第一章 覆盖表简介
覆盖表(Covering Arrays),又译覆盖阵列,是组合测试的重要研究领域之一,广泛应用于软件测试、硬件测试、材料测试和测试激素相互作用对基因表达的影响。
1.1 简述覆盖表的作用
软件和硬件的测试在产品的开发过程中扮演着重要的角色,因此软件测试常常在软件开发的过程中耗费大半时间和资源[1]通常情况下,即便是对于简单的软件或是硬件产品,穷举测试也是不可行的,因为可能的测试用例的数量非常巨大。因此需要一个科学有效的测试计划,对待测系统中各参数之间的组合进行有效的测试。这种组合测试需要一种测试用例集生成法,它可以生成少量高质量的测试用例。
根据研究表明,有百分之七十[2]的错误能通过测试每两个参数之间的关系找出。出于对测试用例生成的难度、测试的成本和覆盖强度对覆盖表规模的影响,对任意两个参数之间组合进行完全覆盖的二维覆盖表可以满足大部分的组合测试要求。
举个例子来说,假设我们有一台具有20个开关的原型机,每个开关有"开启"和"关闭"两个状态,我们希望在定型投产之前测试这台原型机。如果穷举的话总共有2^20种可能,全部测试一边显得不切实际而且花费大。在这种情况下我们可以换一种简单一些的方式,我们取一个所有测试用例的子集,在这个子集中任意三个开关之间的2^2种可能的组合都被测试到。这样问题就变成了如何让我们需要的测试用例集最小,这个问题就是覆盖表(Covering Arrays)问题的一个实例。
依照上述实例建模可以得到一个CA(10::2,20,2)的覆盖表,如下图。(具体定义会在下文中介绍)。这个覆盖表规模为10,每两列之间满足全排列。

图1 CA(10:2,20,2)
1.2 现行覆盖表算法
覆盖表的研究已有很长时间,目前有多种求解覆盖表的方法,启发式搜索方法、数学方法和许多种贪心算法,但这些方法都存在各自的局限性,并只能在解决某些特定问题时具有一定的优势。例如:TConfig[3]是一种利用正交表等基本成分进行递归构造的数学方法,该方法具有生成速度快的特点,但不足之处就是需要依赖已有的代数或组合对象。在启发式搜索方面,可以使用禁忌搜索和模拟退火(SA)等方法生成较小的测试用例集,但这些方法一般需要较长的时间.相比之下,启发式贪心算法不仅灵活,而且速度快,目前已经分别提出了 AETG、TCG、DDA和IPO等多种启发式贪心方法,这些方法之间既有区别又有很大的相似性。
下面简单介绍部分贪心算法框架之外的覆盖表生成算法。
1.2.1 Tconfig算法
使用正交拉丁方(orthogonal Latin Squares)的方法,生成双向的组合测试用例集。
设有两个阶数相同(为)的拉丁方阵
,其中将所有放置位置相同的元素组合成一个元组,组合成一个新的矩阵
。 当这个新的矩阵
中每一个元素互不相同,拉丁方阵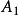 和是互相正交的。
和是互相正交的。
此时,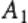 和
和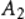 即为一对正交拉丁方。 而在阶数固定的情况下,所有两两正交的拉丁方所成的集合称为正交拉丁方族。
即为一对正交拉丁方。 而在阶数固定的情况下,所有两两正交的拉丁方所成的集合称为正交拉丁方族。
此算法利用正交拉丁方的特性,可以下小规模和特定情况下快速生成覆盖表。同样地,此算法因为基于拉丁方的特性不够灵活,不能应对通常情况。
1.2.2爬山算法
爬山、模拟退火和禁忌搜索是用于求解组合优化问题的状态空间搜索技术的变种。有一个一般的优化问题,目的是找到的解决方案是接近最优的。有许多我们已知的解决方案,能使得我们得到从成本上来说最佳的结果,同时,在这些解决方案下的用例集很小。
一个优化问题可以被指定为可行解(或状态)的集合Σ,以及成本C(S)对于每个 S ∈ Σ。最优解对应于具有总体最小成本的可行解。对于每个S ∈ Σ,我们定义了变换集合TS,TS中的每一种变换都可以用来将S变换成另一个可行解S'。通过从TS应用变换,可以从S转换出的相邻解称为S的邻域N(S)。
我们首先随机选择一个初始可行解,然后生成一个随机选择的当前可行解的变换S。如果变换得到一个相等或更低成本的可行解S,则S'被认为是新的当前可行解。如果S'是更高的成本,我们拒绝这个解决方案,并检查另一个随机选择的邻居当前可行的解决方案。这允许我们随机走动,而不降低我们当前解的优点。爬山有可能陷入局部极小(或冻结),因此需要停止启发式。为了增加形成一个好的解决方案的机会,我们重复随机游走(或试验)多次,每次从随机初始可行解开始。
在爬山算法中,当前可行解是一个近似的S覆盖阵列,其中某些T子集没有被覆盖。成本函数是基于未覆盖的T子集的数目,因此覆盖阵列本身将具有零成本。通过选择属于S的k个集合中的一个,然后通过不在k集合中的随机点替换该k个集合中的随机点来进行潜在变换。在爬山试验中,块的数量保持不变。
我们针对最优阵列的大小松弛的上下界,然后通过二分搜索过程在该区间中找到规模最小的覆盖阵列。另一种方法是从已知测试用例集的大小开始并搜索解决方案。当然,使用更少的计算资源,但必须提前知道所需的测试用例集大小。理想情况下,在实际系统中,使用第二种的方法。
1.2.3 禁忌搜索
Tabu搜索通过允许当前可行的解决方案被较差的替代来进行爬山。它限制使用禁忌和指定表的变化。第一是禁止被认为缺乏价值的操作,比如倒转刚刚做的操作。其次是分配更高的权重来实现期望的性能。NurMela[4]使用Tabu搜索描述了许多成功的搜索案例。
1.2.4 模拟退火
Nurmela 和 Osterg˚ard[5],[6]采用模拟退火方法,构造了与覆盖阵列非常相似的覆盖设计。Stevens〔7〕、Stardom〔8〕、科恩及其同事〔9〕将模拟退火应用于覆盖阵列的搜索。
模拟退火使用与爬山相同的方法,但允许算法以受控的概率进行选择,从而降低当前解决方案的质量。这个算法的思路就是在进行搜索的同时避免陷入坏的情况导致卡死。如果变换得到了较高成本的可行解S`,则在exp(−(c(S′)−c(S))/KBT)的概率下S`是可以接受的,其中T是控制模拟的温度,KB是一个常数。
在这个温度下,通过在每个温度下通过一系列跃迁(或马尔可夫链),允许系统在每个步骤中接近"平衡"。通常这是通过设置t:=αt来完成的,其中α(控制减量)是实数小于1。在满足适当的停止条件之后,将当前可行解作为对手头问题的解的近似。再次,我们通过多次试验来提高获得良好解决方案的机会。
1.2.5 Great Deluge 算法
另一种启发式搜索技术被称为great flood[10]或者是 great deluge[11],是threshold accepting算法的一种变种。
这些算法遵循类似于模拟退火的策略,但通常显示更快速的收敛。当成本较高时,不使用概率来决定移动,如果成本小于当前阈值,则选择更差的可行解。这个阈值有时被称为水位,在利润最大化的问题中,水位将上升而不是下降(正如在这种情况下发生的)。随着算法的发展,阈值被降低,使其接近零。这些似乎没有探索覆盖阵列的构造。
1.2.6 遗传算法
在启发式搜索的领域中,遗传算法被证明是有相当竞争力的。其基本的思路是维持一个假定的解决方案的人口,并且由两种操作将人口从一代演变到下一代。突变使假定的解决方案中发生局部局部变化,而交叉组合了一个解决方案的一部分和另一个解决方案的一部分。新一代的生存取决于每一个新推定的解决方案的相对适合度。粗略地说,这决定了如何"接近"到所需的覆盖数组。
第二章 覆盖表的基本定义和应用
2.1 待测系统
待测系统(System Under Testing)是覆盖表服务的对象,系统在此是一个泛指。假定影响SUT的参数有k个,记为F={f1, f2, f3, …. fk},其中参数fi有ai个取值Vi = {0,1,2,3....ai-1},,1≤i≤k。
2.2 覆盖表的定义
记SUT 的一条测试用例为k 元组(v1,v2,…,vk)(viVi)。
覆盖表是组合测试的用例集,其定义[12]如下:
待测试系统 SUT 的 t 维覆盖表 CA(N;t,k, (v1,v2,…,vk))(或 CA(N;t,v^k),当 v1=v2=…=vk=v 时)是一个 Nk的数组,其中第 i 列对应第 i 个参数。该参数取值记为 vi,任意 t 个参数形成的 N x t 的子数组中包含了该 t 个参数的所有 t 元组[13],其中,t 为组合覆盖测试的强度。本文中提到的两两组合测试指的是 t=2 的情况,即利用二维覆盖表 CA(N;2,k,(v1,v2,…,vk))进行测试。
下面我们引入一个例子方便理解定义:
一个网络软件系统,它也许可以让用户自定义多种不同的浏览器(f1),它也可以运行在不同的操作系统(f2)上, 使用多种不同的网络连接方式(f3)和打印方式(f4)。如果我们要测试这个系统(如表2.1)我们需要这样子的用例:(IE,Windows,LAN,Local)、(Chrome, MacOS, PPP, Networked)。为了测试所有可能的组合,我们需要3^4,也就是81条测试样例。
表1 网络软件系统的配置
| Web Browser |
Operation System |
Connection Type |
Print Config |
| IE(0) |
Windows(0) |
LAN(0) |
Local(0) |
| Chrome(1) |
MacOS(1) |
PPP(1) |
Networked(1) |
| FireFox(2) |
Linux(2) |
ISDN(2) |
Screen(2) |
也许这总共81条测试用例看起来可以接受,但是如果我们将参数的数量增加到十个的时候,我们就总共需要测试3 ^ 10 = 59 049个测试用例。
然而,我们可以保证当我们测试了所有任意两个参数之间的全排列或是t个参数之间的全排列。在表2.2中,我们可以只使用9个不同的测试用例来覆盖如表2.1中所示的每两个参数之间的全排列,在最坏情况下也能用29条测试用例来覆盖所有对[14][15]。成对覆盖的概念已经应用于许多学科,包括医药、农业和制造业[29]。
Kuhn[31]发表了了三个关于软件系统故障的研究报告。它们表明,70%的故障可以发现通过测试所有两路覆盖,而90%的故障可以通过测试所有三路覆盖的相互作用检测。在这些实验检测的系统中,六路覆盖检测可以检测出100%的故障。美国食品安委员会(FDA)之后做过类似实验[30],这些实验发现,实验涉及的109种情况中的97%的缺陷可以通过成对的(两路覆盖)参数设置测试来检测。只有三种情况要求覆盖率高于成对覆盖。
表2 网络软件系统测试用例集
| Test No |
Web Browser |
Operation System |
Connection Type |
Memory |
| 1 |
IE |
Windows |
LAN |
Local |
| 2 |
Chrome |
MacOS |
LAN |
Networked |
| 3 |
IE |
MacOS |
PPP |
Screen |
| 4 |
FireFox |
Linux |
LAN |
Screen |
| 5 |
IE |
Linux |
ISDN |
Networked |
| 6 |
Chrome |
Linux |
PPP |
Local |
| 7 |
FireFox |
Windows |
PPP |
Networked |
| 8 |
Chrome |
Windows |
ISDN |
Screen |
| 9 |
FireFox |
Linux |
ISDN |
Local |
2.3 覆盖表的应用
覆盖表黑应用在很多领域中,以下是一些例子。[16]
2.3.1 软件交互测试
软件测试占据任何软件项目的成本的很大一部分,即便如此仍然会发生喝多故障。事实上,来自美国国家标准与技术研究所(NIST)的2002份报告报告了一个令人担忧的结论,即软件测试不足每年会导致$95亿美元的成本,并将大量的数据归因于嵌入在硬件中的软件故障[4]。Carroll[2,3]还描述了软件测试不足的成本。近年来,许多政府机构已经开始使用更多的现成商业软件(COTS)。许多机构和企业已在为测试方法努力开发适当的模型,开发适当的覆盖方法,涉及覆盖可靠性和故障检测,并开发自动测试生成器。此外,在测试通信系统和存储系统中的应用也得到了处理。
每个组件可能都需要单独的测试和认证;然而,系统故障很可能是由于意外的交互作用而产生的。如果通过集成测试可以防止这些故障的一小部分,这可能会产生重大的经济影响。在使用组件时,我们最好在系统发布之前测试组件的所有组合,然而,即使在一个中等规模的项目中,测试所有可能的组合所需的测试用例集的大小也是令人望而却步的。
软件组件可能由于异常的交互而产生系统故障。理想情况下,人们应该测试组件的所有可能组合,但实际情况下可能存在大量的组合。因此,成对(pairwise)或T路(t-wise)测试可以测试固定的交互级别,在实践中发现大量的故障。
作为一种折衷方案,可以应用组合设计技术来替代特定的固定级别的交互测试,即成对测试或T-WISE测试。虽然这并不能为我们提供完全的覆盖,但在交互测试中发现大量故障是成功的
现在有两个不同领域正在积极研究的组合设计软件交互测试。正如我们所见,组合测试研究者致力于构建更高的交互强度的更小的用例集。软件测试团体专注于贪婪搜索算法,在更灵活的框架中建模,使其更紧密地匹配实际测试需求。软件测试人员无法预期掌握软件测试套件生成的每一种技术,甚至无法确定哪种可用方法对它们的应用是最好的。虽然这个问题的多维建模方法被发现,但解决方案的范围是有限的。软件交互测试所需要的是一种有用的工具,它们通过单独和统一地使用每种技术来构造测试套件的单一、统一的手段来处理这些技术。
2.3.2 硬件测试
在电路中,输入信号通过算术和逻辑运算相互作用,以产生期望的输出向量。然而,错误仍然可能发生。在硬件交互测试中,可以使用覆盖数组来解决这个硬件测试问题。
假设我们要测试一个有k个输入的电路,在电路内,输入信号通过算术和逻辑运算相互作用,以确定输出向量。就像测试软件一样,我们希望通过一系列的输入向量来判断是否有故障,故障发生在哪里。在这种电路实验中,每个参数常常只有高电位和低电位两种,根据Dumer[17]的研究,使用二维覆盖表可以方便测试。
2.3.3 高级材料测试(Testing Advanced Materials)
有时将材料结合以产生改进的性能,如强度、柔韧性和熔点。同样地,某些组合是有毒的或爆炸性的,必须避免。覆盖表可以帮助设计实验。
Cawse[18]在他的论文中混合物实验的实验方案,采用CA(t,k,2)的覆盖表来验证混合物在不同环境下的物质特性。
2.3.4 调控基因表达的相互作用(Interactions Regulating Gene Expression)
激素影响特定基因的表达,并可能相互作用。虽然并不是所有可能的激素组合都可以被检测出来,但它是很有趣的少量激素之间的相互作用。同样,覆盖表是一个非常合适的建模工具来解决这样
第三章 覆盖表的贪心算法框架
3.1 算法框架描述
贪心的中心思路就是每次选择一条当前最优的测试样例(是一个k元祖)加入测试用例集[19]。被加入用例集的测试用例集的用例可能从多个候选用例中选出,每个候选用例均由一组策略生成。由于候选用例生成策略中存在随机值和可变参数,候选用例会有所不同。
假设待测系统有k个参数,每个参数fi有Ai个可能的取值,测试用例集合为C。
① 依照参数选择策略选取第i个参数 //决策点1
② 如果有多个参数可选,则采用同序参数选择策略选择第i个参数 //决策点2
③ 给选定的第i个参数按照赋值策略赋值 //决策点3
④ 如果有多个参数可选,则采用同序赋值策略给所选的参数赋值 //决策点4
⑤ 循环步骤①~步骤④,直到所有的参数都被赋值,生成用例T //第4层
⑥ 循环步骤①~步骤⑤Candidates次,生成多个测试用例 //决策点5,第3层
⑦ 选取覆盖未被覆盖对最多的测试用例作为最终的测试用例,加入集合C
⑧ 循环步骤①~步骤⑦,直到参数之间的两两组合都被覆盖为止,得到了覆盖表 //第2层
⑨ 反复执行步骤①~步骤⑦Repeitition次,选择规模最小的作为最终结果 //第1层,决策点6
表3 6个决策点中每个决策点的具体决策
| Reputition count |
Candidate count |
Factor ordering |
Level Select |
Factor tie-breaking |
Level tie-breaking |
| A Constant |
A Constant |
Uncovered pairs |
Uncovered pairs |
Uncovered pairs |
Uncovered pairs |
| Random |
Random |
Random |
Random |
||
| Density |
Density |
Take First |
Take First |
||
| Level |
Least Using |
||||
| Hybrid |
3.2 参数选择(决策点1)
对于该策略点有以下几种备选算法
(1)随机选择 (Random)
(2)和已确定参数及待定参数的期望相关,密度聚类(Density peaks Clustering)
(3)选择可与已确定参数之间存在最多未被覆盖对的参数(Uncovered Pairs)
(4)杂交策略 (Hybrid)
(5)和参数取值数目相关,按照参数取值数目降序排列 (Take First)
3.3 赋值策略(决策点2)
赋值策略的目的是所选择的值和已确定的值组成的对能尽可能多的覆盖未被覆盖对。
(1)与全部未被覆盖对的期望相关,密度聚类(Density peaks Clustering)
(2)随机赋值
(3)和已确定参数组合能产生最多未被覆盖对 (Uncovered Pairs)
3.4 同序参数选择(决策点3)
在参数选择中可能会出现几个参数有相同优先级的情况。在遇到这种情况时,可采用随机选择、按字典序以及未被覆盖对最多的方法来打破平局。
3.5 同序值选择(决策点4)
在赋值策略中可能会出现平局的情况。在遇到这种情况时,可采用随机选择、字典序、最少使用过的值和未被覆盖对最多的值。
3.6 候选用例数目(决策点5)
因为某些决策点采用随机选择,每轮可以产生几组不同的用例,在其中选择未被覆盖对最多的加入结果集合C。根据其他决策点决策选择的不同,备选用例集的最佳数目也会不同。本文将对于这个决策点设计实验,确定一个或几个相对优秀的常数作为备选用例集数目。
3.7 算法循环次数(决策点6)
因为某些决策点的策略是随机的,所以多次循环可以得到多组不同的结果,这样获得最优解的概率会增加。然而,重复执行算法自然会增加时间成本,而且在实践中可以发现,当循环次数增加到一定程度时,覆盖表规模也不会减小了。本文将对于这个决策点设计实验,确定一个或几个相对优秀的常数作为算法循环次数。
3.8 测试用例数目的对数增长
在固定的强度下,测试用例数目随着参数数目的增加对数增长。下面我们以强度t = 2 的情况为例,简要证明对数增长。
定理3.1[19]:存在一个有k个参数的待测系统,每个参数有L个取值。假定,现在有r条测试用例已经被确定,未覆盖对的数量为N。那么存在一条新的测试用例可以覆盖至少N/L^2个未覆盖对。
证明:设有一集合
U={ (h, p) | h是一条测试用例,t是h被覆盖的对 }
因为有k个参数,每条测试用例覆盖k ( k – 1 ) / 2个对,所以,U中的每个h对应k ( k – 1 ) / 2个不同的p。因为,每个参数有L个取值,所以,每个对p出现在集合U里的L ^ ( k – 2 )个不同的测试用例中。
设V是U的一个子集由(h,p)构成,满足测试用例h不在已选定测试用例集r中,并且对p未被已选中测试用例集覆盖。我们通过两种不同的方法计算Card(V)的两种不同方式,赖桢敏定理3.1。
对于V中任意的(h,p),因为p未被覆盖,所以p没有被已选定的测试样例覆盖。因此,p出现在V中的L ^ ( k – 2 )条不同的测试用例h中。因而,如果未被覆盖对的总数是N,那么
Card (V) = N * L ^ ( k – 2 )
对于每个位被选中的测试用例h,设mh是被h新覆盖的对的数量。若h是已选定集r中的某一条,那么mh的值为零。则h在V中出现mh次,因此
Card (V) = SUMh (mh)
现在令m为mh中的最大值,为了证明定理我们必须要证明m至少为N/L^2。因为可选测试用例的总数是L ^ k,我们就可以得到以下不等式。
Card (V) = SUMh (mh) <= m * L ^ 2
因此,N * L ^ ( k - 2 ) <= m * L ^ k,即
N / L ^ 2 <= m
我们已经通过上述步骤证明了定理3.1,那么在算法过程中肯定存在一条测试用例覆盖1 / L ^ 2个剩余对。现设贪心算法选择每条测试用例时覆盖了尽可能多的未被覆盖对,N是初始时的为被覆盖对数量,因为存在k个参数,每个参数有L个取值,那么N = k ( k – 1 ) / 2 * L ^ 2。使用贪心算法当r条测试用例已经被选定之后,剩下的待覆盖对的数量是
N' <= N * (1 – 1 / L ^ 2 ) ^ r
因此,如果r > - log (N) / log ( 1 – 1 / L ^ 2 )则N' < 1那么所有的对都已经被覆盖,
使用近似法log(1 – 1 / L ^ 2) = -1 / L ^ 2,由此我们可以推导当贪心算法覆盖所有未覆盖对时,
r > L ^ 2 * log(N) >= L ^ 2 * ( log(k ( k – 1 ) / 2) + 2 log(L) )
上述证明表明贪心算法所需要生成的测试样例个数随着k的增大而对数增长,并且和L的二次方正相关。[26]
3.9 贪心算法框架下的已有贪心算法
3.9.1 The Automatic Efficient Test Generator (AETG) System
AETG[19][20][21]算法是已有的一种覆盖表生成贪心算法,其组合是(hybrid,uncovered pairs,—,uncovered pairs,—,50)。在AETG中的同序参数选择策略和算法循环次数可以随意指定。AETG参数选择策略采取的是杂交策略,第一个参数选择了未覆盖对最多的参数,其余参数随机排序。
假设待测系统有k个参数,每个参数有v个值。现在我们选择了r个测试样例之后,当我们在选择第r + 1测试样例时,首先生成CandidateCount个不同的候选用例,然后从中选择一个覆盖最多未被覆盖对的测试用例。每个候选测试用例由以下贪心算法选择:
1. 选择一个参数f,这个参数的一个值L在当前未被覆盖对中出现的频率最高。将参数f赋值为L。
2. 令f1 = f,并将剩下的参数乱序排列加入待赋值队列。
3.假设f1到fj已经被赋值,对于1 <= i <= j ,令fi的赋值为vi,然后用如下方法为fj+1选择赋值vj+1。vj+1在所有可选值中与已经赋值的参数组成的未覆盖对最多。
由于候选测试用例依赖于在步骤2中选择的随机顺序,使用不同的随机种子可以产生不同的测试集。一个有效的优化是使用50个不同的随机种子生成50个不同的测试集,然后选择其中最优的。这样有几率将生成的测试的数量减少十到百分之二十,也有确定性的构造和可替代的随机算法[25],有时生成更少的测试用例。
3.9.2 DDA算法(deterministic density algorithm)
DDA[22][23]算法也是目前已有的一种贪心算法,在贪心算法框架下的组合是( density, density, take first, take first, 1, 1 )DDA给所有参数定义了一个密度值,其中没有随机策略,因此DDA是一种确定性算法。
DDA算法的重点在于Density策略的实现,使用密度公式计算未被覆盖对数量的期望。在此之前我们先做一些定义,将当前计算参数的密度定义为E,r(i,j) 当前参数i和另一个参数j之前的未覆盖对数目,定义λ为两参数之间的对数总数。E的计算方法为:
1. 如果两个参数之间存在多个未被覆盖对则
E = ( r(i,j) / λ ^ 2 )
2. 如果只有一个参数有一个取值另一个参数有多个取值之间存在未被覆盖对,则
E = (r(i,j) / λ ) ^ 2
3. 如果两个参数都只有一个可选赋值,若这两个值组成的对被覆盖则E = 1.0,否则E = 0.0。
3.9.3 TCG算法
TCG[24]与AETG接近,其差异在于它的参数选择策略与AETG的参数选择策略不同。参数按照参数课选择数目降序排列。值选择策略采用的是杂交策略。
参考文献
-
Kobayashi, N. (2002). Design and Evaluation of Automatic Test Generation Strategies for Functional Testing of Software. PhD thesis, Osaka University.
-
C.T. Carroll, The cost of poor testing: A U.S. government study I, EDPACS: TheEDP Audit, Control, and Security Newsletter 31,1 (2003).
-
C.T. Carroll, The cost of poor testing: A U.S. government study II, EDPACS: The EDP Audit, Control, and Security Newsletter 31,2 (2003).
-
National Institute of Standards and Technology. The Economic Impacts of Inadequate Infrastructure for Software Testing. U.S. Department of Commerce, May 2002.
-
Bryce RC, Colbourn CJ, Cohen MB. A framework of greedy methods for constructing interaction test suites. In: Proc. of the 27thInt'l Conf. on Software Engineering (ICSE 2005). New York: ACM Press, 2005.W
-
Colbourn,C.J.(2005).Combinatorial aspects of covering arrays. Le Matematiche (Catania).
-
I.I. Dumer. Asymptotically optimal codes correcting memory defects of fixed multiplicity. Problemy Peredachi Informatskii, 25: 3–20, 1989.
-
J.N. Cawse (ed.), Experimental Design for Combinatorial and High Throughput Materials Development, John Wiley & Sons, New York, 2003
-
Williams AW, Prober RL. A practical strategy for testing pair-wise coverage of network interfaces. In: Proc. of the 7th Int'l Symp. on Software Reliability Engineering (ISSRE'96). White Plaints, 1997.
-
K. Nurmela. Upper bounds for covering arrays by tabu search. Discrete Applied Math.,138 (2004).
-
K. Nurmela and P. R. J. Osterg˙ard. Constructing covering designs by simulated an ¨ -nealing. Technical report, Digital Systems Laboratory, Helsinki Univ. of Technology,1993.
-
B. Stevens, Transversal Covers and Packings, Ph.D. Thesis, Mathematics, University of Toronto, 1998.
-
J. Stardom. Metaheuristics and the search for covering and packing arrays. Master's thesis, Simon Fraser University, 2001.
-
M.B. Cohen. Designing Test Suites for Software Interaction Testing. Ph.D. Thesis, University of Auckland, 2004.
-
NASA Goddard/IEEE Software Engineering Workshop. NASA Goddard Space Flight Center, 2002.
-
G. Dueck. New Optimization Heuristics - The Great Deluge Algorithm and the Recordto-Record Travel. Journal of Computational Physics, 104:86–92, 1993.
-
G. Dueck and T. Scheuer. Threshold Accepting: A general purpose optimization algorithm appearing superior to simulated annealing. Journal of Computational Physics,90: 161–75. , 1990.
-
Nie CH, Leung H. A survey of combinatorial testing. ACM Computing Survey, 2011,43(2):1-29.
-
D. M. Cohen, S. R. Dalal, M. L. Fredman, and G. C. Patton. The AETG system: an approach to testing based on combinatorial design. IEEE Transactions on Software
Engineering, 23(7):437–44, 1997. -
Cohen DM, Dalal SR, Kajla A, Patton GC. The automatic efficient tests generator (AETG) system. In: Proc. of the 5th IEEE Int'l Symp. on Software Reliability Engineering. 1994. 303-309. [doi: 10.1109/ISSRE.1994.341392]
-
Cohen DM, Dalal SR, Fredman ML, Parelius J, Patton GC. The combinatorial design approach to automatic test generation. IEEE Software, 1996,13(5):83-88. [doi: 10.1109/52.536462]
-
Colbourn CJ, Cohen MB, Turban RC. A deterministic density algorithm for pairwise interaction coverage. In: Proc. of the IASTED Int'l Conf. on Software Engineering. 2004.
-
Bryce RC, Colbourn CJ. The density algorithm for pairwise interaction testing.Software Testing,Verification,and Reliability,2007.
-
Tung Y, Aldiwan W. Automating test case generation for the new generation mission software system. In: Proc. of the IEEE Aerospace Conf. 2000. 431-437. [doi: 10.1109/AERO.2000.879426]
-
D. M. Cohen and M. L. Fredman, "New Techniques for Designing Qualitatively Independent Systems," Rutgers Technical Report DCS-96-114, Nov 1996,
-
L. Gargano, J Korner and U. Vaccaro, "Sperner Capacities," Graphs and
combinatorics, Vol 9, pp 31-46, 1993. -
R. Brownlie, J. Prowse, and M. S. Phadke. Robust testing of AT&T PMX/StarMAIL
using OATS. AT&T Technical Journal, 71(3):41–7, 1992. -
I. S. Dunietz, W. K. Ehrlich, B. D. Szablak, C. L. Mallows, and A. Iannino. Applying design of experiments to software testing. In Proc. of the Intl. Conf. on Software Engineering, (ICSE '97), 1997, pp. 205-215, New York.
-
A. Hedayat, N. Sloane, and J. Stufken. Orthogonal Arrays. Springer-Verlag, New York, 1999.
-
D. Kuhn and M. Reilly. An investigation into the applicability of design of experiments to software testing. Proc. 27th Annual NASA Goddard/IEEE Software Engineering Workshop, 2002, pp. 91-95.
-
R. Kuhn, D. Wallace, and A. Gallo. Software Fault Interactions and Implications for Software Testing. IEEE Transactions of Software Engineering, June 2004, 30(6), to appear.