关注公众号 MageByte,设置星标获取最新干货。公众号后台回复 “加群” 进入技术交流群获更多技术成长。
前面我们说了算法的重要性数据结构与算法开篇,今天我们就开始学习如何分析、统计算法的执行效率和资源消耗呢?请看本文一一道来。

数据结构和算法本生解决的就是「快」和「省」的问题,那就是如何让代码跑得快,还能节省存储空间。打造一台法拉利,不仅跑得快还省油,拥有好的算法与数据结构,程序跑得快,还省内存并且长时间运行也不会出故障,就像跑车长时间运行车子也不会出现异常「车震」,同时还快。所以赶紧上车,一起学习数据结构与算法,赶紧上车「稳稳」的学会如何检测跑车到底快不快,省油不省油。
这里就要用到我们今天要讲的内容:时间、空间复杂度分析。只要讲到数据结构与算法,就一定离不开时间、空间复杂度分析。复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本上就掌握了一半。这就就像内功心法,上乘武功还需搭配牛逼心法。
只有学会了检测标准才能在设计的时候心中按照标准来编写打造我们的「法拉利」代码。
为何需要复杂度分析
可能会有些疑惑,我把代码跑一遍,通过统计、监控,就能得到算法执行的时间和占用的内存大小。为什么还要做时间、空间复杂度分析呢?这种分析方法能比我实实在在跑一遍得到的数据更准确吗?
这种属于非要自己去尝试,没有根据合理方法预测我们要的就是像算命大师一样预先知道。很多数据结构和算法书籍还给这种方法起了一个名字,叫事后统计法。但是,这种统计方法有非常大的局限性。
1. 测试结果非常依赖测试环境
测试环境中硬件的不同会对测试结果有很大的影响。比如,我们拿同样一段代码,分别用 Intel Core i7 处理器和 Intel Core i3 处理器来运行,不用说,i7 处理器要比 i3 处理器执行的速度快很多。
就好像同一辆车放在深圳北环大道与我家农村小山沟跑是不一样的。
2.测试结果受数据规模的影响很大
后面我们会讲排序算法,我们先拿它举个例子。对同一个排序算法,待排序数据的有序度不一样,排序的执行时间就会有很大的差别。
极端情况下,如果数据已经是有序的,那排序算法不需要做任何操作,执行时间就会非常短。除此之外,如果测试数据规模太小,测试结果可能无法真实地反应算法的性能。
比如,对于小规模的数据排序,插入排序可能反倒会比快速排序要快!
所以,我们需要一个不用具体的测试数据来测试,就可以粗略地估计算法的执行效率的方法。这就是我们今天要讲的时间、空间复杂度分析方法。
大 O 复杂度表示法
算法的执行效率,粗略地讲,就是算法代码执行的时间。但是,如何在不运行代码的情况下,用“肉眼”得到一段代码的执行时间呢?就像检测车子马力与油耗似的。
求 1,2,3…n 的累加和。现在,一起估算一下这段代码的执行时间。
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}从 CPU 的角度来看,这段代码的每一行都执行着类似的操作:读数据-运算-写数据。尽管每行代码对应的 CPU 执行的个数、执行的时间都不一样,但是,我们这里只是粗略估计,所以可以假设每行代码执行的时间都一样,为 unit_time单位时间。
在这个假设的基础之上,这段代码的总执行时间是多少呢?
第 2、3 行代码分别需要 1 个 unit_time 的执行时间,第 4、5 行都运行了 n 遍,所以需要 2n*unit_time 的执行时间,所以这段代码总的执行时间就是 (2n+2)*unit_time。可以看出来,所有代码的执行时间 T(n) 与每行代码的执行次数成正比。
我们继续分析下面这段代码
int cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}我们依旧假设每个语句的执行时间是 unit_time。那这段代码的总执行时间 T(n) 是多少呢?
第 2、3、4 行代码,每行都需要 1 个 unit_time 的执行时间,第 5、6 行代码循环执行了 n 遍,需要 2n * unit_time 的执行时间,第 7、8 行代码循环执行了 n^2^遍,所以需要 2n^2^ * unit_time 的执行时间。所以,整段代码总的执行时间 T(n) = (2n^2^+ 2n + 3)*unit_time。
尽管我们不知道 unit_time 的具体值,但是通过这两段代码执行时间的推导过程,我们可以得到一个非常重要的规律,那就是,==所有代码的执行时间 T(n) 与每行代码的执行次数 n 成正比==。
我们可以把这个规律总结成一个公式。注意,大 O 就要登场了!
$T(n) = O(f(n))$
其中,$$T(n)$$ 我们已经讲过了,它表示代码执行的时间;n 表示数据规模的大小;$$f(n)$$ 表示每行代码执行的次数总和。因为这是一个公式,所以用$f(n)$ 来表示。公式中的 O,表示代码的执行时间 T(n) 与 f(n) 表达式成正比。
所以,第一个例子中的 $T(n) = O(2n+2)$,第二个例子中的 T(n) = O(2n^2^+2n+3)。这就是大 O 时间复杂度表示法。
大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。敲黑板了,表达的是变化趋势,并不是真正的执行时间。
当 n 很大时,你可以把它想象成 100000、1000000。而公式中的==低阶、常量、系数==三部分并不左右增长趋势,所以都可以忽略。我们只需要记录一个最大量级就可以了,如果用大 O 表示法表示刚讲的那两段代码的时间复杂度,就可以记为:$$T(n) = O(n)$$; $$T(n) = O(n^2)$$。
时间复杂度分析
前面介绍了大 O 时间复杂度的由来和表示方法。现在我们来看下,如何分析一段代码的时间复杂度?有三个比较实用的方法可以分享。
1. 只关注循环执行次数最多的一段代码
大 O 这种复杂度表示方法只是表示一种变化趋势。我们通常会忽略掉公式中的常量、低阶、系数,只需要记录一个最大阶的量级就可以了。所以,我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了。擒贼先擒王就是这么回事。
这段核心代码执行次数的 n 的量级,就是整段要分析代码的时间复杂度。
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}其中第 2、3 行代码都是常量级的执行时间,与 n 的大小无关,所以对于复杂度并没有影响。
循环执行次数最多的是第 4、5 行代码,所以这块代码要重点分析。前面我们也讲过,这两行代码被执行了 n 次,所以总的时间复杂度就是 O(n)。
2. 加法法则:总复杂度等于量级最大的那段代码的复杂度
看如下代码可以先试着分析一下,然后再往下看跟我的分析思路是否一样。
int cal(int n) {
int sum_1 = 0;
int p = 1;
for (; p < 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}这个代码分为三部分,分别是求 sum_1、sum_2、sum_3。我们可以分别分析每一部分的时间复杂度,然后把它们放到一块儿,再取一个量级最大的作为整段代码的复杂度。
- 第一段的时间复杂度是多少呢?这段代码循环执行了 100 次,所以是一个常量的执行时间,跟 n 的规模无关。
- 这里我要再强调一下,即便这段代码循环 10000 次、100000 次,只要是一个已知的数,跟 n 无关,照样也是常量级的执行时间。当 n 无限大的时候,就可以忽略。尽管对代码的执行时间会有很大影响,但是回到时间复杂度的概念来说,它表示的是一个算法执行效率与数据规模增长的变化趋势,所以不管常量的执行时间多大,我们都可以忽略掉。因为它本身对增长趋势并没有影响。
- 那第二段代码和第三段代码的时间复杂度是多少呢?答案是 O(n) 和 O(n^2^),你应该能容易就分析出来,我就不啰嗦了。
综合这三段代码的时间复杂度,我们取其中最大的量级。所以,整段代码的时间复杂度就为 O(n^2^)。也就是说:总的时间复杂度就等于量级最大的那段代码的时间复杂度。那我们将这个规律抽象成公式就是:
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n)))3. 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
刚刚说了一个加法原则,这里说的乘法原则,以此类推,你也应该能「猜到」公式。这个是效率最差的
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)T2(n)=O(f(n))O(g(n))=O(f(n)*g(n)).
也就是说,假设 T1(n) = O(n),T2(n) = O(n2),则 $$T1(n) * T2(n) = O(n^3)$$。落实到具体的代码上,我们可以把乘法法则看成是嵌套循环
int cal(int n) {
int ret = 0;
int i = 1;
for(x=1; i <= n; x++){
for(i = 1; i <= n; i++) {
j = i;
j++;
}
}
}
我们单独看 cal() 函数。假设 5-8行的 只是一个普通的操作,那第 4 行的时间复杂度就是,T1(n) = O(n)。但 5-8 函数本身不是一个简单的操作,它的时间复杂度是 T2(n) = O(n),所以,整个 cal() 函数的时间复杂度就是,$$T(n) = T1(n) * T2(n) = O(n*n) = O(n^2)$$。
几种常见时间复杂度实例
虽然代码千差万别,但是常见的复杂度量级并不多。老弟稍微总结了一下,这些复杂度量级几乎涵盖了今后可以接触的所有代码的复杂度量级。
划重点了同学们。
- 常量阶 $O(1)$
- 对数阶 $O(logn)$
- 线性阶 $O(n)$
- 线性对数阶 $O(nlogn)$
- 平方阶 O(n^2^)、立方阶 O(n^3^)…..k 次方阶 O(n^k^)
- 指数阶 O(2^n^)
- 阶乘阶 O(n!)
对于刚罗列的复杂度量级,我们可以粗略地分为两类,多项式量级和非多项式量级。其中,非多项式量级只有两个:$$O(2^n) $$和 O(n!)。
当数据规模 n 越来越大时,非多项式量级算法的执行时间会急剧增加,求解问题的执行时间会无限增长。所以,非多项式时间复杂度的算法其实是非常低效的算法。因此,关于 NP 时间复杂度我就不展开讲了。
我们主要来看几种常见的多项式时间复杂度。
1. O(1) 之一击必杀
首先我们必须明确一个概念,O(1) 只是常量级时间复杂度的一种表示方法,并不是指只执行了一行代码。比如这段代码,即便有 3 行,它的时间复杂度也是 O(1),而不是 O(3)。
int a = 1;
int b = 2;
int c = 3;我们的 HashMap get()、put() 其实就是 O(1) 时间复杂度。
只要代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。或者说,一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
2. O(logn)、O(nlogn)
对数阶时间复杂度非常常见,同时也是最难分析的一种时间复杂度。
i=1;
while (i <= n) {
i = i * 2;
}根据我们前面讲的复杂度分析方法,第三行代码是循环执行次数最多的。所以,我们只要能计算出这行代码被执行了多少次,就能知道整段代码的时间复杂度。
从代码中可以看出,变量 i 的值从 1 开始取,每循环一次就乘以 2。当大于 n 时,循环结束。还记得我们高中学过的等比数列吗?实际上,变量 i 的取值就是一个等比数列。如果我把它一个一个列出来,就应该是这个样子的:
$$2^0 2^1 2^2 ……..2^x = n$$
所以,我们只要知道 x 值是多少,就知道这行代码执行的次数了。通过 2^x^=n 求解 x 这个问题我们想高中应该就学过了,我就不多说了。x=log~2~n,所以,这段代码的时间复杂度就是 O(log~2~n)。
我把代码稍微改下,这段代码的时间复杂度是多少?
i=1;
while (i <= n) {
i = i * 3;
}很简单就能看出来,这段代码的时间复杂度为 O(log~3~n)。
实际上,不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复杂度都记为 O(logn)。为什么呢?
我们知道,对数之间是可以互相转换的,log3n 就等于 log~3~2 * log~2~n,所以 O(log~3~n) = O(C * log~2~n),其中 C=log~3~2 是一个常量。基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log~2~n) 就等于 O(log~3~n)。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)。
如果你理解了我前面讲的 O(logn),那 O(nlogn) 就很容易理解了。还记得我们刚讲的乘法法则吗?如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了。而且,O(nlogn) 也是一种非常常见的算法时间复杂度。比如,归并排序、快速排序的时间复杂度都是 O(nlogn)。
如下所示就是$O(nlogN)$ , 内部 while循环是 O(logn) ,被外层 for 循环包起来。所以 就是 O(nlogn)
for(m = 1; m < n; m++) {
i = 1;
while(i < n) {
i = i * 2;
}
}3. O(m+n)、O(m*n)
我们再来讲一种跟前面都不一样的时间复杂度,代码的复杂度由两个数据的规模来决定。
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}从代码中可以看出,m 和 n 是表示两个数据规模。我们无法事先评估 m 和 n 谁的量级大,所以我们在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。所以,上面代码的时间复杂度就是 O(m+n)。
针对这种情况,原来的加法法则就不正确了,我们需要将加法规则改为:T1(m) + T2(n) = O(f(m) + g(n))。但是乘法法则继续有效:T1(m)T2(n) = O(f(m) f(n))。
4.线性阶O(n)
看这段代码会执行多少次呢?
for(i=1; i<=n; i++) {
j = i;
j++;
}第1行会执行 n 次,第2行和第3行会分别执行n次,总的执行时间也就是 3n + 1 次,那它的时间复杂度表示是 O(3n + 1) 吗? No !
还是那句话:“大O符号表示法并不是用于来真实代表算法的执行时间的,它是用来表示代码执行时间的增长变化趋势的”。
所以它的时间复杂度其实是O(n);
平方阶O(n²)
for(x=1; i <= n; x++){
for(i = 1; i <= n; i++) {
j = i;
j++;
}
}把 O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O(n²) 了。
立方阶O(n³)、K次方阶O(n^k^)
参考上面的O(n²) 去理解就好了,O(n³)相当于三层n循环,其它的类似。
空复杂度分析
理解了前面讲的内容,空间复杂度分析方法学起来就非常简单了。
时间复杂度的全称是渐进时间复杂度,表示算法的执行时间与数据规模之间的增长关系。类比一下,空间复杂度全称就是渐进空间复杂度,表示算法的存储空间与数据规模之间的增长关系。
void print(int n) {
int i = 0;
int[] a = new int[n];
for (i; i <n; ++i) {
a[i] = i * i;
}
}跟时间复杂度分析一样,我们可以看到,第 2 行代码中,我们申请了一个空间存储变量 i,但是它是常量阶的,跟数据规模 n 没有关系,所以我们可以忽略。第 3 行申请了一个大小为 n 的 int 类型数组,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(n)。
打个不恰当的比喻,就像我们的手机现在工艺越来越好,手机也越来越薄。占用体积越来越小。也就是用更好的模具设计放置零件,而模具就像是空间复杂度更小的体积容纳更多的原件。
我们常见的空间复杂度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到。而且,空间复杂度分析比时间复杂度分析要简单很多。所以,对于空间复杂度,掌握刚我说的这些内容已经足够了。
空间复杂度 O(1)
如果算法执行所需要的临时空间不随着某个变量n的大小而变化,即此算法空间复杂度为一个常量,可表示为 O(1)。
int i = 1;
int j = 2;
++i;
j++;
int m = i + j;代码中的 i、j、m 所分配的空间都不随着处理数据量变化,因此它的空间复杂度 S(n) = O(1)。
空间复杂度 O(n)
int[] m = new int[n]
for(i=1; i <= n; ++i) {
j = i;
j++;
}这段代码中,第一行new了一个数组出来,这个数据占用的大小为n,后面虽然有循环,但没有再分配新的空间,因此,这段代码的空间复杂度主要看第一行即可,即 S(n) = O(n)。
总结
基础复杂度分析的知识到此就讲完了,我们来总结一下。
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度的算法,执行效率越低。
常见的复杂度并不多,从低阶到高阶有:O(1)、O(logn)、O(n)、O(nlogn)、O(n^2^ )。等学完整个专栏之后,就会发现几乎所有的数据结构和算法的复杂度都跑不出这几个。
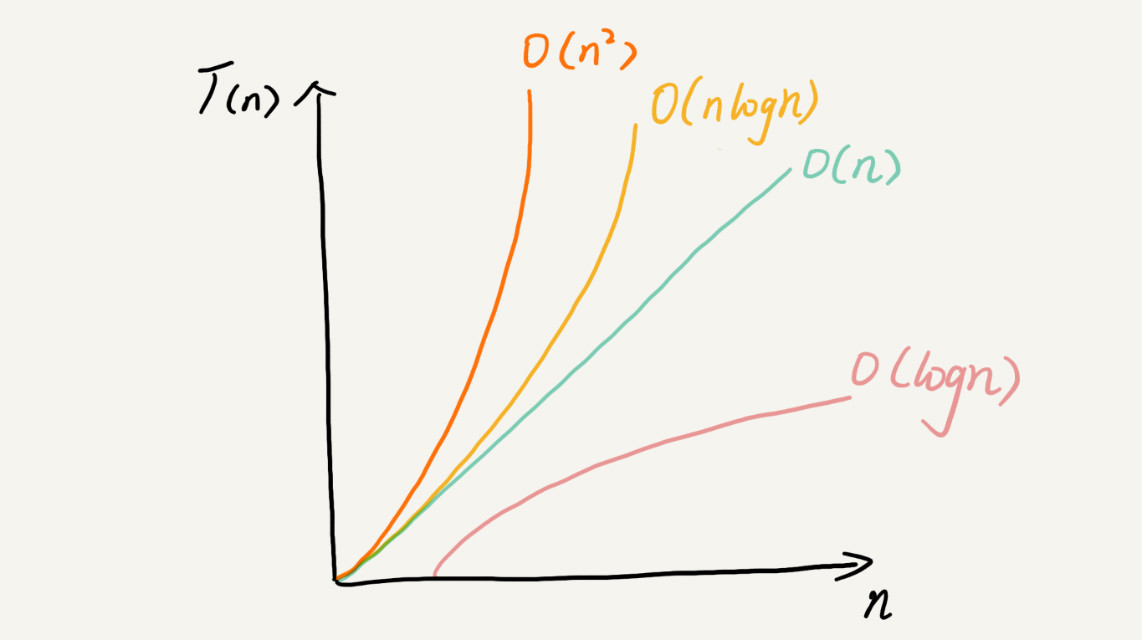
有人说,我们项目之前都会进行性能测试,再做代码的时间复杂度、空间复杂度分析,是不是多此一举呢?而且,每段代码都分析一下时间复杂度、空间复杂度,是不是很浪费时间呢?你怎么看待这个问题呢?
欢迎加群与我们分享,我们第一时间反馈。关注公众号MageByte ,后台回复 加群 即可。群内有一线互联网公司工作的大佬,相互学习,走向巅峰。

参考文献
- 《数据结构与算法之美》