问的网站就在用Ajax 技术。
Ajax 其实并不是一门语言,而是用来完成网络任务(可以认为 它与网络数据采集差不多)的一系列技术。Ajax 全称是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML),网站不需要使用单独的页面请求就可以和网络服务器进行交互 (收发信息)。
(4)DHTML
和Ajax 一样,动态 HTML(Dynamic HTML, DHTML)也是一系列用于解决网络问题的 技术集合。
DHTML 是用客户端语言改变页面的 HTML 元素(HTML、CSS,或者二者皆 被改变)。比如页面上的按钮只有当用户移动鼠标之后才出现,背景色可能每次点击都会改变,或者用一个 Ajax 请求触发页面加载一段新内容,网页是否属于DHTML,关键要看有没有用 JavaScript 控制 HTML 和 CSS 元素。
2. 遇到动态页面的处理方法
用 Python 解决这个问题只有两种途径:
- 1、直接从 JavaScript 代码里采集内容(费时费力)
- 2、用 Python 的 第三方库运行 JavaScript,直接采集你在浏览器里看到的页面(这个可以有)。
下面就会介绍这种技术
三、selenium的介绍及安装
1. Selenium简介
-
定义:Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
-
作用:Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
-
注意:Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
2. Selenium的安装
两种安装方式:
- 第一种:可以从 PyPI 网站下载 Selenium库http://pypi.python.org/simple/selenium
- 第二种:使用第三方管理器 pip用命令安装:
pip install selenium==2.48.0
这里使用pip安装
Selenium 官方参考文档:http://selenium-python.readthedocs.io/index.html
四、PhantomJS 的简介及安装
1. PhantomJS简介
- 定义: PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
- 作用: 如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、cookie、headers,以及任何我们真实用户需要做的事情。
PhantomJS 官方参考文档:http://phantomjs.org/documentation
2. PhantomJS的安装
- 注意:PhantomJS 只能从它的官方网站http://phantomjs.org/download.html) 下载。
- 原因: 因为 PhantomJS 是一个功能完善(虽然无界面)的浏览器而非一个 Python 库,所以它不需要像 Python 的其他库一样安装,但我们可以通过Selenium调用PhantomJS来直接使用。
(1)无界面phantomjs镜像
安装步骤:
- 百度搜索phantomjs镜像
- 选取安装包

- 下载解压

- 配置环境变量(两种方法)
- 第一种:我们安装过anaconda,放在anaconda的scripts目录下(因为scripts目录为加载所有第三方库的)
- 步骤:
- ① 第一步: 取出其bin目录下的phantomjs.exe

- ② 第二步: 放在anaconda/scripts下

- ③第三步: 此时就可以通过selenium调用phantomjs
- ① 第一步: 取出其bin目录下的phantomjs.exe
- 步骤:
- 第二种:配置环境变量
-
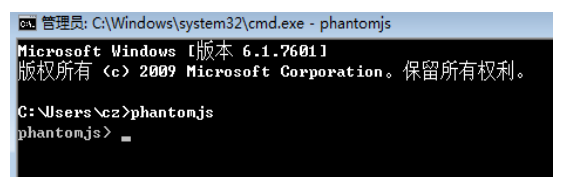
① 第一步: 下载–解压,然后,设置环境变量:C:\Users\cz\Downloads\phantomjs-2.1.1-windows\bin
-
② 第二步: 打开终端命令行,输入:phantomjs,能够进行到phantomjs命令行,则表示安装成功
-
- 第一种:我们安装过anaconda,放在anaconda的scripts目录下(因为scripts目录为加载所有第三方库的)
推荐使用第一种配置环境变量方式
(2)可以选择安装有界面的镜像
有界面和无界面的区别就是运行效率问题
下面以安装有界面 chromedriver镜像 为例;你可以选择任何浏览器的镜像
安装步骤:
- 百度搜索chromedriver镜像,版本号要选最接近的


- 解压后同样放在anaconda/scripts下

总结:到这里我们的selenium和PhantomJS就安装好了,我们可以使用他们来获取动态数据
