在Linux中,文本处理无非是对文本内容做查看、修改等操作。本章将介绍Linux中常用的文本处理命令,以及被称为Linux三剑客的 grep、sed 和 awk 命令。三剑客以正则表达式为基础,熟练使用这三个工具可以使我们的运维工作大大滴提高效率。在学习这三个命令之前,我们首先简单了解一下正则表达式,学正则表达式之前我们先看一下面的通配符和特殊字符:
一、通配符、特殊符号
1.1常用的通配符及含义
| 字符 | 含义 |
|---|---|
| * | 任意字符 |
| ? | 任意单个字符 |
| [] | 范围 |
| {} | 序列 |
例:
#-----任意字符
[root@localhost ~]# ls /etc/*pass #列出/etc/目录下以pass结尾的所有内容
ls: cannot access /etc/*pass: No such file or directory #没有相应的内容
[root@localhost ~]# ls /etc/pass* #列出/etc/目录下以pass开头的所有内容
/etc/passwd /etc/passwd- #匹配到有两项
###-----序列
[root@localhost ~]# touch a{01..10} #连续创建10个以a开头的普通文件
[root@localhost ~]# ls
1. a03 a06 a09 adduser.sh his.txt passwd.txt
a01 a04 a07 a10 anaconda-ks.cfg ifconfig
a02 a05 a08 aa. err.txt ipaddr
#-----范围
[root@localhost ~]# touch asda was2 23sad 323asd sad2 s2sa 2sdaf a
[root@localhost ~]# ls [a-z]
a
#-----任意单个字符
[root@localhost ~]# ls /etc/host?
/etc/hosts
1.2特殊字符
| 字符 | 含义 |
|---|---|
| ‘’ | 强引用,把其中的字符看成一个整体,不解析变量 |
| “” | 弱引用,有变量解析变量 |
| `` | 命令,优先执行 |
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| ; | 不管前面的命令执行成功与否都会执行下一个命令 |
| && | 前面的命令执行成功才执行后面的命令 |
| ll | 前面的命令执行失败才执行后面的命令 |
| # | 注释;命令提示符身份 |
| $ | 变量;命令提示符身份 |
| ! | 取反;调用之前使用过的命令 |
| <,>,<<,>>,&> | 重定向 |
| l | 管道符,前面的输出作为后面的输入 |
| ~ | 家目录 |
| . | 当前目录;在当前文件名面前表示隐藏;chown改属组 |
| … | 上一级目录 |
| - | 文件类型:普通文件;cd - 进入上一次目录;su - 完全切换用户 |
| + | chmod加权限 |
例:
#-----弱引用
[root@localhost ~]# NAME=xiaoming
[root@localhost ~]# echo "my name is $NAME"
my name is xiaoming
#-----强引用
[root@localhost ~]# echo 'my name is $NAME'
my name is $NAME·
#------序列
[root@localhost ~]# touch a ab
[root@localhost ~]# ls a{,b}
a ab
[root@localhost ~]# cp a{,.back}
[root@localhost ~]# ls
a ab aback a.back anaconda-ks.cfg
二、正则表达式
正则表达式(Regular Expression)是一种字符模式,主要由一些元字符组成,用于在指定字符中匹配指定的字符,它将匹配被查找的行中任何位置出现的相同的模式。
正则表达式的作用:
Linux系统支持正则表达式的命令有find、grep、sed、awk
可以对大量的字符文件进行配置和处理,而且是非交互式的
可以过滤、匹配、打印相关的字符串
其实正则表达式就是一些特殊字符,只不过赋予了其特殊含义,其又分为基本正则表达式和扩展正则表达式:
| 基础正则表达式字符 | 描述 |
|---|---|
| \ | 转义符 |
| . | 匹配任意单个字符 |
| [^] | 匹配除了其内部以外的任意一个字符 |
| [] | 匹配其内部任意一个字符 |
| \ + | 匹配之前的字符1次或多次 |
| \? | 匹配之前的字符0次或1次 |
| .* | 匹配任意长度任意字符 |
| \ {n\ } | 匹配之前的项n次 |
| \ {n,m \ } | 至少n次最多m次 |
| {n,} | 至少n次 |
| \ <或\b | 词首锚定 |
| \ >或\b | 词尾锚定 |
| [[:upper:]] | 所有大写字母[A-Z] |
| [[:lower:]] | 所有小写字母[a-z] |
| [[:digit:]] | 所有数字[0-9] |
| [[:alnum:]] | 所有字母和数字[a-zA-Z0-9] |
| [[:punct:]] | 所有标点符号 |
| [[:space:]] | 空格 |
| 扩展正则表达式字符 | 描述 |
|---|---|
| ^ | 匹配行首,在awk中则是匹配字符的开始 |
| $ | 匹配行尾,在awk中则是匹配字符的结尾 |
| ^$ | 空行 |
| & | 引用模式匹配到的整个串 |
| ? | 匹配之前的字符0次或1次 |
| + | 匹配之前的字符1次或多次 |
| * | 匹配之前的字符0次或多次 |
| . | 匹配任意单个字符,除空行外 |
| () | 创建一个用于匹配的整体 |
| {n} | 匹配之前的项n次 |
| {n,m} | 至少连续n次最多m次 |
| {n,} | 至少n次 |
| l | 交替匹配;ab(cld):abc或abd |
三、实战部分
3.1、三剑客之grep
用法:grep [OPTIONS] PATTERN [FILE…]
常用选项:
-v :反向过滤
-n :显示行号(-n “”)
-i :忽略大小
-E :支持扩展正则表达式字符。等价于egrep
测试文件内容:
[root@localhost ~]# cat -A test.txt
linuxm $
adadasdasdadasm$
21312m$
hsj23$
khw3324ww.$
I Hate You,You BadBad$
I Love You$
$
mlinux.$
test5201ad3s14saddasssswqzlikes$
swzsadwswzsaswszswz$
MlinuxNN$
asaAaaa$
aBBBaaas$
$
$
$
MLinuxBB$
LINUX$
I Hate You,You BadBad$
I Love You $
[root@localhost ~]#
//排除空行
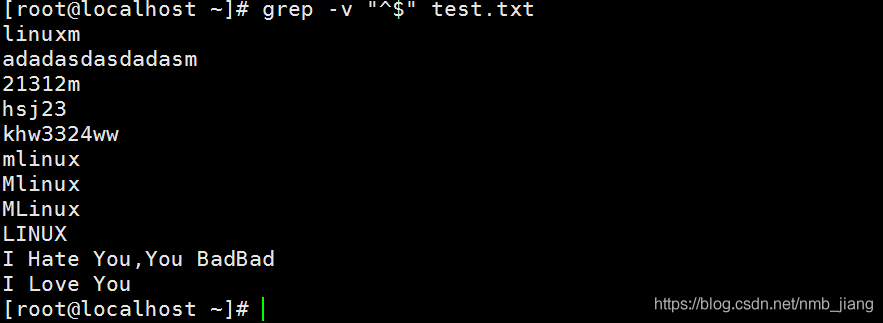
//找出以M或m开头的行

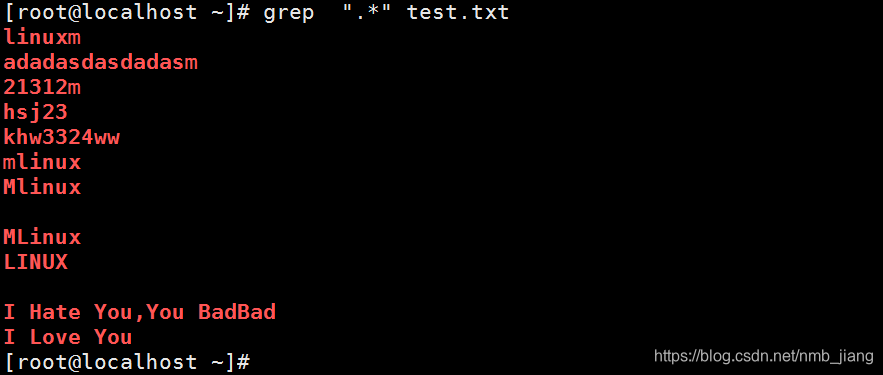
//匹配所有内容
//找出以m结尾的行

找出以数字开头的行:

//找出以.结尾的行

//匹配a出现一次或多次
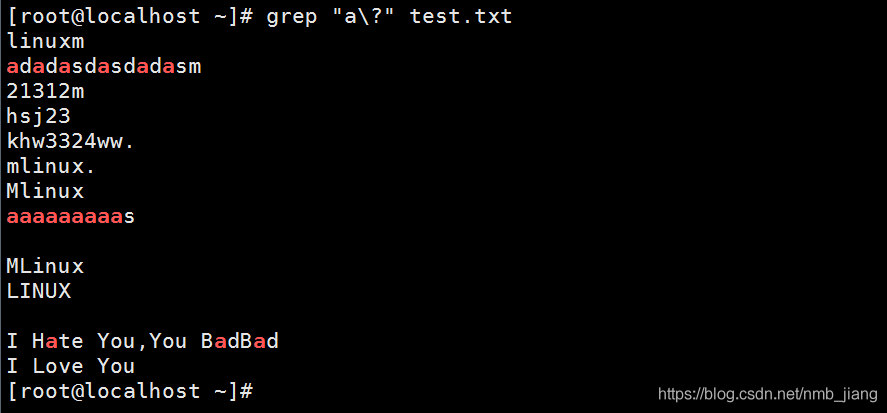
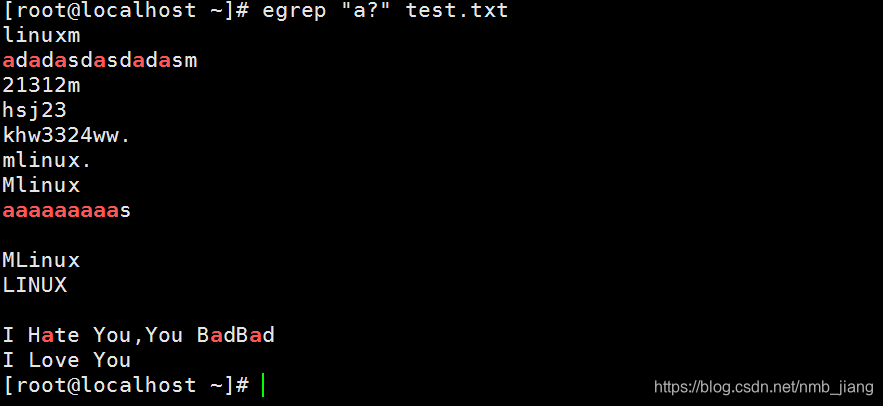
//匹配a至少连续出现两次至多连续出现4次

//词首、词尾锚定(事实证明这个不管是用grep还是egrep符号的\都是不能省略的)
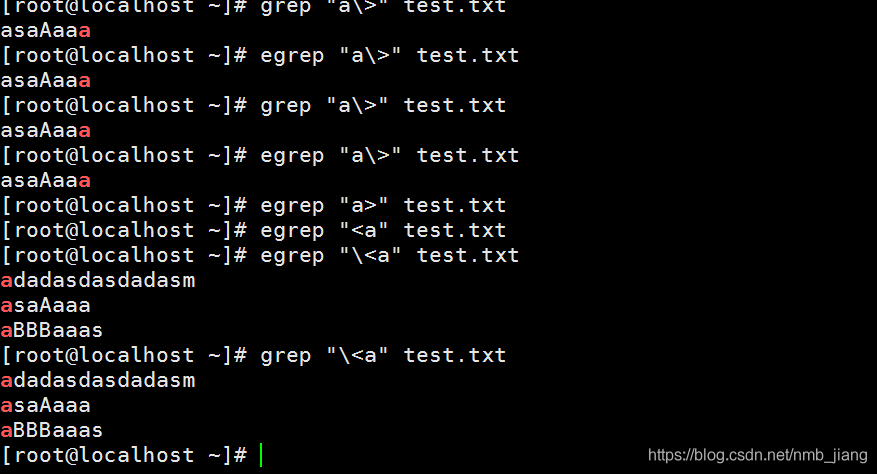
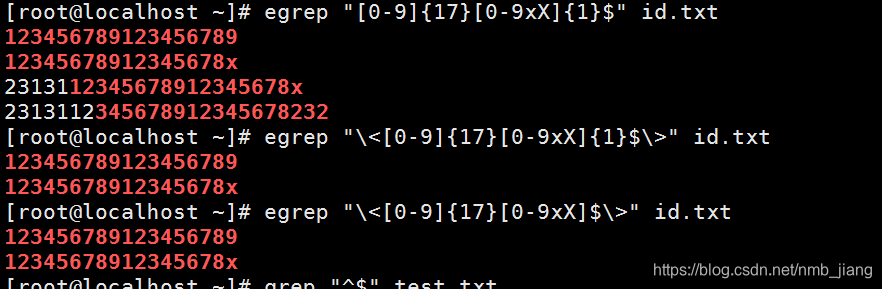
//找出包含空格的行、找不包含空格的行
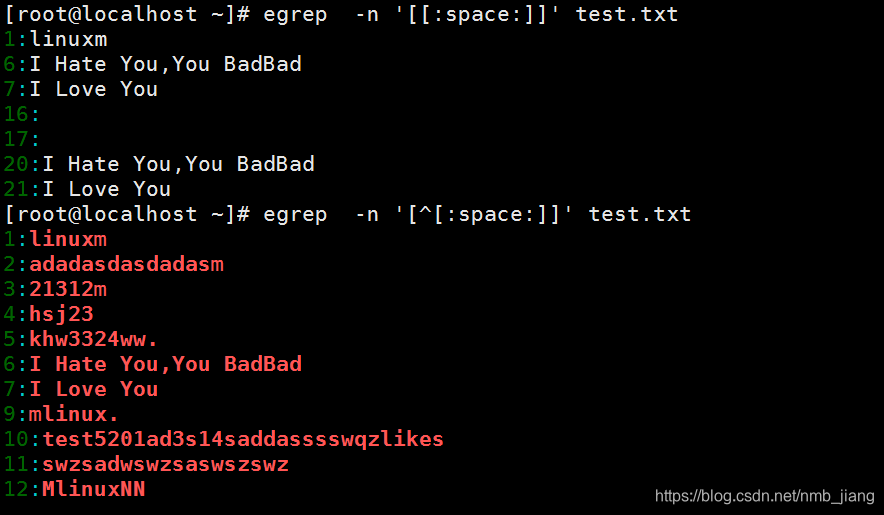
(注意:egrep -n ‘[[:space:]]’ test.txt 找出了包含空行的行而egrep -n ‘[1]’ test.txt 不排除含有空格的行,排除了空行)
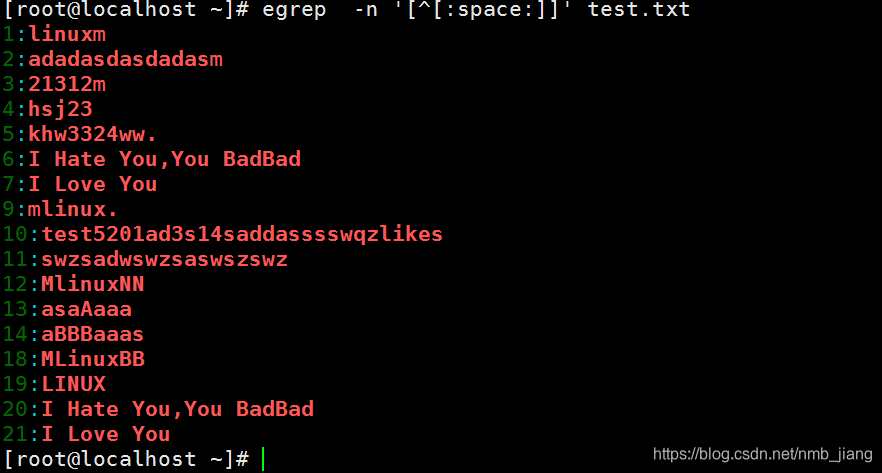
//以空格开头且后面是非空格的行
grep "^[[:space:]].+[^[:space:]]+" -nE /etc/grub2.cfg
:space: ↩︎
