需求
根据uid分组,比较用户的登陆时长,并选出第一次登陆的时间,最后一次登陆的时间,及登陆的次数,两次登陆间隔不操过30分钟的,算一次登陆,写出对应的SQL语句……
表结构
CREATE TABLE `t_ods` (
`id` bigint(11) NOT NULL,
`uid` int(11) DEFAULT NULL,
`login_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;做数据脚本
DELIMITER ;
CREATE PROCEDURE test_insert()
BEGIN
DECLARE y BIGINT DEFAULT 138;
DECLARE h BIGINT DEFAULT 13;
DECLARE m BIGINT DEFAULT 50;
WHILE y<1000
DO
set h = RAND() * 500%24;
set m = RAND() * 10000%60;
INSERT INTO t_ods(`id`, `uid`, `login_time`)
VALUES (y, FLOOR( 1 + RAND() * 5), CONCAT('2019-',CAST(y%12 AS CHAR),'-07 ',CAST(h AS CHAR),':',CAST(m AS CHAR),':',CAST(y%60 AS CHAR)) );
SET y=y+1;
END WHILE ;
COMMIT;
END;
CALL test_insert();
DROP PROCEDURE IF EXISTS test_insert;生成的数据有862

解题
关键点是,两次登陆间隔不操过30分钟的,需要计算在同一个mysql表中第一个时间与第二个时间比较,第二个时间与第三个时间比较……依次类推……
首先查看有多少UID
SELECT UID from t_ods group by uid
选择其中一个UID,进行升序排列结果集
select id ,uid,login_time from t_ods where uid = 3 and login_time like '2019-10-0%' order by login_time计算在同一个mysql表中第一个时间与第二个时间比较,第二个时间与第三个时间比较
SELECT
b.id,
b.uid,
b.curr,
b.pre,
TIMESTAMPDIFF(MINUTE,b.pre, b.curr) AS diff
FROM
(
SELECT
a.`id` AS id,
a.`uid` AS uid,
a.`login_time` AS curr,
@a.login_time AS pre,
@a.login_time:= a.login_time
FROM t_ods a,(SELECT @a.login_time:=0)r where uid = 3 and login_time like '2019-10-07%' order by login_time asc
)b
这样就实现了同一个uid,在一张表,不同时间段的逐级差值,然后,再根据diff ,进行判断是否大于30,即可实现需求功能 !
总结
用到了一下sql知识:
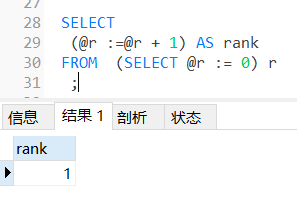
伪列为分组排名
Mysql中因为没有ROWNUM伪列、那么想要排名、故要搞出一列伪列、用作排名
SELECT
(@r :=@r + 1) AS rank
FROM (SELECT @r := 0) r
;
SELECT
a.`id` AS id,
a.`name` AS NAME,
a.`login_time` AS curr,
@a.login_time AS pre, --上一条记录的login_time值
@a.login_time:= a.login_time AS tmp
FROM stock_store_addinfo a,(SELECT @a.login_time:=0)s
@a.login_time:=a.login_time AS tmp --将a.login_time值赋到临时临时变量 @a.login_time
SELECT @a.login_time:=0 --选择当前表,上一条记录 a.login_time,默认值为0时间差函数(TIMESTAMPDIFF、DATEDIFF)
需要用MySQL计算时间差,使用TIMESTAMPDIFF、DATEDIFF,记录一下实验结果
--0
select datediff(now(), now());
--2
select datediff('2015-04-22 23:59:00', '2015-04-20 00:00:00');
--2
select datediff('2015-04-22 00:00:00', '2015-04-20 23:59:00');
--1
select TIMESTAMPDIFF(DAY, '2015-04-20 23:59:00', '2015-04-22 00:00:00');
--2
select TIMESTAMPDIFF(DAY, '2015-04-20 00:00:00', '2015-04-22 00:00:00');
--2
select TIMESTAMPDIFF(DAY, '2015-04-20 00:00:00', '2015-04-22 12:00:00');
--2
select TIMESTAMPDIFF(DAY, '2015-04-20 00:00:00', '2015-04-22 23:59:00');
--71
select TIMESTAMPDIFF(HOUR, '2015-04-20 00:00:00', '2015-04-22 23:00:00');
--4260
select TIMESTAMPDIFF(MINUTE, '2015-04-20 00:00:00', '2015-04-22 23:00:00');DATETIME类型和Timestamp之间的转换
DATETIME -> Timestamp:
UNIX_TIMESTAMP(...)
Timestamp -> DATETIME:
FROM_UNIXTIME(...)
mysql> SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(NOW()));
+--------------------------------------+
| FROM_UNIXTIME(UNIX_TIMESTAMP(NOW())) |
+--------------------------------------+
| 2021-03-17 16:27:41 |
+--------------------------------------+细品mysql count和sum的区别
CREATE TABLE `sigterm` (
`name` varchar(20) default NULL,
`subject` varchar(20) default NULL,
`score` tinyint(4) default NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8
insert into sigterm values
('张三','数学',90),
('张三','语文',50),
('张三','地理',40),
('李四','语文',55),
('李四','政治',45),
('王五','政治',30),
('赵六','语文',100),
('赵六','数学',99),
('赵六','品德',98)sum()函数
sum()函数里面的参数,是列名的时候,是计算列名的值的相加,而不是有值项的总数。
select name,sum(score < 60) ,avg(score) from sigterm group by name having sum(score<60) >=2;
里面涉及到sum、avg所以要使用group by ,其中sum(score < 60)是不是很突兀?
select name,(score < 60) from result
count()函数
count()函数里面的参数,是列名的的时候,那么会计算有值项的次数。字段没有值的项并不会进入计算范围,建议大家使用count(*),而避免使用指定具体的列名。
select name ,count((score<60)!=0) as a,avg(score) from result group by name having a >=2; 
这个对score进行进行计算是错误的,count(a)与count(*)都是求行数,只对存在的"列名"的行数求和,总之与group by having不是一对。