朴素贝叶斯
文章目录
一、介绍
-
朴素:独立性假设
-
处理文本分类的
-
非结构化数据(文本和图片都是非结构数据,不成体系,无行无列,要处理成有行有列有特征的)
1.1 文本分类的应用
自然语言处理,垃圾游戏分类,垃圾短信分类,敏感话题过滤,舆情分析
可以处理的信息有:文字 语言 数字 传播信息稀疏矩阵
词向量统计模型例子:
| 你好 | 吃了吗 | 坦克 |
|---|---|---|
| 1 | 1 | 0 |
词云的例子
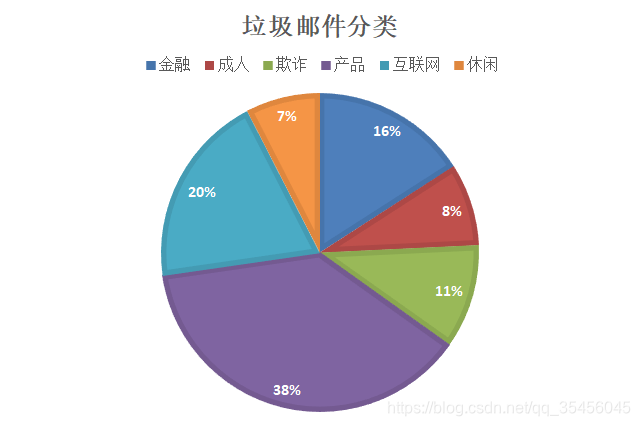
垃圾邮件分类
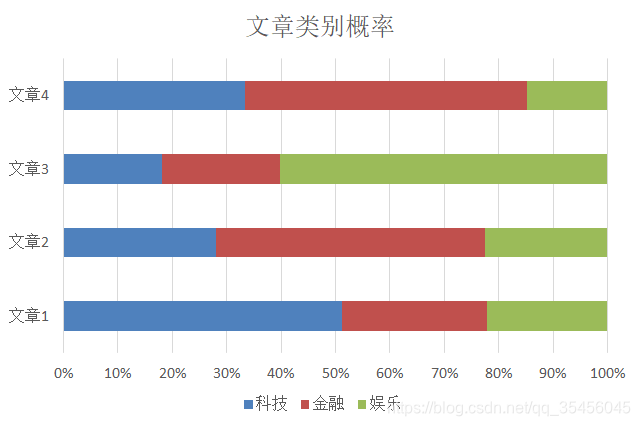
文章类别的概率
二、概率基础
概率定义为一件事情发生的可能性
- 扔出一个硬币,结果头像朝上
- 某天是晴天
2.1 概率例题
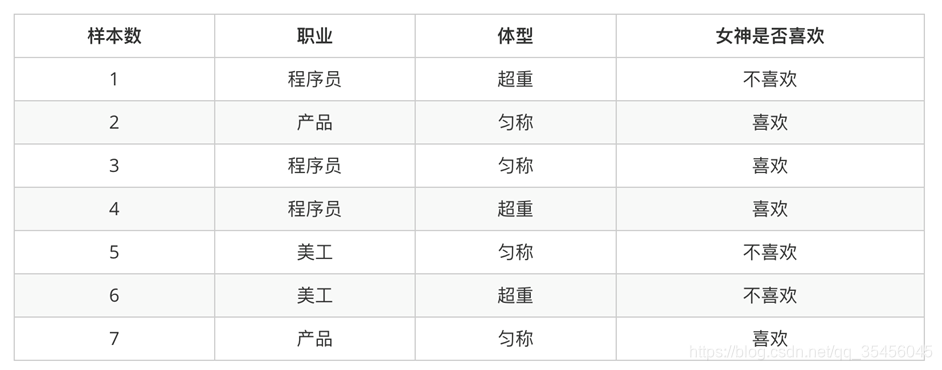
问题
1、女神喜欢的概率?4/7
2、职业是程序员并且体型匀称的概率?3/7*4/7=12/49
3、在女神喜欢的条件下,职业是程序员的概率?1/2
4、在女神喜欢的条件下,职业是产品,体重是超重的概率?0
2.2 联合概率和条件概率


2.3 朴素贝叶斯-贝叶斯公式
朴素贝叶斯的朴素:特征独立

公式分为三个部分:
P(C): 每个文档类别的概率(某文档类别词数/总文档词数)
P(W|C): 给定类别下特征 (被预测文档中出现的词)的概率
计算方法: P(F1|C)= Ni/N ( 训练文档中去计算)
Ni为该F1词在C类别所有文档中出现的次数
N为所属类别C下的文档所有词出现的次数和
P(F1,F2,..)预测文档中 每个词的概率
-
pw是一样的,可以忽略,只比较分子
2.4 概率统计词频
训练集统计结果(指定统计词频):
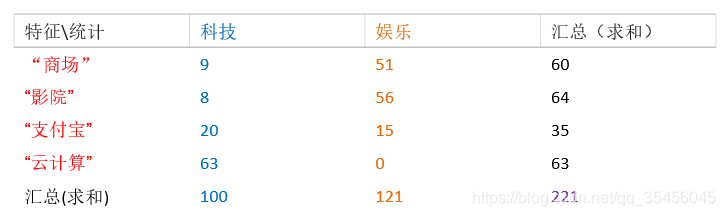
现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的类别概率?
根据公式pc是每个文档类别的概率用词数来求而不是篇数!!!

预测文档的情况:

注意
pc如果是按篇数就是错了

思考:属于某个类别为0,合适吗?
2.5 拉普拉斯平滑
问题:从上面的例子我们得到娱乐概率为0,这是不合理的,如果词频列表里面有很多出现次数都为0,很可能计算结果都为零。
解决方法:
拉普拉斯平滑系数

a为指定的系数一般为1 ,m为训练文档中统计出的特征调个数
所以这个地方的前三个乘数的
分子要加1
分母加上1*词的类别数

三、sklearn朴素贝叶斯实现API
sklearn.naive_bayes.MultinomialNB(alpha=1.0)
#alpha是拉普拉斯平滑系数
四、朴素贝叶斯分类的优缺点
- 优点:
– 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
– 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
– 分类准确度高,速度快. - 缺点:
– 需要知道先验概率P(F1,F2…|C),因此在某些时候会由于假设的先验
模型的原因导致预测效果不佳。
五、文本特征工程
import numpy as np
import pandas as pd
#记录中国的所有词语、成语(这个方法是吴军提出来的)
import jieba as jb #pip install jieba -i https://pypi.douban.com/simple
#尝试jieba
jb.lcut("你好,我是汪雯琦")
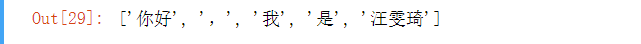
5.1 文本分割,单词提取
(1)英文
text = ['Life is happy,i am vicky','i like study study study']
# 文本的分割与处理
bow_text = []
#有多少个就循环多少次
for t in text:
#过滤符号
t = t.replace(',',' ').replace('.',' ').split(' ')
new_t = []
for word in t:
#保留非空字符
if len(word)>0:
new_t.append(word)
bow_text.append(new_t)
bow_text

(2)中文
#中文
text = ["人生苦短,我用python","vicky为自己代言"]
for i in range(len(text)):
text[i] = ' '.join(jb.lcut(text[i]))
text

# 文本的分割与处理
bow_text = []
#有多少个就循环多少次
for t in text:
#过滤符号
t = t.replace(',',' ').replace('.',' ').split(' ')
new_t = []
for word in t:
#保留非空字符
if len(word)>0:
new_t.append(word.lower())#英文都变成小写
bow_text.append(new_t)
bow_text

5.2 词数统计
#构建一个词库,变成特征
wordSets = []
for list_ in bow_text:
wordSets += list_
wordSets = set(wordSets)
wordSets
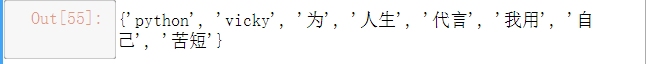
#列表里面嵌套字典,字典可以转变为DataFrame比较方便
wordDicts = []
for list_ in bow_text:
wordDict = dict.fromkeys(wordSets,0)#字典中的key来源于集合的意思,初始化为0次
for word in list_:
wordDict[word] += 1
wordDicts.append(wordDict)
pd.DataFrame(wordDicts)
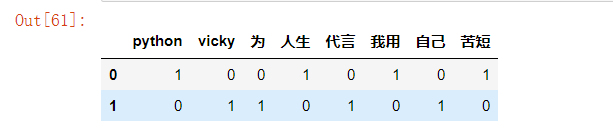
词数统计已经让我们的文本分类了
5.3 TFIDF(重要程度分析)
特征词语相对于当前文本的重要程度
TF(词频) IDF(逆文档频率)(包含某一个词语的文档数量比例)
IDF = log10(文档的总数 +1 / 包含某一个词语的文档数量 +1)
5.4 TF
tfDicts = []
for i in range(len(wordDicts)):
tfidf = dict()
#计算每个文本的单词量
nbowcount = len(bow_text[i])
for k,v in wordDicts[i].items():
tfidf[k] = v/nbowcount
tfDicts.append(tfidf)
pd.DataFrame(tfDicts)

5.5 IDF
idfDict = dict.fromkeys(wordSets,0)
N = len(text)
#包含某一个词语的文档数量
for wordDict in wordDicts:
for word,count in wordDict.items():
if count > 0:
idfDict[word] += 1
idfDict_ = dict()
#公式合并
for word,inv in idfDict.items():
idfDict_[word] = np.log10((N+1)/(inv+1))
idfDict_
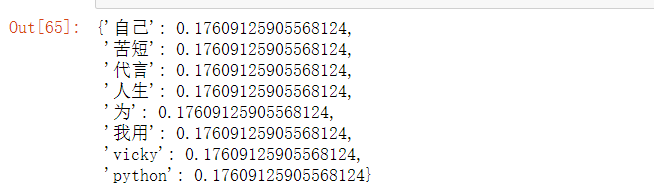
5.6 TFIDF合并
tfidfs = []
for tf in tfDicts:
tfidf = dict()
for word,tfval in tf.items():
tfidf[word] = tfval * idfDict_[word]
tfidfs.append(tfidf)
pd.DataFrame(tfidfs)

