One-Hot 编码即独热编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。这样做的好处主要有:1. 解决了分类器不好处理属性数据的问题; 2. 在一定程度上也起到了扩充特征的作用。
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。离散特征进行one-hot编码,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1。
基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。基于参数的模型或基于距离的模型,都是要进行特征的归一化。Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
one hot encoding的优点就是它的值只有0和1,不同的类型存储在垂直的空间。缺点就是,当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。总的来说,要是one hot encoding的类别数目不太多,建议优先考虑。
- one hot 编码及数据归一化
- 对于非负数类型编码 利用onehotEncode
- 对于字符以及混合类型编码 利用labelEncode
# 简单来说 LabelEncoder 是对不连续的数字或者文本进行编号 # sklearn.preprocessing.LabelEncoder():标准化标签,将标签值统一转换成range(标签值个数-1)范围内 from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit([1,5,67,100]) le.transform([1,1,100,67,5]) out: array([0, 0, 3, 2, 1], dtype=int64) #OneHotEncoder 用于将表示分类的数据扩维: from sklearn.preprocessing import OneHotEncode ohe = OneHotEncoder() ohe.fit([[1],[2],[3],[4]]) ohe.transform([[2],[3],[1],[4]]).toarray() out:array([[ 0., 1., 0., 0.], [ 0., 0., 1., 0.], [ 1., 0., 0., 0.], [ 0., 0., 0., 1.]])
- 源码:
Examples -------- Given a dataset with three features and four samples, we let the encoder find the maximum value per feature and transform the data to a binary one-hot encoding. >>> from sklearn.preprocessing import OneHotEncoder >>> enc = OneHotEncoder() >>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], \ [1, 0, 2]]) # doctest: +ELLIPSIS OneHotEncoder(categorical_features='all', dtype=<... 'numpy.float64'>, handle_unknown='error', n_values='auto', sparse=True) >>> enc.n_values_ array([2, 3, 4]) >>> enc.feature_indices_ array([0, 2, 5, 9]) >>> enc.transform([[0, 1, 1]]).toarray() array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.]])
Examples -------- `LabelEncoder` can be used to normalize labels. >>> from sklearn import preprocessing >>> le = preprocessing.LabelEncoder() >>> le.fit([1, 2, 2, 6]) LabelEncoder() >>> le.classes_ array([1, 2, 6]) >>> le.transform([1, 1, 2, 6]) #doctest: +ELLIPSIS array([0, 0, 1, 2]...) >>> le.inverse_transform([0, 0, 1, 2]) array([1, 1, 2, 6]) It can also be used to transform non-numerical labels (as long as they are hashable and comparable) to numerical labels. >>> le = preprocessing.LabelEncoder() >>> le.fit(["paris", "paris", "tokyo", "amsterdam"]) LabelEncoder() >>> list(le.classes_) ['amsterdam', 'paris', 'tokyo'] >>> le.transform(["tokyo", "tokyo", "paris"]) #doctest: +ELLIPSIS array([2, 2, 1]...) >>> list(le.inverse_transform([2, 2, 1])) ['tokyo', 'tokyo', 'paris']
-
下面引入scikit learn中的OneHotEncoder的介绍。
一、One-Hot Encoding
One-Hot编码,又称为一位有效编码,主要是采用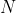 位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
位状态寄存器来对个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
有如下三个特征属性:
二、One-Hot Encoding的处理方法
三、实际的Python代码
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
- 性别:["male","female"]
- 地区:["Europe","US","Asia"]
- 浏览器:["Firefox","Chrome","Safari","Internet Explorer"]
对于某一个样本,如["male","US","Internet Explorer"],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是4维的,这样,我们可以采用One-Hot编码的方式对上述的样本“["male","US","Internet Explorer"]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。