一、组合数据类型container objects

组合数据类型container objects:能够表示多个数据的类型
集合类型:集合类型是一个元素集合,元素无序不重不变
序列类型:序列类型是一个元素向量,元素有序可重可变可不变。序列类型的典型代表是列表类型、元组类型、字符串类型(但元组一旦定义,元素就不能变了)
映射类型:映射类型是“键-值”数据项的组合,元素无序不重键不可变值可变可不变,每个元素是一个键值对。映射类型的典型代表是字典类型
集合类型是一个具体的数据类型名称,而序列类型和映射类型是一类数据类型的总称。
不可变数据类型:immutable,如数字、元组、字符串
可变数据类型:mutable,如列表、集合、字典
可迭代对象:iterable,如range()、序列(列表元组字符串)、集合、字典、文件,generator
不可迭代对象:如数字
很多函数的参数以及返回值都是iterable:map(), filter() ,zip() ,range(), dict.keys(), dict.items() 和 dict.values()
二、(不)可变数据类型immutable
Python中:
- 不可变数据类型:immutable,如数字、元组、字符串
- 可变数据类型:mutable,如列表、集合、字典
- 可以使用id()的进行查看(id()用来返回数据的内存地址)
- 可变和不可变说的是变量的值和变量引用的内存地址
- 不可变数据类型,变量值变化,变量引用地址就会变化,即该地址的值不变
- 可变数据类型,变量值变化,变量引用地址不变,即该地址的值可变
- 不可变数据类型

-
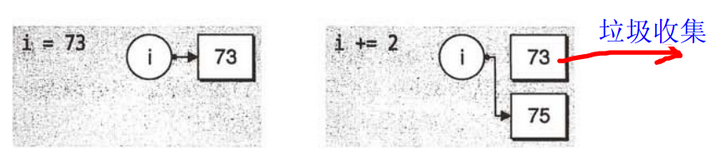
可以看出:无论是直接赋值还是变量赋值,数字的内存地址都不变。a,b,c这些变量,只要是在引用同一个对象,那么它们的内存地址就都是这个对象的内存地址,内存地址是不变的,程序只会记录有多少引用。只有当它们引用其他对象 2 后,它们的内存地址才会指向新的内存地址(新对象的内存地址)那么此时 1的内存地址会被垃圾器回收。无论有多少个变量引用一个对象,内存地址都不会发生改变,只有在重新赋值后内存地址才会发生改变。
-
不可变数据类型的优点就是内存中不管有多少个引用,相同的对象只占用了一块内存,这样可以节省存储空间同时提高计算速度。但是它的缺点就是当需要对变量进行运算从而改变变量引用的对象的值时,由于是不可变的数据类型,所以必须创建新的对象,这样就会使得一次次的改变创建了一个个新的内存地址,占用内存,为了避免这一缺点,不再使用的内存会被垃圾回收器回收。
- 不可变数据类型

- 给变量ls赋值了一个list,再把同样的值赋给ls,内存地址发生了改变,其实第一次赋值和第二次赋值的[1,2,3,4,5],[1,2,3,4,5]它们不是同一个对象,它们只是值相同的两个list,也就是说程序给ls创建了两个值一样的不同对象。

- 对ls进行append()等操作,它都是原来的那个list,它的内存地址没有发生改变,只是它的值发生了改变。反过来说,因为list是可变数据类型,只是同一个list的值变了,内存地址并不会改变
三、(不)可迭代对象iterable

iterable:可迭代的,可遍历的
- 可迭代对象:iterable,如range()、序列(列表元祖字符串)、集合、字典、文件
- 不可迭代对象:如数字
- 可迭代对象包含迭代器。
- 如果一个对象拥有__iter__方法,其是可迭代对象;如果一个对象拥有next方法,其是迭代器。
- 定义可迭代对象,必须实现__iter__方法;定义迭代器,必须实现__iter__和next方法
- 具有yield关键字的函数都是生成器,yield可以理解为return,返回后面的值给调用者。不同的是return返回后,函数会释放,而生成器则不会。
- dir() 返回该对象所拥有的方法名
- 遍历生成器的方法是next(生成器),而不是生成器.next()
- 迭代器是一个实现了迭代器协议的对象,Python中的迭代器协议就是有next方法的对象会前进到下一结果,而到一系列结果的末尾,则会引发StopIteration。任何这类的对象在Python中都可以用for循环或其他遍历工具迭代,迭代工具内部会在每次迭代时调用next方法,并且捕捉StopIteration异常来确定何时离开。
for i in iterable: # 最常见的迭代,for语句
func(i)
(一)为什么要用迭代器iterator
迭代器一个显而易见的好处就是:每次只从对象中读取一条数据,不会造成内存的过大开销。
比如要逐行读取一个文件的内容,利用readlines()方法,我们可以这么写:
for line in open("test.txt").readlines():
print line
这样虽然可以工作,但不是最好的方法。因为他实际上是把文件一次加载到内存中,然后逐行打印。当文件很大时,这个方法的内存开销就很大了。
利用file的迭代器,我们可以这样写:
for line in open("test.txt"): #use file iterators
print line
这是最简单也是运行速度最快的写法,他并没显式的读取文件,而是利用迭代器每次读取下一行。
(二)迭代器协议:生成迭代器iter()方法、使用迭代器next()方法
实现iterator需要两个方法,这两个方法一起被称之为迭代器协议(iterator protocol)。
- 第一个方法是iter()方法,这个方法返回的是实现迭代器的这个类自身,<class_iterator> 。
第二个方法是next()方法,这个方法返回的是容器中的下个元素,如果没有更多的元素了,则会raise一个StopIteration异常。 - dir()可以返回一个对象的所有方法,方法里包含__iter__即该对象可迭代,__iter__方法返回一个迭代器
- 下面例子用dir()列出a的所有方法,里面有__iter__,next,使用next()方法访问下一个元素,直到迭代器越界抛出StopIteration异常
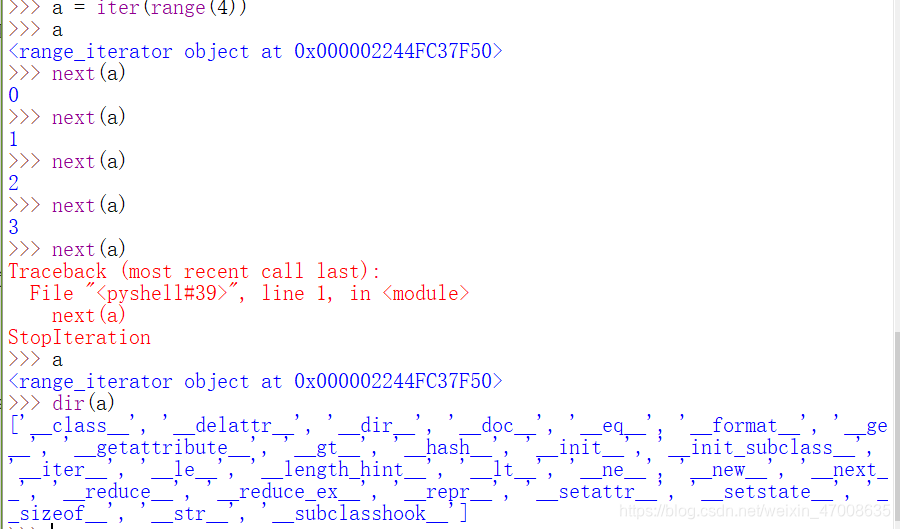
a = iter(range(5))
try:
while True:
value = next(a)
print(value, type(a))
except StopIteration:
pass
输出:
0 <class 'range_iterator'>
1 <class 'range_iterator'>
2 <class 'range_iterator'>
3 <class 'range_iterator'>
4 <class 'range_iterator'>

iter(),两种用法:①容器数据类型本身即是迭代器

next()方法:
- 当generator function被调用的时候,这个函数会返回一个generator对象之后什么都不做。
- 当next方法被调用的时候,函数就会开始执行直到yield所在的位置,计算出来的值在这个位置被返回,之后这个函数就停下了。之后再调用next方法的时候,函数继续执行,直到遇到下一个yield。
- 如果执行完的代码,还没有遇到yield,就会抛出StopIteration异常。
四、生成器generator
(一)什么是生成器
简单讲,生成器generator是一个生成迭代器iterator的函数。
生成器函数在Python中与迭代器协议的概念联系在一起。简而言之,**包含yield语句的函数会被特地编译成生成器。当函数被调用时,他们返回一个生成器对象,这个对象支持迭代器接口。**函数也许会有个return语句,但它的作用是用来yield产生值的。
(二)为什么要使用生成器
Python使用生成器对延迟操作提供了支持。所谓的延迟操作,是指在需要的时候才产生结果,而不是立即产生结果。所以生成器也有了如下的好处:
- 1、节省内存资源消耗,和声明序列不同的是生成器在不使用的时候几乎不占内存,也没有声明计算过程!
- 2、使用的时候,生成器是随用随生成,用完即刻释放,非常高效!
- 3、可在单线程下实现并发运算处理效果。
import memory_profiler as mem
nums = [1, 2, 3, 4]
a = 1000000000
nums2 = (n*n*a for n in nums)
print("生成器,消耗内存:{}".format(mem.memory_usage()))
nums3 = [n*n*a for n in nums]
print("推导式,消耗内存:{}".format(mem.memory_usage()))
输出;
生成器,消耗内存:[18.87890625] # 生成器生成一个迭代器,按需产生,不会一次性生成而占用内存
推导式,消耗内存:[18.8984375] # 推导式在内存中实实在在地生成n个数放在内存里面
(三)如何使用生成器
yield 的作用就是把一个普通函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fib(10) 不会执行 fib 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fib 函数内部的代码,执行到 yield b 时,fib 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。
# Fibonacci.py
a, b = 0, 1
while a < 10: # 使用循环,每循环一次输出一个结果
print(a, end=",")
a, b = b, a + b
输出:0,1,1,2,3,5,8,
# fibonacciV3.py
n, a, b = 0, 0, 1
def fib(nums): # 该函数通过yield关键字来返回结果,每一次迭代就停止于yield语句处,一直到下一次迭代。
global n, a, b
while n < nums:
yield b
a, b = b, a + b
n = n + 1
for num in fib(10):
print(num, n, a, b, type(fib(10))
输出:
1 0 0 1 <class 'generator'>
1 1 1 1 <class 'generator'>
2 2 1 2 <class 'generator'>
3 3 2 3 <class 'generator'>
5 4 3 5 <class 'generator'>
8 5 5 8 <class 'generator'>
13 6 8 13 <class 'generator'>
21 7 13 21 <class 'generator'>
34 8 21 34 <class 'generator'>
55 9 34 55 <class 'generator'>
比较yield和return:
- yield和return都有返回值的功能
- return相当于一根筋地都算出来,然后一股脑给你
- yield每次执行到yield就返回一个,但程序并没有结束,如果调用next,就从上一个yield继续执行,执行到yield就再返回
- yield可用来实现协程
a = 10
def cal_nums(nums):
for n in nums:
if n % 3 == 0:
return 3 * a
elif n % 5 == 0:
return 5 * a
else:
return n
def gen_nums(nums):
for n in nums:
if n % 3 == 0:
yield 3 * a
elif n % 5 == 0:
yield 5 *a
else:
yield n
nums = [1,2,3,4]
gnums = gen_nums(nums)
print(gnums) # 可以看到gnums是一个generator
for n in gnums:
print(n)
输出:
<generator object gen_nums at 0x0000019619A74048>
1
2
30
4
五、链接:语法糖,迭代思想在Python中的应用
知乎:Python 有哪些好玩的语法糖?
在tutorial里面有这么一句话The use of iterators pervades and unifies Python.
基本上来说迭代的思想在Python这门语言的实现过程中已经渗透在各个角落,已经是底层的设计思想了,很多语法都是基于迭代这个概念向上建造的。以下是一些例子
很多容器类型都是iterable
甚至文件类型都是可以用for语句来访问的。我们最常用的一个数据结构list,它是用iterable作为参数来初始化一个list,其实执行了这样的初始化函数
class list(object):
...
def __init__(self, iterable):
for i in iterable:
self.value.append(i)
...
很多函数的参数以及返回值都是iterable
map(), filter() ,zip() ,range()
dict.keys(), dict.items() 和 dict.values()
for其实也是语法糖
基于迭代的语法糖
比如:
for i in iterable:
func(i)
本质上是:
z = iter(iterable)
try:
while True:
func(next(z))
except StopIteration:
pass
unpack也是语法糖
比如:
>>> a,b = b,a # 等价于 a,b = (b,a)
>>> a,b,*_ = [1,2.3,4] # 仅适用于 Python 3
>>> a,b,*_ = iter([1,2.3,4]) # 也可以用于迭代器
>>> a
1
>>> b
2.3
>>> _
[4]
list comperhension也是语法糖
上面虽然说generator experssion是生成器版本的list comperhension,这只是为了便于理解,其实先后顺序应该颠倒过来。
List Comprehension 也只是语法糖而已,甚至还可以写出 tuple/set/dict comprehension(其实 set 就是所有 key 的 value 都为 None 的 dict)
>>> [x*x for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> list(x*x for x in range(10))
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> tuple(x*x for x in range(10))
(0, 1, 4, 9, 16, 25, 36, 49, 64, 81)
>>> set(x*x for x in range(10))
{
0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
>>> dict((x,x*x) for x in range(10))
{
0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
PS: source python123.io, CSDN