1.Hadoop背景介绍
1.1 Hadoop是什么
1.HADOOP是apache旗下的一套开源软件平台
2.HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3.HADOOP的核心组件:
HDFS - 分布式文件系统
YARN - 运算资源调度系统
MAPREDUCE - 分布式运算编程框架
4.广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
1.2 Hadoop产生背景
1.HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,
但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2.2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,
到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.3 Hadoop与大数据、云计算的关系
1.云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合
发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能
力提供给终端用户。
2.现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”。
3.而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.4 Hadoop应用案例
a)HADOOP应用于数据服务基础平台建设
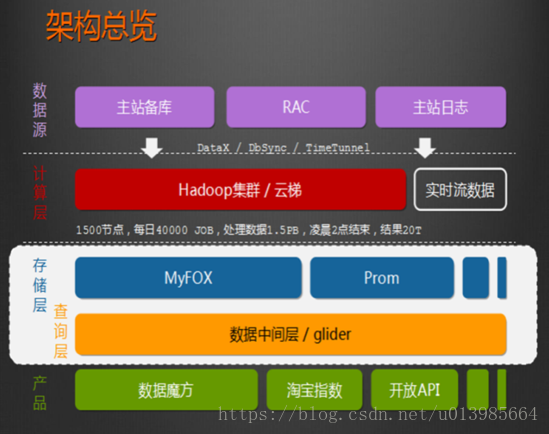
b)HADOOP用于用户画像

c)HADOOP用于网站点击流日志数据挖掘
1.5 HADOOP生态圈以及各组成部分的简介
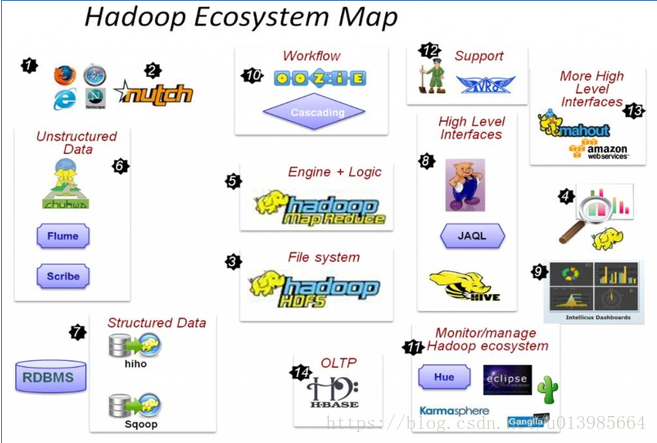
各组件简介
重点组件:
HADOOP(hdfs、MAPREDUCE、yarn):元老级大数据处理技术框架,擅长离线数据分析
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
Hbase:基于HADOOP的分布式海量数据库,离线分析和在线业务通吃
Hive:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具,使用方便,功能丰富,基于MR延迟大
Sqoop:数据导入导出工具
Flume:数据采集框架
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
2.分布式系统概述
由于大数据技术领域的各类技术框架基本上都是分布式系统,因此,理解hadoop、storm、spark等技术框架,都需要具备基本的分布式系统概念
2.1 分布式软件系统(Distributed Software Systems)
该软件系统会划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的
整体功能
比如分布式操作系统、分布式程序设计语言及其编译(解释)系统、分布式文件系统和分布式数据库系统等
2.2 分布式软件系统举例 - solrcloud
a) 一个solrcloud集群通常有多台solr服务器
b) 每一个solr服务器节点负责存储整个索引库的若干个shard(数据分片)
c) 每一个shard又有多台服务器存放若干个副本互为主备用
d) 索引的建立和查询会在整个集群的各个节点上并发执行
e) solrcloud集群作为整体对外服务,而其内部细节可对客户端透明
总结:利用多个节点共同协作完成一项或多项具体业务功能的系统就是分布式系统
2.3 分布式应用系统模拟开发
需求:可以实现由主节点将运算任务发往从节点,并将各从节点上的任务启动
程序清单:
AppMaster
AppSlave/APPSlaveThread
Task
程序运行逻辑流程:
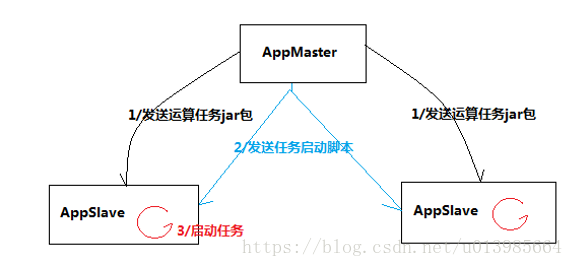
3.离线数据分析流程介绍
以下主要感受数据分析系统的宏观概念及处理流程,初步理解hadoop等框架在其中的应用环节
一个应用广泛的数据分析系统 - web日志数据挖掘
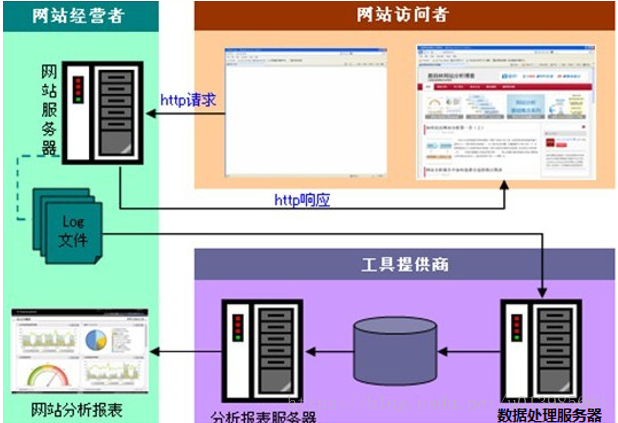
3.1 案例名称
网站点击流日志数据挖掘系统
3.2 需求描述
Web点击流日志包含着网站运营很重要的信息,通过日志分析,可以统计网站的访问量,哪个网页访问人数最多,哪个网页
最有价值,广告转化率、访客的来源信息,访客的终端信息等
3.3 数据来源
本案例的数据主要由用户的点击行为记录生成
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求
到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件
与下相似:
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/
1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20
100101 Firefox/23.0" 一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量
比如某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午10:00-12:00和下午15:00-18:00
访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索占整个网站的80%
PC用户不足1%的用户会消费,移动用户有5%会消费。
对于日志的这种规模的数据,用HADOOP进行日志分析最适合不过
3.4 数据处理流程
3.4.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:
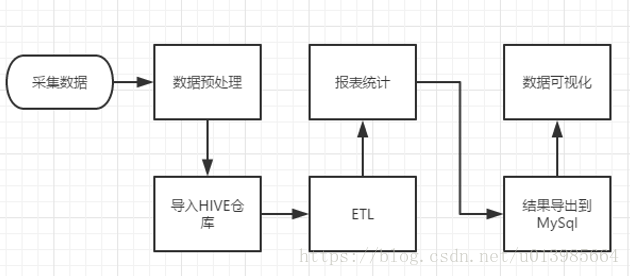
由于本案例的前提是处理海量数据,所以流程中各环节所使用的技术则跟传统BI完全不同:
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
3.4.2 项目技术架构图
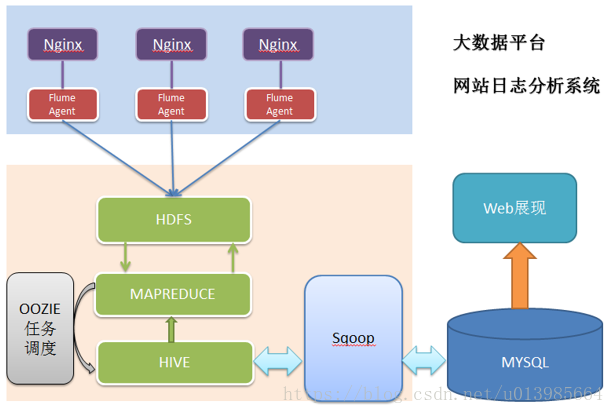
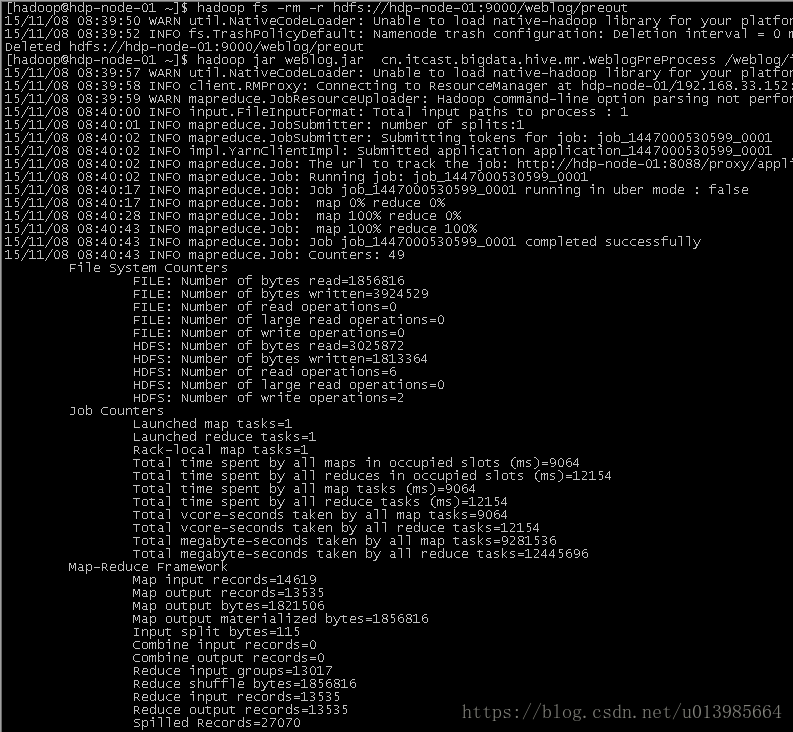
3.4.3 项目相关过程展示
a) Mapreudce程序运行
b) 在Hive中查询数据
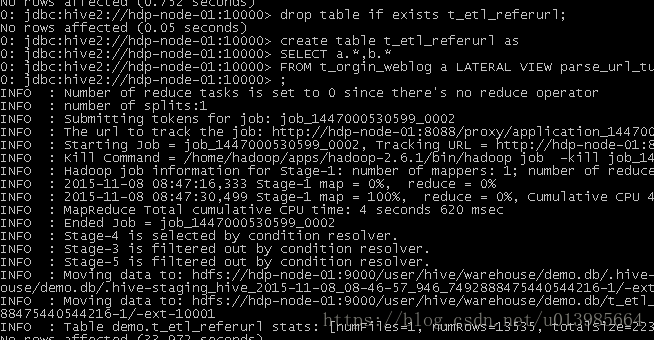
c) 将统计结果导入mysql
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root
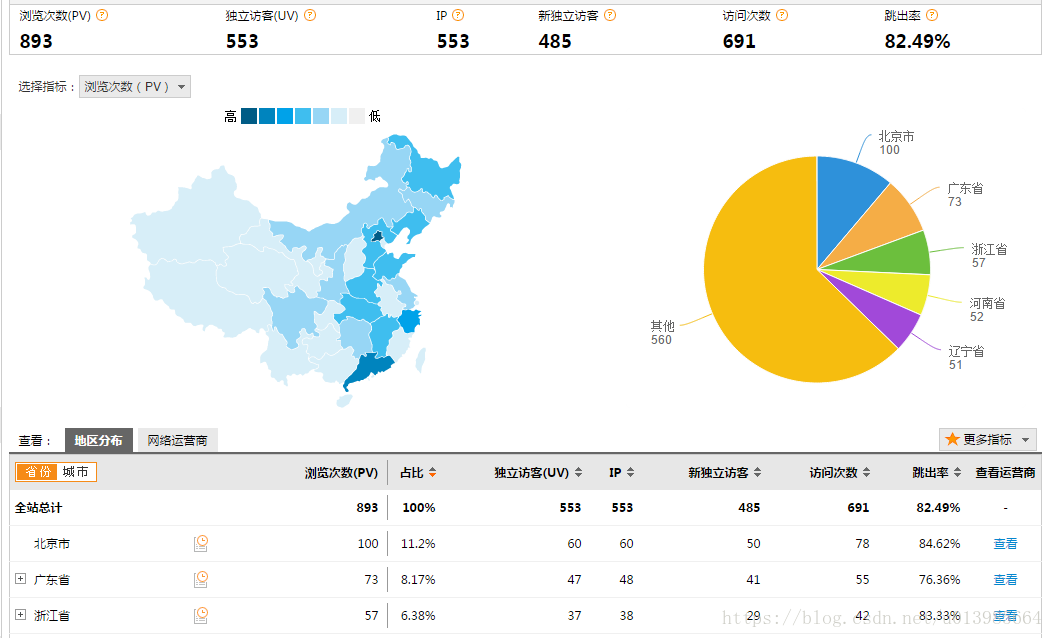
--table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 3.4.4 项目效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式
展现出来,本案例采用web程序来实现数据可视化
ps:本文中部分内容引用网友分享,目的用于分享技术,尊重原作者版权所有。