题目描述
剑指 Offer 07. 重建二叉树
难度中等
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
限制:
0 <= 节点个数 <= 5000
注意:本题与主站 105 题重复:https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
二叉树的节点的定义如下:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
TreeNode(){
}
}
测试用例
- 普通二叉树(完全二叉树;不完全二叉树)
- 特殊二叉树(所有节点都没有右子节点的二叉树;所有节点都没有左子节点的二叉树;只有一个节点的二叉树)
- 特殊输入测试(二叉树的根节点为空;输入的前序序列和中序序列不匹配)
题目考点
- 考察应聘者对二叉树的前序遍历和中序遍历的理解程序。只有对二叉树的不同遍历算法有了深刻的理解,应聘者才有可能在遍历序列汇总划分出左、右子数对应的子序列。
- 考察应聘者分析复杂问题的能力。我们把构建二叉树的大问题分解成构建左、右子树的两个小问题。我们发现小问题和大问题在本质上是一致的,因此可以用递归的方式解决。
解题思路
前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。接下来的事情我们就可以用 递归 的方法完成了。
前序遍历性质: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序。
中序遍历性质: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序。
以题目示例为例:
- 前序遍历划分
[ 3 | 9 | 20 15 7 ]- 中序遍历划分
[ 9 | 3 | 15 20 7 ]
根据以上性质,可得出以下推论:
- 前序遍历的首元素 为 树的根节点
node的值。 - 在中序遍历中搜索根节点
node的索引 ,可将 中序遍历 划分为[ 左子树 | 根节点 | 右子树 ]。 - 根据中序遍历中的左 / 右子树的节点数量,可将 前序遍历 划分为
[ 根节点 | 左子树 | 右子树 ]。
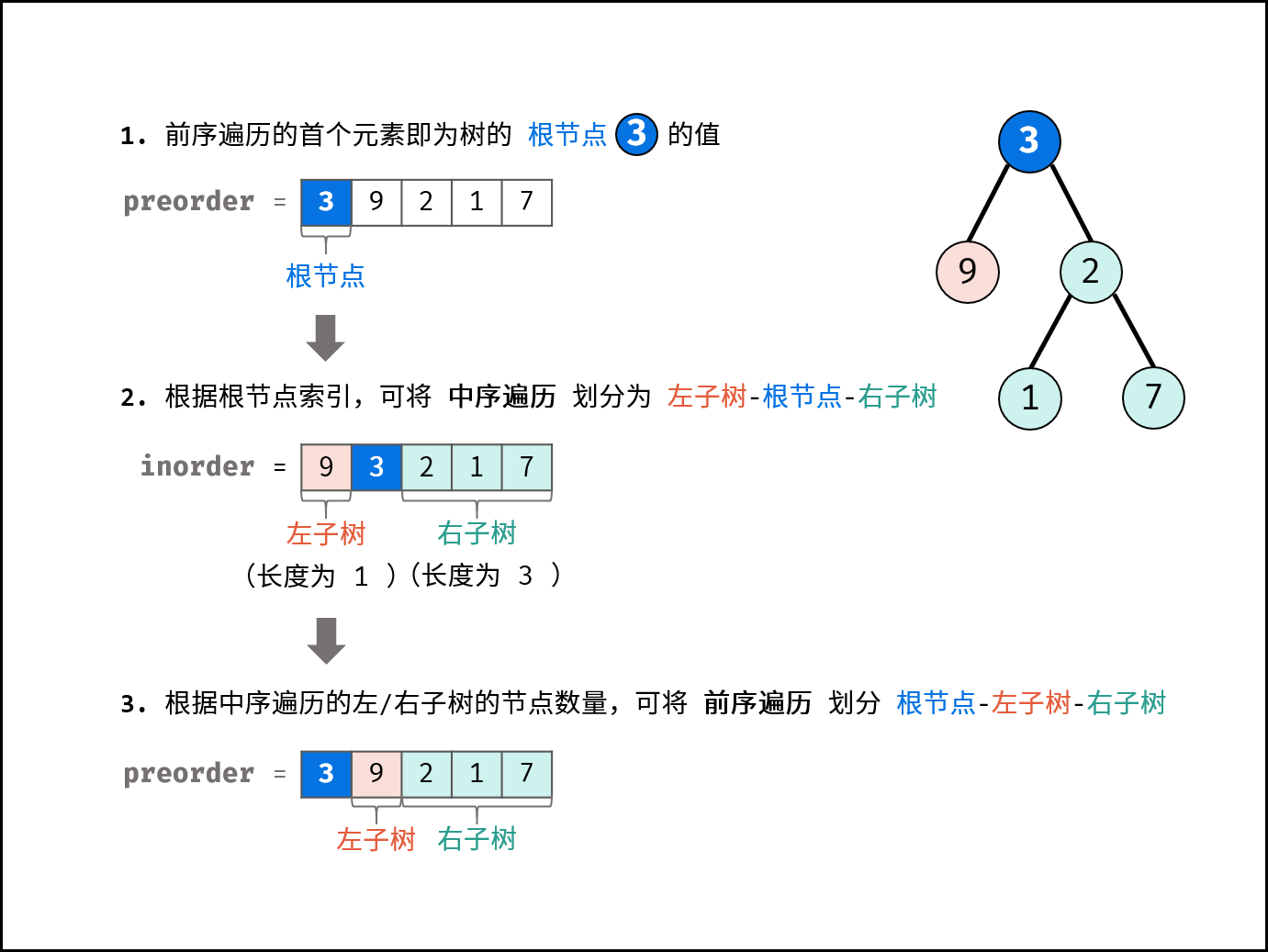
通过以上三步,可确定 三个节点 :1.树的根节点、2.左子树根节点、3.右子树根节点。
对于树的左、右子树,仍可使用以上步骤划分子树的左右子树。
以上子树的递推性质是 分治算法 的体现,考虑通过递归对所有子树进行划分。
分治算法解析:
-
递推参数: 根节点在前序遍历的索引
root、子树在中序遍历的左边界left、子树在中序遍历的右边界right; -
终止条件: 当
left > right,代表已经越过叶节点,此时返回 nullnul**l ; -
递推工作:
- 建立根节点
node: 节点值为preorder[root]; - 划分左右子树: 查找根节点在中序遍历
inorder中的索引i;
为了提升效率,本文使用哈希表
dic存储中序遍历的值与索引的映射,查找操作的时间复杂度为 O(1)O(1)- 构建左右子树: 开启左右子树递归;
根节点索引 中序遍历左边界 中序遍历右边界 左子树 root + 1lefti - 1右子树 i - left + root + 1i + 1righti - left + root + 1含义为根节点索引 + 左子树长度 + 1 - 建立根节点
-
返回值: 回溯返回
node,作为上一层递归中根节点的左 / 右子节点;
复杂度分析:
- 时间复杂度 O(N): 其中 NN 为树的节点数量。初始化 HashMap 需遍历
inorder,占用 O(N)。递归共建立 NN 个节点,每层递归中的节点建立、搜索操作占用 O(1)O(1) ,因此使用 O(N) 时间。 - 空间复杂度 O(N): HashMap 使用 O(N) 额外空间。最差情况下,树退化为链表,递归深度达到 N ,占用 O(N) 额外空间;最好情况下,树为满二叉树,递归深度为 logN ,占用 O(logN) 额外空间。
代码:
注意:本文方法只适用于 “无重复节点值” 的二叉树。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
HashMap<Integer, Integer> map = new HashMap<>();//标记中序遍历
int[] preorder;//保留的先序遍历,方便递归时依据索引查看先序遍历的值
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
//将中序遍历的值及索引放在map中,方便递归时获取左子树与右子树的数量及其根的索引
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
//三个索引分别为
//当前根的的索引
//递归树的左边界,即数组左边界
//递归树的右边界,即数组右边界
return recur(0,0,inorder.length-1);
}
TreeNode recur(int pre_root, int in_left, int in_right){
if(in_left > in_right) return null;// 相等的话就是自己
TreeNode root = new TreeNode(preorder[pre_root]);//获取root节点
int idx = map.get(preorder[pre_root]);//获取在中序遍历中根节点所在索引,以方便获取左子树的数量
//左子树的根的索引为先序中的根节点+1
//递归左子树的左边界为原来的中序in_left
//递归右子树的右边界为中序中的根节点索引-1
root.left = recur(pre_root+1, in_left, idx-1);
//右子树的根的索引为先序中的 当前根位置 + 左子树的数量 + 1
//递归右子树的左边界为中序中当前根节点+1
//递归右子树的有边界为中序中原来右子树的边界
root.right = recur(pre_root + (idx - in_left) + 1, idx+1, in_right);
return root;
}
}